
- 1 中小企業がAI導入で失敗しないための社内データ整備 実践ロードマップ
- 2 はじめに:成果が出ないAI導入、9割の共通点は「データ準備」にあった
- 3 第1章 基礎理解:なぜ「社内データ整備」がAIの成果を左右するのか?
- 4 第2章 AI導入プロジェクトの全体像:迷わず進める7ステップ
- 5 第3章 まずは羅針盤と地図を固める(ステップ1~3)
- 6 第4章 プロジェクトの成否を分ける「社内データ整備」の実務(ステップ4)
- 7 第5章 PoCを「試す場」から「判断の場」へ変える(ステップ5)
- 8 第6章 本格導入と「育て続ける」運用体制の構築(ステップ6)
- 9 第7章 効果測定と継続的な改善(ステップ7)
- 10 第8章 【ユースケース別】必要なデータと整備の勘所
- 11 第9章 実例から学ぶ:AI導入、成功と失敗の分岐点
- 12 第10章 【明日から使える】AI導入準備セルフチェックリスト
- 13 第11章 人と仕組み:AIを使いこなすためのリテラシー向上とガバナンス設計
- 14 第12章 FAQ(よくある質問)
- 15 まとめ:AI導入成功の鍵は、テクノロジーではなく「準備」と「仕組み」にある
中小企業がAI導入で失敗しないための社内データ整備 実践ロードマップ
はじめに:成果が出ないAI導入、9割の共通点は「データ準備」にあった
「AIや生成AIを導入すれば、業務が劇的に効率化するはずだ」――。そんな期待を胸に多額の投資をしたものの、「期待したほどの成果が出ない」「実証実験(PoC)から先に進めない」という壁に直面する中小企業は少なくありません。ある国内調査では、生成AIを導入した企業の約4割が成果を実感できていないというデータもあります。
なぜ、これほど強力なツールが宝の持ち腐れになってしまうのでしょうか。その原因は、突き詰めると3つに集約されます。
- 目的の曖昧さ: 「何のためにAIを使うのか」が不明確。
- 運用体制の不備: AIを育て、管理する仕組み(LLMOps)がない。
- 社内データの未整備: AIが学習・参照するための「教科書」がボロボロの状態。
特に深刻なのが3つ目の「社内データの未整備」です。AIは魔法の杖ではありません。質の高いデータという燃料があって初めて、その能力を最大限に発揮できるエンジンなのです。ゴミを入れればゴミが出てくる「Garbage In, Garbage Out」の原則は、AIの世界でこそよりシビアに適用されます。
限られた人員と予算の中で、データ準備から運用までを最小コストでどう軌道に乗せるか。これこそが、中小企業のAI導入における成功と失敗の最大の分岐点と言えるでしょう。
本記事では、AI導入プロジェクトを7つのステップに分解し、特に成否を分ける「社内データ整備」に焦点を当てて、実務でそのまま使える具体的な手順、チェックリスト、評価指標まで徹底的に解説します。この記事を読み終える頃には、あなたの会社で明日から着手できる、現実的で失敗しないAI導入の実行計画が手に入っているはずです。
この記事を読んで得られること(60秒でわかる要点)
- AI導入の全体像がわかる: 「目標設定」から「効果測定・改善」まで、迷わず進められる7ステップのロードマップを提示します。
- 失敗しないデータ準備の要点がわかる: データの棚卸し、分類、品質改善、アクセス制御、監査、更新運用という6つの核心的な作業を、具体的な手順で解説します。
- 潜在リスクとその対策がわかる: 情報漏洩、著作権侵害、ハルシネーション(AIの嘘)、ベンダーロックインといった避けて通れないリスクに対し、初期段階で打つべき具体的な対策を学びます。
- PoCを成功させるコツがわかる: 「小さく作って厳しく測る」を鉄則に、KPIの事前定義から、導入可否を判断する「合格基準」の設定方法までを具体化します。
- 社員のリテラシー向上策がわかる: 入力禁止情報、出力結果の検証方法、レビュー手順など、全社で徹底すべきルールを定着させるための研修・ガイドラインのポイントを解説します。
第1章 基礎理解:なぜ「社内データ整備」がAIの成果を左右するのか?
AI導入プロジェクトが頓挫する根本原因は、技術的な問題よりも、むしろ組織的な準備不足にあります。「なんとなく便利そう」という曖昧な動機で高機能なツールを導入しても、現場の業務プロセスやデータと噛み合わなければ、成果が出るはずもありません。
AI導入プロジェクトが陥る典型的な失敗パターン
- PoC(実証実験)で止まる: 限定的なデータでは上手くいったが、対象を広げた途端に精度が低下し、本格導入を断念する。
- 現場に定着しない: AIの回答精度が低かったり、使い方が複雑だったりして、結局「人間がやった方が早い」と敬遠される。
- 品質・コンプライアンス問題が噴出: AIが古い情報や誤った情報をもっともらしく回答し、顧客対応や意思決定でトラブルが発生する。
これらの失敗の根底には、ほぼ例外なく「データの問題」が潜んでいます。AIにとってデータは、思考の土台となる知識そのものです。その知識が整理されておらず、古く、誤りが多ければ、AIが賢くなるはずがないのです。
AI導入で直面する4大リスクと初期対策の重要性
データ整備を怠ると、業務効率化が実現できないだけでなく、深刻な経営リスクを引き起こす可能性があります。計画の初期段階から、以下の4つのリスクを認識し、対策を織り込むことが不可欠です。
- 情報漏洩リスク:
海外では、従業員が機密情報や顧客情報を安易に外部の生成AIサービスに入力し、そのデータが外部サーバーに記録・学習されてしまうインシデントが発生しました。初期段階で「AIに入力してはいけない情報」を明確に定義し、技術的・組織的な監査の仕組みを設けることが、信頼を守る上で絶対条件となります。 - 著作権侵害リスク:
AIが学習データに含まれる著作物を無断で利用したり、生成物が第三者の著作権を侵害したりするリスクです。海外では、大手メディア企業がAI事業者に対し、自社の記事データを無断で学習に使用されたとして訴訟を起こす事例も出ています。社内文書だけでなく、外部コンテンツを扱う際のルールを明確化しておく必要があります。 - ハルシネーション(もっともらしい嘘)のリスク:
AIは、事実に基づかない情報を、あたかも事実であるかのように生成することがあります。これをハルシネーションと呼びます。AIの回答を鵜呑みにして社外に発信したり、重要な経営判断に利用したりすれば、企業の信頼性を著しく損なう恐れがあります。AIの出力はあくまで「下書き」と位置づけ、人間によるファクトチェックとレビューのプロセスを必ず組み込まなければなりません。 - ベンダーロックインのリスク:
特定のAIベンダーのサービスに深く依存してしまうと、将来的に料金が値上がりしたり、サービスが終了したりした際に、他のサービスへ乗り換えることが困難になります。データやプロンプト(AIへの指示文)といった知的資産を自社で管理し、特定のベンダーに依存しない設計を心がけることが、長期的な視点で重要です。
無視できない法規制の動向
EUでは包括的な「AI法」の整備が進み、日本国内でも政府が「AI事業者ガイドライン」を策定するなど、AIの利用に関するルール作りが世界的に加速しています。コンプライアンスとガバナンスの視点は、もはや「あれば良い」ものではなく、計画の初期段階から組み込むべき必須要件となっています。
第2章 AI導入プロジェクトの全体像:迷わず進める7ステップ
AI導入は、思いつきで進められるものではありません。明確な目的意識のもと、計画的にステップを踏んでいくことが成功への最短ルートです。ここでは、標準的なAI導入プロセスを7つのステップに分けて概観します。
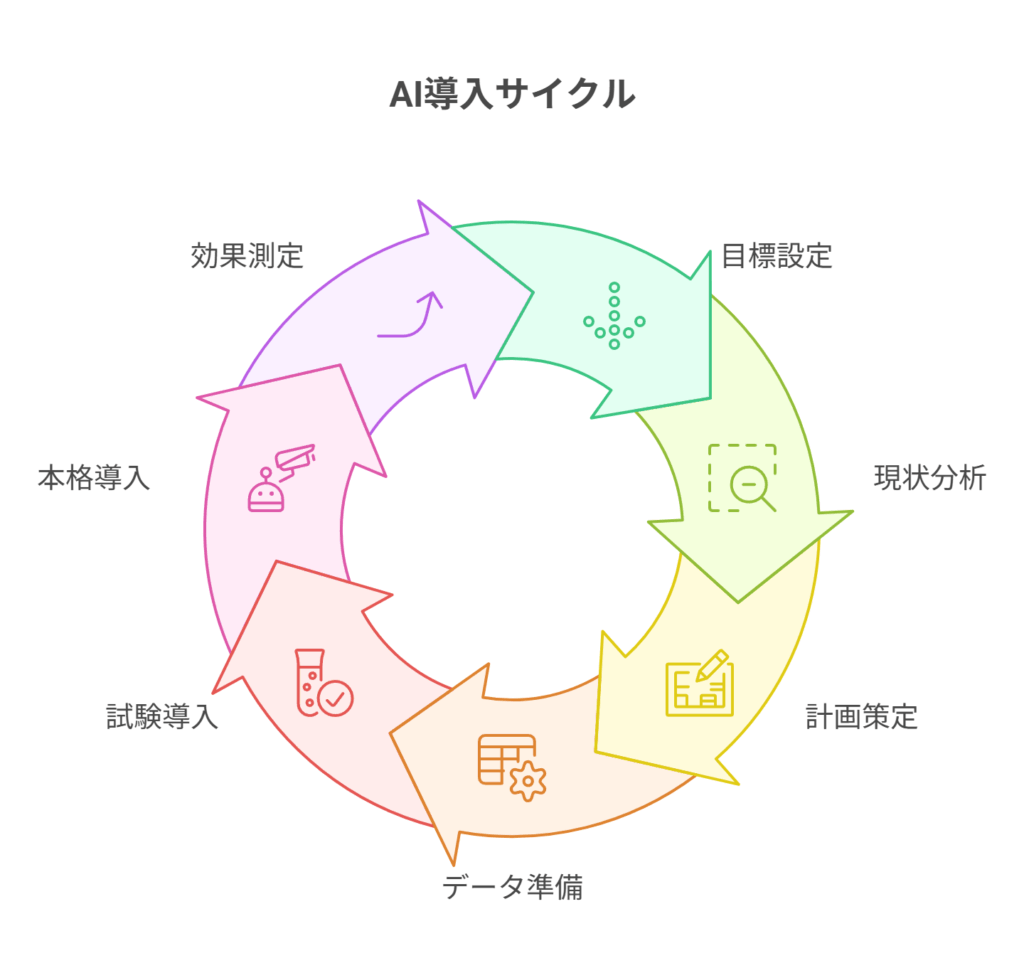
- 目標設定:
「何のためにAIを導入するのか」を具体的に定義します。業務課題と、達成すべき数値目標(KPI)を明確にします。 - 現状分析:
対象業務の現在のプロセス、利用されているデータ、既存のルールなどを洗い出し、課題を整理します。 - 計画策定:
目標達成のための具体的な計画を立てます。対象範囲、役割分担、予算、スケジュール、そしてPoCの合格基準を文書化します。 - データ準備:
AIが利用する社内データを収集、整理、クレンジングし、品質を高めます。本記事で最も重点的に解説する、プロジェクトの成否を分ける最重要ステップです。 - 試験導入(PoC):
限定された範囲でAIシステムを構築し、事前に定めたKPIや合格基準をクリアできるか検証します。 - 本格導入と運用:
PoCの結果を踏まえ、全社または対象部署へ展開します。継続的にAIを運用・改善していくための体制を構築します。 - 効果測定と改善:
導入後も定期的に効果を測定し、目標(KPI)の達成度を確認します。結果を分析し、データやプロンプト、業務プロセスの改善を繰り返します。
本記事では、この7ステップの中でも、特に中小企業がつまずきやすく、かつ成果に直結する「ステップ4:データ準備」を、誰でも実践できるレベルまで掘り下げて解説していきます。
第3章 まずは羅針盤と地図を固める(ステップ1~3)
データという大海原に乗り出す前に、航海の「目的」と「現在地」、そして「ルート」を明確にする必要があります。これがステップ1~3の役割です。ここを疎かにすると、プロジェクトは確実に漂流します。
ステップ1:目標設定 ― 「何となく」からの脱却
AI導入の目的は「AIを使うこと」ではありません。「AIを使って、何の業務課題を、どれくらい改善するのか」を、計測可能な言葉で定義することがスタートです。
良い目標設定の例:
- カスタマーサポート部門:
- 課題: 問い合わせ対応に時間がかかり、顧客満足度が伸び悩んでいる。
- 目標: AIチャットボットを導入し、定型的な問い合わせを自動化することで、1件あたりの平均対応時間を50%短縮する。オペレーターは複雑な問い合わせに集中し、顧客満足度スコアを現状維持、または5%向上させる。
- 技術・開発部門:
- 課題: 社内に点在する膨大な技術マニュアルから必要な情報を探すのに時間がかかっている。
- 目標: 社内文書検索AIを導入し、技術者が求める情報に到達するまでの平均検索時間を3分から1分へと短縮する。
ステップ2:現状分析 ― 足元を知る
目標が決まったら、現状を正確に把握します。特に、データに関する以下の点を棚卸しすることが重要です。
- 業務プロセス: 対象業務は、現在どのような手順で、誰が担当しているか?
- データ資産: その業務で使われているデータ(マニュアル、FAQ、顧客台帳など)は、どこに(ファイルサーバー、特定のシステム内)、どのような形式で(Word, Excel, PDF)、誰が管理しているか?
- 既存ルール: 情報セキュリティに関する既存のガイドラインや、文書のレビュー・承認プロセスは存在するか?
ステップ3:計画策定 ― 成功への設計図を描く
目標と現状のギャップを埋めるための具体的な計画を文書にまとめます。この計画書が、プロジェクト全体の道しるべとなります。
計画書に盛り込むべき主要項目:
| 項目 | 内容 |
|---|---|
| 対象業務・スコープ | 今回のプロジェクトで対象とする業務範囲を明確に定義する。(例:○○製品に関する一次問い合わせ対応のみ) |
| 役割分担 | プロジェクト責任者、データ整備担当、レビュー担当など、誰が何に責任を持つかを決める。 |
| 予算・スケジュール | ツール利用料、人件費などを見積もり、マイルストーンを設定する。 |
| KPI・合格基準 | PoCを「成功」と判断するための具体的な数値基準(Go/No-Go基準)を事前に定義する。 |
| リスク管理計画 | 入力禁止情報の定義、レビュー体制、監査ログの取得方法など、リスク対策をあらかじめ定めておく。 |
第4章 プロジェクトの成否を分ける「社内データ整備」の実務(ステップ4)
ここからが本ガイドの核心です。AIという優秀な新入社員に最高のパフォーマンスを発揮してもらうための「社内教科書(データ)」作りに着手します。PoCを始める前に、ここで解説する「最小限のデータ整備」を完了させることが、失敗確率を劇的に下げる鍵となります。
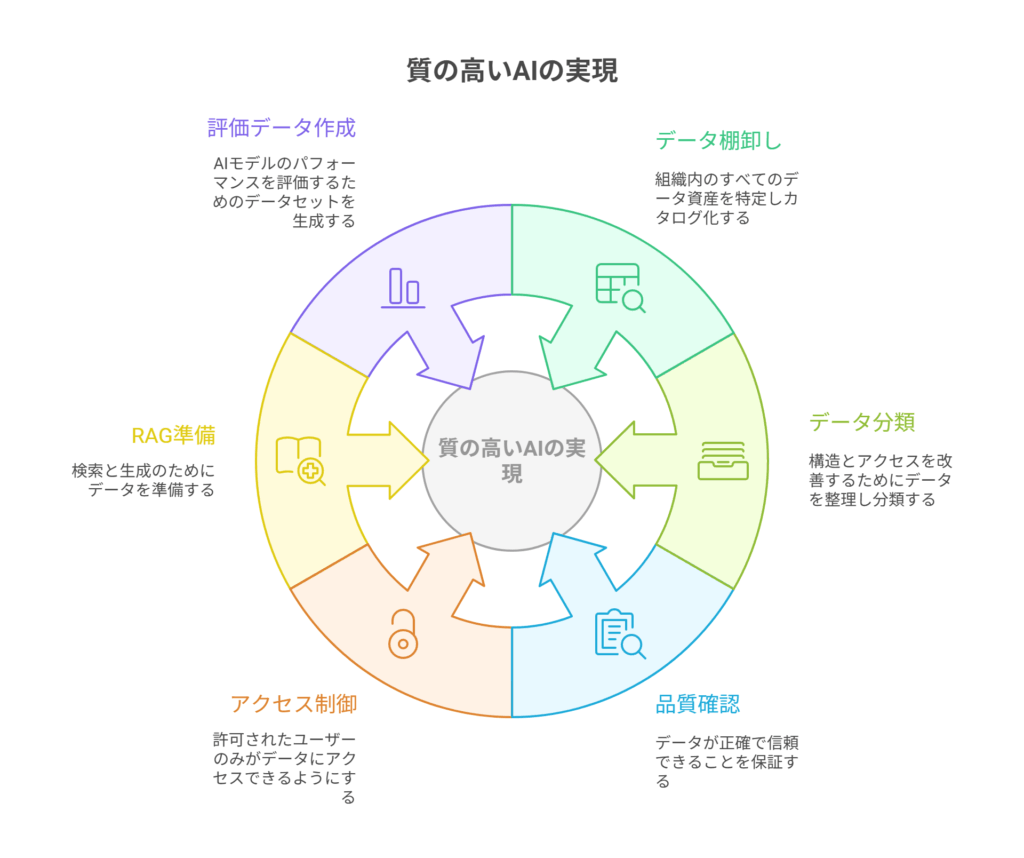
4-1. データ棚卸し(インベントリ作成)― まずは家中のモノを把握する
最初のステップは、AIに学習させたい、あるいは参照させたいデータが、社内のどこに、どのような状態で存在しているかを把握することです。
- 収集対象の例:
- 構造化データ: 形式が整っているデータ(例:顧客台帳、在庫リスト、受注履歴、FAQ管理表など)
- 非構造化データ: テキストや画像が中心の自由形式のデータ(例:業務マニュアル、作業手順書、議事録、過去のメール、仕様書のPDF、製品画像など)
- 把握すべき項目:
- データの所在(どのフォルダ、どのシステムにあるか)
- ファイル形式(Word, Excel, PDF, CSVなど)
- 更新頻度(毎日、毎週、年1回など)
- 作成部署・責任者
- 現在のアクセス権設定
- 機密レベル(感覚的なものでOK)
- 同じようなデータが複数箇所にないか(二重管理の有無)
この作業のアウトプットとして、以下のようなシンプルな「データカタログ」をExcelなどで作成します。完璧を目指す必要はありません。まずは主要なデータからリストアップしていきましょう。
【データカタログ(最小版テンプレート)】
| データ名 | 用途候補 | 機密区分(仮) | 責任部署/担当者 | 最終更新日 | アクセス先(パスなど) | 備考 |
|---|---|---|---|---|---|---|
| ○○製品FAQリスト | 問い合わせ自動応答 | 社内限定 | CS部/佐藤 | 2024/05/10 | ¥¥server¥share¥CS | 定期更新あり |
| △△作業手順書 | マニュアル作成支援 | 機密 | 製造部/鈴木 | 2023/11/20 | … | 第3版が最新 |
| 営業提案書テンプレ | 提案文作成支援 | 機密 | 営業企画部/高橋 | 2024/02/15 | … | 顧客名は削除必須 |
4-2. データ分類 ― 「触って良いモノ」「ダメなモノ」を仕分ける
棚卸ししたデータに「機密度」のラベルを貼り、AIがアクセスして良い範囲を明確にします。これにより、情報漏洩リスクを管理します。中小企業であれば、まずはシンプルな4段階の分類から始めるのが現実的です。
- 推奨される最小分類クラス:
- レベル1:公開可(Webサイト掲載情報、プレスリリースなど、社外に公開済みの資料)
- レベル2:社内限定(全社通達、一般的な社内規程など、一般社員が閲覧可能な資料)
- レベル3:機密(部門内やプロジェクト内でのみ共有される資料、個人情報を含まない顧客情報など)
- レベル4:秘匿(経営情報、人事評価、法務関連の重要情報など、原則AIへの入力が禁止される資料)
実務上の最重要ポイント:
「入力禁止情報」の定義を具体的に明文化し、全社員に周知徹底することです。
入力禁止情報の具体例:
- お客様や取引先の氏名、連絡先、住所などの個人情報
- 未発表の業績予測、価格情報、新製品情報
- 契約書の下書きや、法的な見解に関する機密性の高いやり取り
- 社員の個人情報や人事評価に関する情報
- システムのID、パスワードなどの認証情報
既存の資料に、ファイル名やフォルダ構成でこれらのラベルを付与していきます。判断に迷った場合は、安全側に倒し、一つ上の機密レベルに分類するのが鉄則です。
4-3. 品質確認と整形(クレンジング)― 教科書の誤字脱字を直す
AIは、データが汚れていればいるほど、誤った学習をしてしまいます。大規模なデータクレンジングは専門知識が必要ですが、まずは最低限、以下の点から着手しましょう。
- 重複・旧版の整理:
同じ内容のファイルが複数ある場合、どれが「正」であるかを定義し、最新版のみを残して古いバージョンは別のフォルダに「アーカイブ」します。これにより、AIが古い情報を参照するのを防ぎます。 - ファイル名・見出しの正規化:
ファイル名を「YYYYMMDD_文書種別_タイトル」のような統一ルールで命名するだけでも、人間にとってもAIにとっても検索性が格段に向上します。文書内の見出し(大見出し、中見出しなど)のスタイルを統一することも有効です。 - 文字化け・誤字の修正:
スキャンしただけの画像PDFは、AIがテキストを読み取れません。OCR(光学的文字認識)ツールを使ってテキストデータ化し、検索可能にします。その際、文字化けや誤認識がないか、重要な文書だけでもチェックしましょう。 - メタデータの付与:
ファイルのプロパティに、タイトル、作成者、更新日、関連キーワードなどの「メタデータ」を付与しておくと、AIが文書の文脈を理解する助けになります。
4-4. アクセス制御と監査 ― 金庫の鍵を管理する
データの分類が終わったら、その分類に基づいて「誰が(どのAIが)どのデータにアクセスできるか」を制御する仕組みを整えます。
- 最小構成のアクセス制御:
- ロールベースの権限設定: 従業員の部署や役職に応じて、アクセスできるフォルダやファイルを制限します。これは既存のファイルサーバーの機能でも実現可能です。
- AI利用ルールの策定: 機密区分ごとに「AIへの入力可否」をルール化し、機密レベルの高い情報を扱う場合は上長の承認を必須とするなどのフローを定めます。
- レビュー体制の確立: AIが生成した出力物を、誰が、どのような観点でレビューするかの責任者を明確にします(例:業務担当者による一次レビュー、法務・コンプライアンス部門による二次レビュー)。
- 利用ログの保全: 「いつ、誰が、どのような目的で、何を入力し、どの出力を業務に利用したか」を記録する仕組みを確保します。万が一のインシデント発生時に、原因究明と影響範囲の特定に不可欠です。
4-5. RAG(検索拡張生成)の準備 ― AIに引用元を明記させる
RAG(Retrieval-Augmented Generation)とは、生成AIが回答を生成する際に、社内文書など信頼できる情報源をリアルタイムで検索・参照し、その内容に基づいて回答する技術です。これにより、ハルシネーションを抑制し、回答の根拠を明確にすることができます。
- RAGのための実務ポイント:
- 文書のチャンク化: 長い文書を、意味のある単位(段落、セクション、箇条書きなど)に分割(チャンキング)しておくと、AIが必要な箇所を的確に見つけやすくなります。
- 参照情報の付与: 文書内に、参考となる社内規定のURLや、関連文書のIDを記載しておくと、AIが情報の繋がりを理解しやすくなります。
- プロンプトの標準化: AIへの指示文に「必ず参照した文書名とページ番号を回答の末尾に記載してください」といった一文を標準で加えるようにします。
4-6. 評価用データセットの作成 ― AIの成績を決める「試験問題」作り
AIの性能を客観的に評価するために、「試験問題」と「模範解答」のセットを用意します。これが「評価用データセット」です。これがないと、PoCや導入後の改善が、担当者の感覚頼りになってしまいます。
- 評価データセットの作り方:
- 対象業務でよくある質問や、典型的なタスクを30~100件程度リストアップします。
- それぞれの質問・タスクに対して、期待される「模範解答」や、参照すべき「根拠文書」を紐づけます。
- 難易度やパターンを意図的に混ぜます(例:簡単な定型質問、複数の情報を組み合わせないと答えられない応用質問、意地悪な質問など)。
- このデータセットを使って測定する指標の例:
- 正確性: 模範解答とどれだけ一致しているか。
- 網羅性: 答えるべき要素をすべて含んでいるか。
- 根拠提示率: 回答の根拠となる文書を正しく提示できた割合。
- 再現性: 同じ質問に対して、何度聞いても同じ質の回答が返ってくるか。
4-7. ベンダー依存リスクの低減 ― 資産は自社で守る
特定のAIベンダーにすべてのデータを預けてしまうと、将来の乗り換えが困難になります。自社の競争力の源泉となる資産は、自社で管理・コントロールできる状態を維持しましょう。
- 自社で管理すべき資産:
- プロンプト集: 高い成果を出せた優秀なプロンプト(指示文)は、会社の知的資産です。
- 評価データセット: AIの性能を測るための貴重なベンチマークです。
- クレンジング済みの社内ナレッジ: 整形・整理されたデータそのものが競争力の源泉です。
契約時には、契約終了時のデータ返還や削除に関する取り決めを必ず確認し、文書で明確にしておくことが重要です。
第5章 PoCを「試す場」から「判断の場」へ変える(ステップ5)
データ準備が整ったら、いよいよ試験導入(PoC)です。しかし、多くの企業がPoCを単なる「お試し」で終わらせてしまいます。PoCの真の目的は、「本格導入に値するかどうかを、客観的なデータに基づいて判断する」ことです。
PoC設計の3つの鉄則
- スコープは小さく: 対象業務やデータ範囲を限定し、短期間で検証できるようにする。
- データは本番想定で: 使うデータは、ステップ4で準備した、本番環境に近い質の高いデータを用いる。
- 評価は厳格に: ステップ3で決めたKPIと合格基準に基づき、機械的に評価する。
ユースケース別:PoCのKPIと合格基準の例
| ユースケース | 主要KPI | 合格基準(Go/No-Go)の例 |
|---|---|---|
| 問い合わせ自動応答 | 正答率、根拠提示率、平均応答時間、一次解決率 | 正答率85%以上、重大な誤答ゼロ、根拠提示率90%以上 |
| マニュアル作成支援 | 編集時間短縮率、誤記削減率、レビュー指摘件数 | 人間がゼロから作成する場合と比較して、編集時間を40%以上短縮 |
| 社内文書検索 | 必要情報への到達時間、再検索率、ユーザー満足度 | 3回以内の検索で90%のユーザーが必要情報に到達できる |
PoCの典型的な落とし穴と回避策
- 落とし穴①:評価指標が曖昧
- 「使いやすかった」「便利だった」といった定性的な感想だけで判断してしまう。
- 回避策: 事前に「正答率」「時間短縮率」などの定量的なKPIと、その合格ラインを明確に定義しておく。
- 落とし穴②:評価データが甘い
- 簡単すぎる質問や、AIが得意なタスクだけで評価してしまう。
- 回避策: ステップ4-6で作成した、難易度やパターンを混ぜた評価データセットを使い、厳しくテストする。
- 落とし穴③:レビュー体制が未整備
- AIの出力を鵜呑みにし、ハルシネーションや間違いを見過ごしてしまう。
- 回避策: PoCの段階から、必ず人間(業務担当者)によるレビュープロセスを組み込む。
PoCの結果、合格基準に満たなかった場合は、勇気を持って「撤退」または「計画の見直し」を判断することが、無駄な投資を防ぐ上で極めて重要です。
第6章 本格導入と「育て続ける」運用体制の構築(ステップ6)
PoCで成功の確証が得られたら、本格導入へと進みます。しかし、本当のスタートはここからです。AIは導入して終わりではなく、継続的にデータを更新し、性能を評価し、改善していく「運用」の仕組みがあって初めて、その価値を持続的に発揮します。これを「LLMOps(大規模言語モデル運用)」と呼びますが、中小企業ではまず「ミニマムLLMOps」から始めましょう。
標準的な運用サイクル(ミニマムLLMOps)
- プロンプトの管理: 成果の出たプロンプトをテンプレート化し、社内で共有。改善があれば版管理を行う。
- データ更新と再評価: 新しいマニュアルが追加されたり、FAQが更新されたりしたら、速やかにAIの参照データにも反映させ、評価データセットで性能が落ちていないか再評価する。
- フィードバック収集: 現場の利用者から「この回答は間違っていた」「この表現は不適切だった」といったフィードバックを収集する仕組みを作り、改善に活かす。
- 利用状況の監視: 誰が、どの業務で、どの程度AIを利用しているかを可視化し、活用が進んでいない部署にはヒアリングを行う。
ガバナンス:AIを正しく使うための社内ルールブック
全社的にAIを安全に活用するため、ガイドラインを整備し、役割分担を明確にします。
- 社内ガイドラインの整備:
- 利用目的: どの業務での利用を推奨し、どの業務では禁止するか。
- 入力禁止情報: ステップ4-2で定義した内容を改めて明記。
- 出力物のレビューと公開基準: AIの生成物を社外に公開する場合の承認フローを定める。
- インシデント発生時の報告ルート: 問題を発見した場合、誰に報告すべきかを明確にする。
- 役割分担の明確化:
- AI責任者: AI活用全体の推進とガバナンスに責任を持つ。
- データ管理者: 各業務データの品質と更新に責任を持つ。
- 運用担当者: 日々の監視、フィードバック収集、改善サイクルを回す。
第7章 効果測定と継続的な改善(ステップ7)
「やりっぱなし」にしないために、導入効果を定期的に測定し、改善のアクションに繋げる仕組みが不可欠です。関係者が一目で状況を把握できる、シンプルなダッシュボードを作成・共有するのが効果的です。
測定ダッシュボードに含めるべき4つの視点
| 視点 | 具体的な指標例 |
|---|---|
| ① 精度・品質 | 誤答率、根拠提示率、レビューでの指摘件数 |
| ② 生産性 | 処理時間の短縮率、一次解決率、手戻り工数 |
| ③ コスト | API利用料、運用にかかる人件費 |
| ④ リスク・コンプライアンス | ガイドライン違反件数、インシデント発生件数 |
改善サイクルの回し方
- 誤答が見つかった場合:
- その質問と正しい回答を「評価データセット」に追加する。
- 原因を分析する(データが古い?プロンプトが曖昧?)。
- データやプロンプトを修正し、再評価する。
- 利用頻度が低い場合:
- 利用者へヒアリングを実施する(使い方がわからない?期待した回答が得られない?)。
- プロンプトのテンプレートを追加したり、研修会を実施したりする。
成果が頭打ちになった場合は、AIの性能だけでなく、「業務プロセス自体に見直すべき点はないか」という、より大きな視点での検討が必要になります。
第8章 【ユースケース別】必要なデータと整備の勘所
ここでは、具体的な業務シーンごとに、どのようなデータが必要で、整備する上で何に気をつけるべきかを解説します。
| ユースケース | 必要なデータの例 | 整備の勘所・注意点 |
|---|---|---|
| お問い合わせ/社内ヘルプデスク | FAQ、製品マニュアル、手続きフロー図、過去の問い合わせ履歴、例外対応集 | 最新版のデータであることを保証する仕組みが最重要。回答の根拠を必ず表示させる。憶測や法律・医療に関する判断はさせないよう、プロンプトで厳しく制限する。 |
| マニュアル作成・更新支援 | 過去の作業記録、製品写真、旧版の手順書、設計変更の履歴、関連する技術仕様書 | 版管理(バージョン管理)を徹底する。専門用語の定義集を別途用意すると精度が向上する。生成された手順書は、必ず現場の熟練者がレビューするプロセスを設ける。 |
| 営業提案書のたたき台作成 | 製品・サービスの仕様書、価格表、導入事例集、過去の成功提案書、提案時の禁止事項リスト | 機密区分の明確化が必須。特に価格情報や未公開事例の取り扱いに注意。出力物は必ず営業担当者が顧客に合わせてカスタマイズし、法務・コンプライアンス部門のレビューを経ることをルール化する。 |
| 社内規程・ナレッジ検索 | 就業規則、経費精算規程、各種申請手続きマニュアル、過去のプロジェクト議事録 | 文書の見出しや段落構成を整え、検索性を高める。古い規程や廃止された制度に関する文書は、明確に「旧版」とわかるようにアーカイブする。メタデータ(施行日、改訂日など)を正確に付与する。 |
第9章 実例から学ぶ:AI導入、成功と失敗の分岐点
具体的な事例から、何をすべきで、何をしてはいけないのかを学びましょう。(※企業名は伏せて一般化しています)
- 失敗例①:安易な利用による情報漏洩
- 状況: ある企業の従業員が、開発中のプログラムコードのデバッグを依頼するため、機密情報を含むソースコードを外部の無料生成AIサービスに貼り付けてしまった。
- 結果: そのコードがAIの学習データとして外部サーバーに保存され、情報漏洩インシデントとして発覚。会社は全社的に当該サービスの利用を禁止せざるを得なくなった。
- 教訓: プロジェクトの初日に「入力禁止情報の定義」と「全社研修」を実施しなかった代償はあまりにも大きい。
- 失敗例②:ハルシネーションの鵜呑み
- 状況: ある自治体が、過去の議事録を要約させるためにAIを活用。AIが生成した「存在しない条例に関する議論」というもっともらしい要約を、担当者が確認せずに公式サイトに掲載してしまった。
- 結果: 市民からの指摘で発覚し、謝罪と訂正に追われる事態に。自治体の信頼性が大きく損なわれた。
- 教訓: AIの出力は「下書き」であり、人間によるファクトチェックは絶対に必要なプロセスである。特に固有名詞、数値、制度名などは原本との照合を徹底すべき。
- 成功例①:製造業での手順書作成自動化
- 状況: ある国内の製造業では、熟練工の退職に伴う技術伝承が課題だった。そこで、作業日報や写真、動画データからAIが手順書のたたき台を自動生成するシステムを導入した。
- 鍵となった取り組み:
- データの版管理を徹底し、AIが常に最新の設計図や作業標準を参照するようにした。
- AIが生成した手順書は、必ず現場のリーダーがレビューし、承認する運用フローを構築した。
- 結果: 手順書作成コストを60%削減し、若手従業員でも品質の均一な作業が可能になった。
- 成功例②:金融機関での顧客対応高度化
- 状況: ある地方銀行では、24時間対応可能なAIチャットボットを導入し、夜間や休日の問い合わせに対応。
- 鍵となった取り組み:
- 導入前に、既存のFAQデータを徹底的にクレンジングし、「一問一答」形式に整理した。
- 「預金残高」や「取引履歴」といった個人情報に関わる質問には回答せず、有人チャットやコールセンターへ誘導する厳格なガバナンスルールを設けた。
- 結果: 顧客満足度を向上させつつ、オペレーターはより複雑なコンサルティング業務に集中できるようになった。
第10章 【明日から使える】AI導入準備セルフチェックリスト
あなたの会社の準備状況を客観的に評価してみましょう。一つでも「いいえ」があれば、そこが最初の着手点です。
| 分野 | チェック項目 | はい/いいえ |
|---|---|---|
| 目的・計画 | AIで改善したい業務と、具体的な数値目標(KPI)は明確か? | |
| PoCの合格基準(Go/No-Go基準)は文書で定義されているか? | ||
| データ棚卸し | 主要な社内データの所在、形式、責任者が一覧化されているか? | |
| 分類・アクセス | データの機密区分(公開可、社内限定など)は定義されているか? | |
| 「入力してはいけない情報」の具体例は全社に周知されているか? | ||
| データのアクセス権限は、従業員の役割に応じて管理されているか? | ||
| 品質・更新 | どれが最新版のデータか明確になっており、旧版は区別されているか? | |
| データが更新された際に、AIの参照先にも反映させるフローはあるか? | ||
| 評価・レビュー | AIの性能を測るための「評価データセット」は用意されているか? | |
| AIの生成物を、業務担当者がレビューする体制は決まっているか? | ||
| リスク・ガバナンス | AI利用に関する社内ガイドラインは整備されているか? | |
| 利用ログを取得し、定期的に監査する計画はあるか? | ||
| ベンダー対応 | プロンプトや評価データを自社資産として管理しているか? | |
| 契約終了時のデータ返還・削除の条件は契約書で明確になっているか? | ||
| 人材・研修 | 全従業員を対象に、AIのリスクと正しい使い方に関する研修を計画しているか? |
第11章 人と仕組み:AIを使いこなすためのリテラシー向上とガバナンス設計
最高のデータとシステムを用意しても、使う「人」のリテラシーが低ければ、宝の持ち腐れになるか、リスクを増大させるだけです。AI導入は、テクノロジーの導入であると同時に、組織文化の変革でもあります。
90分で変わる!ミニマム研修プログラム案
全社員を対象に、短時間でも反復して実施することが定着の鍵です。
- 基礎編(45分):
- AIの得意なこと、苦手なこと(創造と事実確認の区別)
- なぜハルシネーションは起きるのか?
- 会社の情報資産を守る:入力禁止情報の徹底解説
- AI利用ガイドラインの読み合わせ
- 実践編(45分):
- 良い結果を引き出すプロンプトの基本(役割、指示、制約、出力形式)
- AIの回答を疑う:根拠の確認方法とファクトチェックのコツ
- 業務での活用事例紹介(成功例と失敗例)
- 問題を発見したときの報告手順
現場に根付くガイドラインの3つの柱
禁止事項ばかりを並べた分厚いルールブックは誰も読みません。シンプルで、ポジティブな活用を促すガイドラインを目指しましょう。
- 目的の明確化: 「私たちは生産性向上のために、以下のルールを守ってAIを積極的に活用します」という前向きな宣言から始める。
- Do & Don’tの具体例: 「こういう使い方は推奨(Do)」「こういう情報は絶対に入力禁止(Don’t)」を、具体的な業務シーンに即して例示する。
- 相談窓口の設置: 「この情報の入力は大丈夫?」「この使い方は問題ない?」と気軽に相談できる窓口(例:情報システム部、DX推進室)を設ける。
第12章 FAQ(よくある質問)
AI導入を検討する担当者から寄せられる、よくある質問にお答えします。
- Q1:どの業務からAI導入を始めるべきですか?
- A: まずは「①定型的な質問や作業が多く」「②既にFAQやマニュアルなどのデータがある程度整っている」業務から始めるのが成功しやすいです。具体的には、社内ヘルプデスク、カスタマーサポートの一次対応、各種申請手続きの案内などが典型例です。
- Q2:専門的なデータサイエンティストは社内に必要ですか?
- A: 必ずしも必要ではありません。現在のAIサービスは、専門家でなくても活用できるものが増えています。ただし、本記事で解説したデータ整備や運用ルール作りを主導する「プロジェクト推進担当者」を明確に任命することは不可欠です。
- Q3:データが社内のあちこちに散在していますが、どこから手を付ければ良いですか?
- A: すべてを一度にやろうとせず、ステップ1で決めた「対象業務」で使うデータに絞って手をつけるのが賢明です。まずはその範囲で「最新版の特定」と「機密区分のラベリング」から始めましょう。小さな成功体験が、次のステップへの推進力になります。
- Q4:ハルシネーション(AIの嘘)をゼロにすることはできますか?
- A: 現状の技術では、ゼロにすることは困難です。だからこそ、①社内文書のみを根拠に回答させる設計(RAG)と、②人間によるレビュープロセス、という2段構えの対策が不可欠になります。AIの回答は「優秀なアシスタントの第一稿」と捉えるマインドセットが重要です。
- Q5:著作権侵害を避けるためには、具体的に何に注意すれば良いですか?
- A: まず、インターネット上の他社の記事や書籍の内容を無断でコピー&ペーストしてAIに学習させることは避けるべきです。社内利用であっても、著作権法に触れる可能性があります。AIが生成した文章や画像を社外に公開する場合は、他者の著作物と酷似していないか、専用のチェックツールを利用したり、法務担当者に確認したりするプロセスを設けるのが安全です。
- Q6:PoCの期間はどれくらいが目安ですか?
- A: 対象範囲(スコープ)によりますが、目的と評価基準が明確であれば、2週間~1ヶ月程度でも十分に本格導入の可否を判断する材料は得られます。期間を長くすることよりも、「何を検証するのか」という目的の明確さの方が重要です。
まとめ:AI導入成功の鍵は、テクノロジーではなく「準備」と「仕組み」にある
本記事では、中小企業がAI導入で失敗しないための、データ整備を中心とした実践的なロードマップを解説してきました。
要点の再確認:
- AI導入の成否は、技術選定以前の「データ準備」と「運用ガバナンス」で9割決まる。
- 失敗の主要因である「目的の曖昧さ」「運用体制の不備」「データ品質の低さ」は、計画的な準備によって回避できる。
- データ整備は「棚卸し→分類→品質改善→アクセス制御→RAG準備→評価データ作成」の6ステップで進める。
- PoCは「お試し」ではなく、事前に定めたKPIと合格基準で「導入可否を判断する場」と位置づける。
- AIは導入して終わりではない。継続的にデータを更新し、評価・改善を回して「育てていく」仕組みが不可欠。
「AIを導入すれば、誰かが賢く使ってくれるだろう」という考えは、最も危険な幻想です。AIの真の価値を引き出すのは、整備された社内データと、それを安全かつ効果的に活用するための人間系の仕組みに他なりません。
今すぐ始めるべき、次の一歩
この記事を読んで満足するだけでなく、ぜひ具体的な行動に移してください。
- 対象業務を1つに絞る: 最も課題が大きく、かつデータが比較的揃っていそうな業務を1つ選びます。
- KPIと合格基準を紙に書く: その業務の何を、どれくらい改善したいのかを数値目標として書き出し、PoCの合格ラインを仮決めします。
- データカタログ作成に着手する: その業務で使われている主要な文書やファイルを5~10個リストアップすることから始めてみましょう。
中小企業にとって、AIは一見すると「背伸びした投資」に感じられるかもしれません。しかし、本ガイドで示したように、段階的なアプローチと堅実なデータ整備、そして現実的な運用体制を構築すれば、過度なコストをかけずに実用的な成果を得ることは十分に可能です。
あなたの会社に最適なAI活用の旅は、足元にある社内データを整理整頓することから始まります。
「データ整備は人と組織の壁を超える」AI導入の教科書にはない物語 先日、あるメディアに寄稿した『中小企業がAI導入で失敗しないための社内データ整備 実践ロードマップ』という記事があります。ありがたいことに多くの方にお読みいただきまし[…]

