n8n×MCPで企業の自動化基盤を作る:構築手順・活用方法・運用ベストプラクティス
多くの企業で叫ばれる業務自動化。しかし、「誰が自動化の仕組みを設計し、誰が責任をもって維持するのか?」という根源的な問いが、多くのプロジェクトの前に立ちはだかります。現場担当者には技術的なハードルが高すぎ、IT部門は個別の業務ニーズすべてに応えきれない、というジレンマです。
この課題を解決する強力な組み合わせとして、今、n8nとMCP(Model Context Protocol)が注目を集めています。n8nは、プログラミングの知識が少なくてもGUIで複雑なワークフローを構築できるツール。一方、MCPは、人間が使う自然言語の曖昧な指示をAIが解釈し、機械が実行可能なタスクに変換するための「通訳者」の役割を果たします。
この2つを組み合わせることで、「現場担当者が日本語でやりたいことを伝えるだけで、n8nが様々なSaaSや社内システムを横断して実務を自動実行する」という、まさに次世代の自動化基盤が実現します。
この記事では、企業の技術者がこのn8n×MCP連携基盤を「実戦投入できる品質」で構築し、安定運用していくための全手順とベストプラクティスを、網羅的かつ具体的に解説します。クラウドやVPSでの本番環境構築から、MCP Server Triggerノードの具体的な使い方、AIモデルの選定、プロンプト設計、セキュリティ、監視、ROI算定まで、技術者が知りたい情報を一気通貫で提供します。特に、個人情報保護法や請求書制度といった日本企業の固有要件への配慮も盛り込んでいます。
結論ファースト:n8n×MCPで実現する次世代の業務自動化
本題に入る前に、この記事の要点をまとめます。
- MCPは「AIの通訳者」: 日本語の曖昧な指示をAIが解釈し、n8nが確実に実行できる構造化されたタスク(JSON)に変換します。これにより、単なる対話型AIが、業務を遂行する「実行型AI」へと進化します。
- n8nが「実行部隊」に: n8nの「MCP Server Trigger」ノードを使えば、作成したワークフローをMCPクライアントからAPIのように呼び出せる「ツール」として公開できます。開発者は使い慣れたAI搭載エディタから、直接業務自動化ワークフローを起動できるようになります。
- 本番運用には堅牢な基盤が不可欠: Docker Composeをベースに、PostgreSQL(データ永続化)、Redis(キュー管理)、Nginx(リバースプロキシ/TLS終端)を組み合わせた構成がベストプラクティスです。キュー実行、冪等性、リトライ、監視の設計が、システムの信頼性と拡張性を左右します。
- AIモデルは適材適所: 論理的な推論や長文要約にはClaude 3.5 Sonnetのようなモデル、クリエイティブな文章生成にはGPT-4系など、タスクに応じてモデルを使い分けることがコストと品質の最適化に繋がります。JSONスキーマでAIの出力形式を強制し、MCPで受け渡すパラメータを厳密に定義することが安定運用の鍵です。
- 圧倒的なROI: 「日次レポート作成」「アンケートの自動分析」「LINEでの営業日報をCRMに登録」といった代表的なユースケースでは、手作業で60分かかっていた業務が数分で完了し、ROIが1,000%を超えることも珍しくありません。
- 日本の商習慣への適合が成功の鍵: 個人情報保護法への準拠、適格請求書フォーマット、和暦や会計年度の考慮、全角・半角の揺らぎ吸収、休日カレンダーに基づいた処理分岐など、日本の実務に即したワークフローを組むことで、現場での利用率と満足度が格段に向上します。
- 運用は「メタ自動化」で効率化: APIキーの有効期限監視、ワークフローの実行失敗検知とアラート、さらにはエラーログをAIに分析させて改善提案をさせる、といった「自動化を管理するための自動化」をn8n自身で構築することで、運用負荷を劇的に削減できます。
基礎知識:n8nとMCPの全体像を理解する
まずは、この強力な組み合わせを構成する2つの要素、n8nとMCPについて、その役割と連携の仕組みを解説します。
n8nとは?ビジュアルなワークフロー自動化ツール
n8n(エヌ・エイト・エヌと読みます)は、オープンソースのワークフロー自動化ツールです。最大の特徴は、ノードと呼ばれる機能ブロックを線で繋いでいくだけで、様々なアプリケーションやサービスを連携させるワークフローを視覚的に構築できる点にあります。
- 豊富な連携先: 数百種類以上の標準ノードが用意されており、Slack、Google Workspace、Salesforceといった主要なSaaSから、各種データベース、メール、ファイル操作まで、幅広い処理を連携できます。
- 自己ホスト可能 (Self-Hosted): クラウドサービスとして利用するだけでなく、自社のサーバーやクラウド環境に自由にデプロイできます。これにより、データの主権を自社で完全にコントロールでき、セキュリティポリシーにも柔軟に対応可能です。
- エンタープライズ向けの機能: 資格情報(APIキーなど)の暗号化保存、キューモードによる大量処理、ロールベースのアクセス制御(RBAC)など、企業での本格利用に耐えうる機能が充実しています。
MCP(Model Context Protocol)とは?AIのための「通訳者」
MCP(Model Context Protocol)は、AI(特に大規模言語モデル, LLM)と外部ツールとの対話を標準化するためのプロトコルです。人間が使う曖昧な自然言語と、プログラムが解釈できる厳密な構造化データとの間の「橋渡し」役を担います。
- 自然言語から構造化データへ: 例えば「昨日の売上をまとめて営業部に送って」という指示を、AIが解釈し、
tool_name: "sales_report", date: "yesterday", department: "sales"のような、プログラムが処理できる形式に変換します。 - ツールの標準化: MCPに対応したツール(n8nワークフローなど)は、自身の機能、入力パラメータ、出力形式をスキーマとして定義します。これにより、MCPクライアント(AI搭載エディタなど)は、利用可能なツールを自動で検出し、適切なパラメータをAIに生成させることができます。
- 安全な実行: 入力と出力がスキーマで厳密に定義されるため、AIが予期せぬ動作をしたり、不正確なパラメータでツールを実行したりするリスクを低減できます。これにより、AIに業務実行を安全に任せるためのガードレールを設けることが可能になります。
n8nとMCPの連携ポイント:MCP Server Trigger
n8nとMCPを繋ぐ中心的な役割を果たすのが、n8nの「MCP Server Trigger」ノードです。このノードをワークフローの開始点に置くことで、そのワークフロー全体を、MCPクライアントから呼び出し可能な一つの「ツール」として公開できます。
- ツールとして公開: ワークフローにツール名と説明、そして入力・出力のJSONスキーマを定義します。
- MCPクライアントからの呼び出し: AI搭載エディタなどのMCPクライアントが、ユーザーの指示に基づいてこのツールを呼び出します。AIは指示内容を解釈し、定義された入力スキーマに沿ったJSONデータを生成してn8nに送信します。
- 確実な実行: n8nは整形済みのJSONデータを受け取るため、曖昧さが排除された状態で、後続のノード(DB接続、ファイル生成、通知など)を確実に実行できます。
アーキテクチャ解説:ユーザーの指示が自動化されるまで
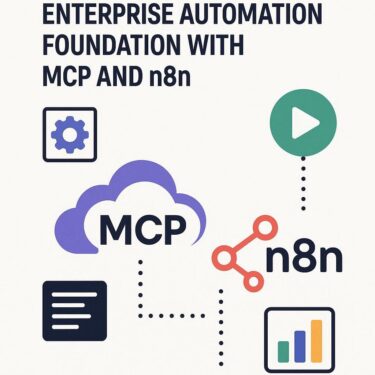
n8nとMCPを組み合わせたシステムの典型的なアーキテクチャは以下のようになります。
- ユーザー: AI搭載エディタで「昨日の全部門の売上を要約してPDFにし、経営企画チームにメールで共有して」と日本語で指示します。
- MCPクライアント: 指示を解釈し、利用可能なツールの中から
daily_sales_reportツールを選択。指示内容をツールの入力スキーマにマッピングし、{"date_from": "YYYY-MM-DD", "date_to": "YYYY-MM-DD", "departments": ["all"], "email_to": ["planning@example.com"]}のようなJSONを生成します。 - n8n (MCP Server Trigger): MCPクライアントからのリクエストを受け取ります。
- n8nワークフロー:
- データベースから指定された期間・部門の売上データを取得します。
- 取得したデータをAIノードに渡し、要約と洞察を生成させます。
- 生成された要約を元にHTMLテンプレートを埋め、PDF化します。
- PDFを添付して、指定された宛先にメールを送信します。
- Slackに関連チャンネルへ完了通知を投稿します。
- n8n: 処理が完了したら、実行IDなどを含む結果をMCPクライアントに返却します。
このように、人間は自然言語で意図を伝えるだけで、裏側では構造化された安全なプロセスが自動で実行されるのです。
【実践ガイド1】本番稼働に耐えるn8n環境の構築
理論を理解したところで、次はいよいよ実践です。PoC(概念実証)で終わらせず、実際の業務で安定して稼働させるための環境構築手順を解説します。
前提条件とサーバー要件
- ドメイン:
n8n.yourcompany.co.jpのような専用のサブドメインを取得しておきます。 - TLS証明書: 通信を暗号化するため、Let’s Encryptなどでサーバー証明書を取得できる準備をします。
- サーバー: ワークフローの規模や同時実行数によりますが、2〜4 vCPU, 8〜16GB RAM, 50GB以上のSSD を推奨します。
- DNS: 取得したドメインに、サーバーのIPアドレスを指すAレコード(またはAAAAレコード)を設定します。
- SMTPサーバー: n8nからの通知やワークフロー内でのメール送信に利用するSMTPサーバーを用意します。
- 各種APIキー: 連携したいSaaSのAPIキーやOAuthクライアント情報を事前に準備しておきます。
選択肢A:ZeaburなどのPaaSで手軽に始める
インフラ管理の手間を最小限に抑えたい場合、ZeaburのようなPaaS(Platform as a Service)を利用するのが最も手軽です。
- プロジェクトを作成し、n8nの公式コンテナイメージ(
n8nio/n8n)をデプロイします。 - 同じプロジェクト内に、PostgreSQLとRedisのマネージドサービスを追加します。
- n8nサービスの環境変数に、データベースやRedisへの接続情報、ドメイン名などを設定します。
N8N_HOST:n8n.yourcompany.co.jpN8N_PROTOCOL:httpsWEBHOOK_URL:https://n8n.yourcompany.co.jp/DB_TYPE:postgresdbDB_POSTGRESDB_...: (PaaSが提供する接続情報を設定)QUEUE_BULL_REDIS_...: (PaaSが提供する接続情報を設定)N8N_ENCRYPTION_KEY:openssl rand -hex 32などで生成した長い乱数文字列。これは絶対に漏洩させてはいけません。EXECUTIONS_MODE:queue(本番環境では必須)N8N_JWT_AUTH_ACTIVE:true(ユーザー認証を有効化)
- PaaSの機能で、カスタムドメインと自動TLS設定を有効化します。
これで、管理画面が公開され、WebhookやMCPの呼び出しもTLSで保護された状態で利用可能になります。
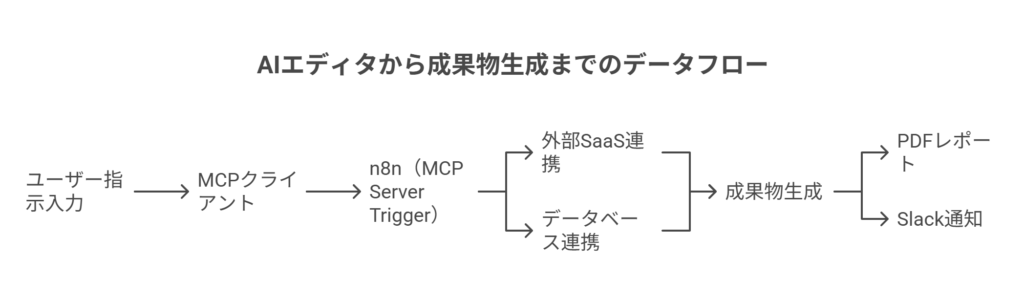
選択肢B:VPSとDocker Composeで堅牢な環境を構築する(詳細手順)
コストやカスタマイズ性を重視する場合は、VPS(Virtual Private Server)上にDocker Composeを使って環境を構築するのが王道です。ここではUbuntu 22.04 LTSを想定した手順を示します。
1. 依存パッケージのインストール
Docker Engine, Docker Compose v2, Nginx, Certbot(Let’s Encrypt用)をインストールします。
2. docker-compose.yml の作成
以下の内容で docker-compose.yml ファイルを作成します。n8n本体、データベース(PostgreSQL)、キュー(Redis)の3つのサービスを定義します。
version: "3.9"
services:
n8n:
image: n8nio/n8n:latest
restart: unless-stopped
environment:
- N8N_HOST=${SUBDOMAIN}.${DOMAIN_NAME}
- N8N_PROTOCOL=https
- WEBHOOK_URL=https://${SUBDOMAIN}.${DOMAIN_NAME}/
- N8N_ENCRYPTION_KEY=${N8N_ENCRYPTION_KEY} # 機密情報は.envファイルから読み込む
- DB_TYPE=postgresdb
- DB_POSTGRESDB_HOST=db
- DB_POSTGRESDB_PORT=5432
- DB_POSTGRESDB_USER=n8n
- DB_POSTGRESDB_PASSWORD=${POSTGRES_PASSWORD}
- DB_POSTGRESDB_DATABASE=n8n
- EXECUTIONS_MODE=queue # 本番環境ではキューモードを推奨
- QUEUE_BULL_REDIS_HOST=redis
- QUEUE_BULL_REDIS_PORT=6379
- N8N_METRICS=true # Prometheusによるメトリクス収集を有効化
- NODE_ENV=production
ports:
- "127.0.0.1:5678:5678" # 外部から直接アクセスさせないためlocalhostにバインド
depends_on:
- db
- redis
volumes:
- n8n_data:/home/node/.n8n
db:
image: postgres:15-alpine
restart: unless-stopped
environment:
- POSTGRES_USER=n8n
- POSTGRES_PASSWORD=${POSTGRES_PASSWORD}
- POSTGRES_DB=n8n
volumes:
- pg_data:/var/lib/postgresql/data
redis:
image: redis:7-alpine
restart: unless-stopped
command: ["redis-server", "--appendonly", "yes"]
volumes:
- redis_data:/data
volumes:
n8n_data:
pg_data:
redis_data:
3. Nginxによるリバースプロキシ設定
Nginxをリバースプロキシとして使い、TLS終端とn8nコンテナへのトラフィック転送を行います。/etc/nginx/sites-available/n8n.conf に以下のように設定します。
server {
server_name n8n.yourcompany.co.jp;
listen 80;
# HTTPからHTTPSへリダイレクト
location / {
return 301 https://$host$request_uri;
}
}
server {
server_name n8n.yourcompany.co.jp;
listen 443 ssl http2;
# SSL証明書の設定(Certbotが自動で設定)
ssl_certificate /etc/letsencrypt/live/n8n.yourcompany.co.jp/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/n8n.yourcompany.co.jp/privkey.pem;
# ファイルアップロードサイズの上限
client_max_body_size 100m;
location / {
proxy_pass http://127.0.0.1:5678;
proxy_http_version 1.1;
proxy_set_header Connection "upgrade";
proxy_set_header Host $host;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
4. TLS証明書の発行と起動
# Nginx設定を有効化
sudo ln -s /etc/nginx/sites-available/n8n.conf /etc/nginx/sites-enabled/
sudo nginx -t && sudo systemctl reload nginx
# CertbotでTLS証明書を発行
sudo certbot --nginx -d n8n.yourcompany.co.jp
# .envファイルを作成し、機密情報を記述
cat <<EOF > .env
SUBDOMAIN=n8n
DOMAIN_NAME=yourcompany.co.jp
N8N_ENCRYPTION_KEY=$(openssl rand -hex 32)
POSTGRES_PASSWORD=$(openssl rand -base64 32)
EOF
# Docker Composeでn8nを起動
docker compose up -d
セキュリティ強化の必須項目(ハードニング)
- アクセス制御: n8nの管理画面へのアクセスは、社内IPアドレスからのアクセスに制限するか、SSO(SAML/OIDC)連携、またはリバースプロキシ側でBasic認証を追加するなど、多層的に防御します。
- バックアップ: PostgreSQLのデータを
pg_dumpで定期的にダンプし、S3互換ストレージなどに自動でバックアップする仕組みを構築します。 - OSとコンテナの更新: OSのセキュリティアップデートを自動適用し、Dockerイメージも定期的に最新版に更新して脆弱性に対応します。
- 機密情報の管理:
.envファイルはrootのみが読み書きできるように権限を設定します。より高度な管理が必要な場合は、HashiCorp Vaultのような外部のシークレット管理ツールとの連携も検討します。
【実践ガイド2】MCP Server Triggerでワークフローを「ツール化」する
環境が整ったら、いよいよMCP連携の核心である「MCP Server Trigger」ノードを使ってみましょう。ここでは、日次売上レポートを生成するワークフローを「ツール」として公開する手順を例に解説します。
基本的な手順:日次売上レポートツールを例に
1. 新規ワークフローとMCP Server Triggerの配置
n8nで新しいワークフローを作成し、最初のノードとして「On App Event」から「MCP Server Trigger」を選択して配置します。
2. ツールの基本情報を設定
ノードの設定画面で、ツールの名前と説明を記述します。これらはMCPクライアント側で表示され、AIがどのツールを使うべきか判断する際の手がかりになります。
- Tool Name:
daily_sales_report - Description: 指定された期間の売上データを部門別に集計し、要約とPDFレポートを生成して関係者に配信します。
3. 入力スキーマ(Input Schema)の定義
このツールが受け付けるパラメータをJSON Schema形式で厳密に定義します。これにより、AIが生成するデータの形式を強制し、予期せぬ入力を防ぎます。
{
"type": "object",
"properties": {
"date_from": {
"type": "string",
"format": "date",
"description": "集計開始日 (YYYY-MM-DD)"
},
"date_to": {
"type": "string",
"format": "date",
"description": "集計終了日 (YYYY-MM-DD)"
},
"departments": {
"type": "array",
"items": { "type": "string" },
"description": "集計対象の部門名配列。空の場合は全部門。"
},
"email_to": {
"type": "array",
"items": { "type": "string", "format": "email" },
"description": "レポートを送付するメールアドレスの配列"
},
"slack_channel": {
"type": "string",
"description": "サマリーを通知するSlackチャンネル名 (例: #sales-report)"
},
"language": {
"type": "string",
"enum": ["ja", "en"],
"default": "ja",
"description": "レポートの言語"
}
},
"required": ["date_from", "date_to", "email_to"]
}
4. 後続の処理ノードを構成
MCP Server Triggerから受け取ったパラメータを使い、実際の処理を行うノードを繋げていきます。
- Postgresノード:
{{ $json.date_from }}のようにして入力パラメータを参照し、データベースから売上データを取得するSQLを実行します。 - AI Agent / LLM Chainノード: 取得したデータをAIに渡し、要約や洞察を生成させます。プロンプトには目的や出力形式を明確に指示します。
- Edit HTML / Convert to PDFノード: HTMLテンプレートにAIが生成した要約や集計データを埋め込み、PDFファイルに変換します。
- Send Email / Slackノード: 生成したPDFを添付してメールを送信し、Slackにサマリーを投稿します。
- Respond to Webhookノード: 最後に、処理結果をMCPクライアントに返すための応答を定義します。出力スキーマ(Output Schema)も定義しておくと、より堅牢になります。
5. ワークフローを有効化
画面右上の「Active」トグルをオンにすると、このワークフローはMCPクライアントからの呼び出しを待ち受ける状態になります。
高度な活用:認可・認証と監査証跡
本番運用では、誰でも自由にツールを呼び出せる状態は危険です。MCP Server Triggerの認証設定で、APIキーやOAuth2を利用した認証を必須にしましょう。これにより、許可されたMCPクライアントからしかリクエストを受け付けなくなります。
また、リクエストヘッダーに呼び出し元のユーザーIDなどを含めてもらい、それをn8nの実行ログに記録することで、「誰が、いつ、どのパラメータで、何を実行したか」という監査証跡を残すことができ、責任の所在が明確になります。
【実践ガイド3】AIの性能を最大限に引き出すプロンプト設計術
n8nとMCPの連携において、AIは単なるテキスト生成器ではありません。構造化データを正確に生成し、ビジネスロジックを補完する重要な役割を担います。その性能を引き出すためのプロンプト設計にはいくつかのコツがあります。
AIモデルの戦略的な使い分け
すべてのタスクに最強のモデルを使うのはコスト的に非効率です。タスクの特性に応じてモデルを使い分けましょう。
- 論理的思考・長文要約: ビジネスレポートの作成、データ分析の洞察抽出など、複雑で長い文脈の理解が必要なタスクには、Claude 3.5 Sonnet や GPT-4o が適しています。
- 創造性・コピーライティング: キャッチーな見出しの生成、マーケティングメールの文面作成など、創造性が求められるタスクには GPT-4o が強みを発揮します。
- 高速な分類・ルーティング: ユーザーからの問い合わせ内容を分類したり、単純なデータ整形を行ったりするような高速性が求められるタスクには、より軽量で安価なモデル(例: Claude 3 Haiku, GPT-3.5 Turbo)で十分です。
n8nのワークフロー内で、最初のステップで軽量モデルにタスクを分類させ、その結果に応じて後続で呼び出す高機能モデルを切り替える、といった動的な設計も可能です。
出力の安定性を高める設計パターン
AIの出力が不安定では、自動化システムは成り立ちません。以下のテクニックでAIの振る舞いをコントロールします。
- JSONスキーマの強制: AIノードの設定で、出力形式をJSONにし、期待するスキーマを明示します。多くのモデルは、スキーマに準拠したJSONのみを生成するように指示できます。
- 役割(ペルソナ)の付与: プロンプトの冒頭で「あなたは優秀なデータアナリストです」「あなたは経験豊富なカスタマーサポート担当者です」のように役割を与えることで、出力のトーンや専門性が安定します。
- Few-shotプロンプティング: 期待する入力と出力の例を2〜3個プロンプトに含めることで、AIはタスクの意図をより正確に学習し、安定した結果を返すようになります。
- フォールバック処理: AIの出力がスキーマに違反した場合や、予期せぬエラーを返した場合に備え、n8nのIfノードやError Triggerで分岐させ、固定の値を返す、リトライする、人間に通知する、といった代替処理を必ず設計しておきましょう。
日本語環境特有の注意点とプロンプト雛形
日本語の処理には特有の難しさがあります。これらをプロンプトで明示的に指示することが重要です。
- 全角/半角の統一: 顧客名、製品番号、郵便番号などで混在しがちな全角/半角は、「数値とアルファベットはすべて半角で出力してください」と指示します。
- 日付・数値形式: 「日付はYYYY/MM/DD形式で」「金額は3桁ごとにカンマを入れ、末尾に『円』を付けてください」のように、日本のビジネス文書で一般的な形式を指定します。
- 敬語・文体の使い分け: 社内Slackへの通知はカジュアルな口調、顧客へのメールは丁寧な敬語、といったように、出力先に応じた文体を指示します。
- 固有名詞の扱い: AIが知らない社内用語や製品名は、プロンプト内で定義リストとして提供することで、誤変換を防ぎます。
【プロンプト雛形:売上データ要約タスク】
# System Prompt
あなたは、日本の事業会社に所属する優秀な経営企画アナリストです。
以下の制約条件を厳格に守り、提供されたデータに基づいて分析サマリーを生成してください。
出力は、指定されたJSONスキーマに準拠したJSONオブジェクトのみとし、それ以外のテキストは一切含めないでください。
# 制約条件
- 数値はすべて半角で出力する。
- 金額は3桁区切りのカンマを付け、「円」を単位として表記する。
- 日付は「YYYY年MM月DD日」の形式で表記する。
- 分析は、提供されたデータのみを根拠とし、憶測を含めない。
- 要約は、箇条書きを用いて簡潔にまとめる。
# User Prompt
以下のJSONスキーマに従って、入力データを分析し、結果をJSON形式で出力してください。
## スキーマ
{{ $json.schema }}
## 入力データ
{{ $json.sales_data }}
【実践ガイド4】すぐに使える代表ユースケース3選
n8n×MCPがどのような業務で価値を発揮するのか、具体的なユースケースを3つ紹介します。
ケースA:日次レポートの完全自動化
- トリガー: MCP Server Trigger(手動での期間指定実行)と、Schedule Trigger(毎朝9時に前日分を自動実行)の併用。
- 処理フロー:
- データベースから指定期間の売上データを取得。
- AIノードで、前日比、目標達成率、特筆すべき傾向などを分析・要約させる。
- HTMLテンプレートに分析結果を埋め込み、PDFレポートを生成。
- 関係部署のメーリングリストにPDFを添付して送信。
- Slackのレポートチャンネルに、主要KPIとPDFへのリンクを投稿。
- 成果: これまで担当者が毎日1時間かけていたレポート作成業務が、初回のワークフロー設定(約半日)だけで完全に自動化。レポートの品質が属人化せず、常に一定のクオリティを保てるようになりました。
ケースB:アンケート自由記述の自動分析
- トリガー: Google Formsの「New Response」トリガー。
- 処理フロー:
- 新しい回答が投稿されたら、自由記述欄のテキストを取得。
- AIノードで、テキストの感情(ポジティブ/ネガティブ/ニュートラル)、主要なキーワード、カテゴリ分類(例:価格、機能、サポート)を抽出させる。
- 分析結果をGoogle Sheetsのスプレッドシートに追記し、BIツールで可視化できるようにする。
- 特にネガティブな意見や、緊急対応が必要なキーワードが含まれていた場合は、担当部署のSlackチャンネルに即時アラートを通知。
- ポイント: 大量の回答データを一括で処理する場合、Split in Batchesノードでデータを分割し、サブワークフローで並列処理させることで、処理時間を大幅に短縮できます。
ケースC:LINE日報からCRMへの自動登録
- トリガー: LINEのWebhook。営業担当者がLINE公式アカウントに日報をテキストで送信。
- 処理フロー:
- LINEから送信された日報テキストを受け取る。
- MCPの仕組みを応用し、自然言語の日報テキストをAIに解釈させ、顧客名、商談フェーズ、受注確度、次回アクションといった構造化データに変換させる。
- 変換されたデータを元に、SalesforceなどのCRMで該当する商談レコードを検索し、活動履歴として登録・更新する。
- 次回アクションが設定されていれば、担当者のGoogle Calendarに予定を自動で登録。
- 上長に、部下の日報の要点をまとめたダイジェストをSlackのDMで通知。
- 留意点: 日報には個人情報が含まれる可能性があるため、AIに渡す前に特定のキーワードをマスキングする処理を入れたり、CRM登録前に誤分類がないかを確認するための承認ステップを挟んだりするなどの配慮が必要です。
運用の核心:信頼性・拡張性・監査性を担保する設計
自動化システムは、作って終わりではありません。ビジネスの根幹を支えるからこそ、止まらない、スケールする、追跡できる設計が不可欠です。
- キュー実行とスケール: 環境変数
EXECUTIONS_MODE=queueを設定し、Redisを導入することで、ワークフローの実行がキューイングされます。これにより、Webhookが集中してもリクエストを取りこぼすことなく、順次処理できます。負荷が高まってきたら、n8nのワーカーコンテナの数を増やすだけで、処理能力を水平にスケールさせることが可能です。 - 冪等性(べきとうせい): 「同じ操作を何度実行しても、結果が同じである」という性質です。例えば、Webhookをトリガーにする場合、ネットワークの都合で同じリクエストが2回届く可能性があります。外部から連携されるイベントIDなどをキーにして、「このIDは既に処理済みか?」を最初にチェックし、処理済みであればスキップするロジックを入れることで、意図しない二重処理を防ぎます。
- リトライとデッドレターキュー(DLQ): 外部APIの一時的なエラー(503 Service Unavailableなど)でワークフローが失敗した場合、すぐに諦めるのではなく、少し時間を置いてから再試行(リトライ)する設定が有効です。n8nのノード設定でリトライ回数を指定できます。数回リトライしても成功しない恒久的なエラーの場合は、その実行データを別のキュー(DLQ)やデータベースに隔離し、後で人間が原因を調査・判断できるようにします。
- 監視と可観測性:
- メトリクス: n8nはPrometheus形式で内部の状態(実行成功/失敗数、実行時間、キューの長さなど)を公開できます。これをGrafanaなどで可視化し、システムの健康状態を常に把握できるようにします。
- アラート: 「5分間で失敗率が10%を超えた」「キューに100件以上のジョブが滞留している」といった異常のしきい値を定め、自動で管理者にアラートが飛ぶように設定します。
- ログ: ワークフローの実行ログは、エラー発生時の原因究明に不可欠です。個人情報などの機微な情報はマスキングした上で、ログを収集・分析できる基盤(ELK Stackなど)に転送することも検討しましょう。
- セキュリティとコンプライアンス(日本法規への対応):
- 資格情報の保護: APIキーやパスワードは、必ずn8nの暗号化された資格情報ストアに保存します。
N8N_ENCRYPTION_KEYは最も厳重に管理すべき秘密情報です。 - 権限の最小化: n8nから外部SaaSに接続する際は、ワークフローに必要な最小限の権限(例:読み取り専用)だけを持ったAPIキーを使用します。
- 個人情報保護法: ワークフローで扱うデータに個人情報が含まれる場合、その利用目的を明確にし、必要最小限のデータのみを扱うように設計します。不要になったデータは速やかに削除する仕組みも重要です。
- 日本の商習慣対応: 請求書を生成するワークフローでは、適格請求書発行事業者の登録番号や、税率ごとの消費税額を正確に記載する必要があります。また、月末処理などでは、日本の祝日カレンダーを考慮し、営業日ベースで日付を計算するロジックが求められます。
- 資格情報の保護: APIキーやパスワードは、必ずn8nの暗号化された資格情報ストアに保存します。
コスト最適化とROIの試算方法
自動化基盤の導入にはコストがかかりますが、それを上回る効果を定量的に示すことが、プロジェクトの継続には不可欠です。
月次コストの構成要素
- インフラ費用: VPSやPaaSの利用料、データ転送量など。
- AI API利用料: LLMのAPIコールにかかる費用。モデルやトークン数によって変動します。
- その他SaaS費用: 連携先のSaaSで、API利用が有料プランや従量課金の対象となる場合があります。
- 人的コスト: ワークフローの開発・運用・監視にかかる人件費。
ROI(投資対効果)の計算
- 削減効果の金額換算: 自動化によって削減できた作業時間を洗い出します。
- 例: レポート作成業務 1時間/日 × 20営業日/月 × 担当者1名 = 20時間/月
- この時間に担当者の時給(給与や社会保険料などを含めて算出)を掛けて、月間の削減効果金額を算出します。
- ROIの算出:
- ROI (%) = (年間の削減効果金額 – 年間の総コスト) ÷ 年間の総コスト × 100
- 例えば、年間コストが24万円(月2万円)で、年間180万円相当(月15万円)の作業時間を削減できた場合、ROIは (180 – 24) ÷ 24 × 100 = 650% となります。
コスト削減の具体策
- トークン削減: AIに渡すデータを事前にn8nで必要な部分だけに絞り込む、サマリーを生成させるなどして、APIコール時のトークン数を削減します。
- モデルの最適化: 常に最高性能のモデルを使うのではなく、タスクに応じて安価なモデルを積極的に活用します。
- キャッシュ活用: 同じ入力に対して頻繁に実行される処理は、結果をRedisなどに一時的にキャッシュし、APIコール自体を減らします。
- 差分処理: 全件データを毎回処理するのではなく、前回の実行時から変更があったデータ(差分)のみを処理対象とすることで、処理量を大幅に削減できます。
FAQ(よくある質問)
Q1: MCP Server Triggerの入力は自然言語でも大丈夫?
A: いいえ、n8nのMCP Server Triggerが直接受け取るのは、整形済みのJSONデータです。自然言語の解釈とJSONへの変換は、手前にあるMCPクライアント(AI搭載エディタなど)の役割です。n8n側では、入力スキーマを厳密に定義することで、クライアント側が生成すべきJSONの形式を規定します。
Q2: 外部にWebhookやMCPのエンドポイントを公開しても安全ですか?
A: 適切なセキュリティ対策を講じれば安全性を高めることができます。具体的には、(1)通信のTLS暗号化、(2)APIキーやOAuthによる認証、(3)IPアドレスによるアクセス元制限、(4)Webhookの署名検証、(5)RBACによる権限管理、(6)詳細な監査ログの取得、といった多層的な防御が重要です。扱うデータに応じて、マスキングなどの追加対策も検討してください。
Q3: PDFを生成すると日本語が文字化けします。
A: n8nが動作しているコンテナ内に、日本語フォント(例: Noto Sans CJK JP)がインストールされていないことが原因です。Dockerfileをカスタマイズしてフォントをインストールするか、日本語フォントがプリインストールされたコンテナイメージを利用してください。
Q4: 多数のワークフローを並列実行すると、連携先SaaSのAPIレート制限に引っかかってしまいます。
A: n8nのQueue Modeには、特定のワーカーやキューの同時実行数を制限する機能があります。特定のSaaSにアクセスするワークフローを専用のキューに割り当て、そのキューの同時実行数をAPIレート制限内に収まるように調整してください。また、APIエラーが発生した際に、指数関数的に待ち時間を増やしながらリトライする「Exponential Backoff」戦略も有効です。
Q5: 人による承認プロセスをワークフローに組み込めますか?
A: はい、可能です。例えば、高額な請求書を発行するワークフローの場合、AIが請求書データを作成した後に処理を一時停止させ、承認者(上長など)にSlackで承認依頼を送信します。承認者がボタンをクリックしたら、その結果をWebhookで受け取り、ワークフローを再開させる、といった実装ができます。
まとめ:自動化の先にある未来と、あなたの次のアクション
n8nとMCPの組み合わせは、単なる業務効率化ツールではありません。それは、「人間が本来集中すべき創造的な仕事に時間を使う」という未来を実現するための、強力な自動化基盤です。MCPが人間と機械の間の言語の壁を取り払い、n8nが多様なシステムを確実に連携させ、AIが知的な判断を補完する。この三位一体の仕組みを使いこなすことで、企業の生産性は飛躍的に向上するでしょう。
この記事では、そのための理論から実践、そして本番運用に至るまでの詳細なガイドを示しました。重要なのは、小さく始めて、成功体験を積み重ね、徐々に適用範囲を広げていくことです。
あなたの次のアクションプラン:
- 環境構築: まずは手元のPCやテスト用のVPSに、Docker Composeを使ってn8nの環境を立ち上げてみましょう。
- 最初のツール作成: この記事を参考に、「日次売上レポート」のワークフローをMCP Server Triggerを使って作成してみます。データベースの代わりに、固定のJSONデータを使えば手軽に試せます。
- AI連携: 作成したワークフローにAIノードを組み込み、簡単な要約を生成させてみましょう。複数のAIモデルを試し、出力の違いやレスポンス速度を体感してください。
- 成果の可視化: 最初のワークフローで削減できた時間を計測し、ROIを試算してみましょう。その小さな成功が、社内での協力者を得るための強力な武器になります。
自動化の本質は、仕事をなくすことではなく、価値の低い作業をなくし、人間がより価値の高い仕事に集中できる環境を作ることです。n8nとMCPという強力な道具を手に、あなたの会社のDXを、今日から一歩前進させてください。

