- 1 n8n×AIモデル推論APIで業務自動化を極める:設計から実装・運用・拡張の構築ガイド
- 2 はじめに:なぜ今、自己ホスティング可能な「n8n×AI」が重要なのか
- 3 基礎理解:n8n×AI自動化の全体像
- 4 実装ガイド1:最小構成で「AI要約ボット」を作る
- 5 実装ガイド2:自然言語でワークフローを起動する(MCP活用)
- 6 実装ガイド3:コンテンツ自動生成・公開(常時稼働を無料枠で)
- 7 AI推論APIを使いこなす:実用パターンとプロンプト設計
- 8 本番運用への道:セキュリティとコンプライアンス
- 9 安定稼働を実現する運用ベストプラクティス
- 10 次のレベルへ:n8n×AIの拡張戦略
- 11 実践のためのリソース集
- 12 結論:AI自動化を成功させるためのロードマップ
n8n×AIモデル推論APIで業務自動化を極める:設計から実装・運用・拡張の構築ガイド
はじめに:なぜ今、自己ホスティング可能な「n8n×AI」が重要なのか
生成AIを業務に組み込む試みは、多くの現場で始まっています。しかし、単発のプロンプト実行や一時的なスクリプト開発で終わってしまい、継続的に運用できる「仕組み」として定着させることには、多くの技術的課題が伴います。監視、エラーリカバリ、権限管理、そしてコスト制御といった実運用に不可欠な要素が設計されていなければ、せっかくの自動化も「野良ツール」となり、やがて使われなくなってしまいます。
このような課題に対する強力な解決策となるのが、自己ホスティング可能なオープンソースの自動化ツール「n8n」です。n8nは、AI推論API(OpenAI互換APIやローカルで動作するOllamaなど)を中核に据えた業務フローのオーケストレーション(編成・管理)に最適なプラットフォームと言えます。Zapierのような直感的なUIを持ちながら、サーバーを自前で管理できるため、データ主権、拡張性、コスト効率のすべてを高いレベルで満たすことが可能です。
本記事では、技術者の方々を対象に、「n8n×AIモデル推論API」を組み合わせた自動化システムをゼロから構築し、低コストで安定運用し、チーム全体に普及させるためのベストプラクティスを体系的に解説します。具体的な実装手順やコード例はもちろん、アーキテクチャ設計の判断基準、セキュリティ対策、そして日本国内の運用事情に即した具体的なノウハウまで、網羅的に掘り下げていきます。
自然言語でワークフローを起動するMCP(Model Context Protocol)連携や、クラウドの無料枠を活用した常時稼働システムの構築など、一歩進んだテクニックも紹介します。この記事を読み終える頃には、あなたはn8nとAIを自在に操り、現場の課題を解決する堅牢な自動化ワークフローを設計・実装できる知識を身につけているでしょう。
要点サマリ(先に結論)
この記事で解説する重要なポイントを先にまとめます。
- n8nは自己ホスト可能な汎用オートメーション基盤: AI推論API(クラウド/ローカル)をHTTP経由で安全に呼び出し、ワークフローを編成できます。Zapierのような使い勝手と、内製化ならではの柔軟性・コスト管理を両立します。
- 最小構成は4点セットから: まずは「トリガー(Webhook/スケジュール) → AI呼び出し(HTTP Request) → データ整形(Function) → 出力(Slack/メール等)」の基本形をマスターすることが成功への近道です。
- 低コストでの24/7運用も可能: クラウドの無料枠やローカルのGPU/CPUで動作するOllamaを活用すれば、常時稼働の基盤を低コストで構築できます(※無料枠の提供内容は変動するため、最新仕様の確認が必須)。監視にはUptime Kumaなどの外部ツールを併用します。
- 自然言語での起動も実現可能: MCP(Model Context Protocol)に対応したデスクトップAIクライアントと連携すれば、「会議を開始」といった自然言語の指示でn8nのWebhookを叩き、議事録生成から配信までを全自動化できます。
- 本番運用には設計が不可欠: 「権限分離・秘密情報管理・Webhook保護・キューイング・監視・Gitでのバージョン管理・コスト可視化」が本番運用の柱です。特に、日本の個人情報保護法(APPI)を遵守したデータガバナンスの設計は欠かせません。
- 拡張性は非常に高い: 標準で対応していないAPIも、カスタムノードを開発することで統合可能です。RAG(検索拡張生成)、関数呼び出し、承認ステップ、多段プロンプトといった高度な要件にも十分耐えられます。
- 成果を出すためのマインドセット: 「Human-in-the-Loop(人間の判断をループに組み込む)」設計でAIの信頼性を担保し、「ビルド・イン・パブリック(構築過程を発信する)」戦略でチームの信頼とコンテンツ力を同時に高めるアプローチが有効です。
基礎理解:n8n×AI自動化の全体像
具体的な実装に入る前に、まずはn8nとAI自動化の全体像を把握しましょう。各コンポーネントの役割と、それらがどのように連携するのかを理解することが、堅牢なシステム設計の第一歩です。
n8nとは:自己ホスティング可能な自動化ツールの強み
n8nは、サーバーにインストールして利用するワークフロー自動化ツールです。ノーコード/ローコードのUI上で「ノード」と呼ばれる機能ブロック(トリガーやアクション)を線でつなぎ合わせることで、プログラミングの知識が浅い人でも複雑な自動化フローを構築できます。
- 主な特徴:
- 自己ホスティング: 自社のサーバーやクラウド環境で運用するため、データを外部に出す必要がなく、データ主権を完全にコントロールできます。
- 拡張性: REST API、データベース、各種SaaS、ファイル操作など、数百種類の標準ノードに加え、カスタムノードを作成して独自の機能を追加できます。
- コスト効率: オープンソース版は無料で開始でき、リソースに応じた費用だけで済むため、処理量が増えてもSaaS型ツールのように料金が跳ね上がることはありません。
- スケーラビリティ: 実運用では、データベース(例: PostgreSQL)とキュー(例: Redis)を組み合わせた構成にすることで、大量の処理を安定して捌けるようにスケールさせることが可能です。
AIモデル推論APIとは:クラウドとローカルの選択肢
AIモデル推論APIは、学習済みのAIモデルに対してHTTPリクエストを送ることで、テキスト生成、要約、分類、情報抽出といった高度な処理を実行させるためのインターフェースです。
- 主な選択肢:
- クラウドAPI: OpenAI(GPTシリーズ)、Anthropic(Claudeシリーズ)、Google(Geminiシリーズ)などが提供するサービス。高性能な最新モデルを手軽に利用できますが、データ送信の必要性や従量課金コストが伴います。
- ローカルAPI(Ollamaなど): Llama 3などのオープンソースモデルを、自社のサーバーやローカルPC上で動かすためのツール。Ollamaを使えば、簡単なコマンドでAPIサーバーを起動できます。プライバシーと運用コストの両面で有利な場合がありますが、モデルの管理や性能チューニングは自前で行う必要があります。
- 選定基準: 用途(日本語性能、応答速度)、コスト、データプライバシーポリシーなどを総合的に比較検討して、最適なAPIを選択します。
アーキテクチャの基本パターン:自動化フローの6ステップ
n8nでAIを活用したワークフローを構築する際の基本的な構成は、以下の6つのステップに分解できます。
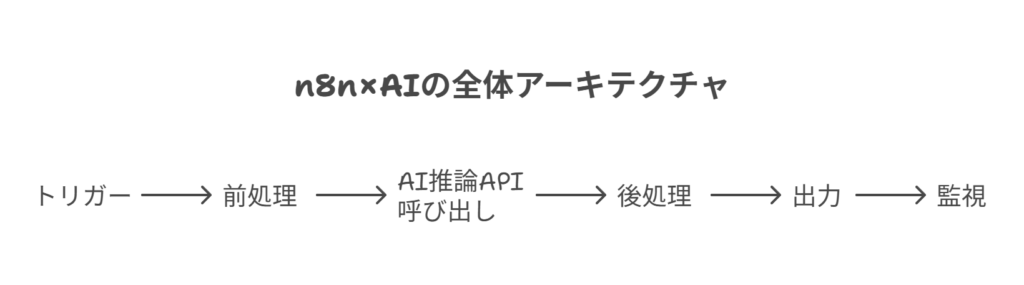
- トリガー (Trigger): ワークフローを開始するきっかけ。Webhook、定時実行(スケジュール)、特定のイベント(ファイルの追加など)が該当します。
- 前処理 (Pre-processing): AIに渡すためのデータを準備する工程。入力データの整形、検証、外部からの前提知識の取得などを行います。
- 推論API呼び出し (Inference): 整形したデータとプロンプト(指示文)をAIモデルに送信します。モデルの種類、温度(創造性の度合い)、トークン上限などを設定します。
- 後処理 (Post-processing): AIからの応答を解析し、次の工程で使いやすい形に整形します。JSON形式への変換、安全フィルターの適用、不要な部分の削除などです。
- 配信・記録 (Delivery/Logging): 処理結果を最終的な目的地に届けます。Slackやメールへの通知、WordPressへの投稿、データベースやファイルへの保存などが考えられます。
- 監視・エラー処理 (Monitoring/Error Handling): フローのどこかで問題が発生した場合の処理。エラー内容の通知、自動再試行(リトライ)、処理を一時保留して人手の介入を待つ、といった制御を行います。
常時稼働の土台:無料枠クラウドと監視ツールの活用
個人や小規模チームで始める場合、24時間365日稼働するサーバーを維持するのはコスト的に負担が大きいかもしれません。しかし、一部のクラウドプロバイダーが提供する無料枠(例: Armベースのコンピュートインスタンスやストレージ)をうまく活用すれば、低コストで常時稼働の環境を構築できる可能性があります。
- 注意点: 無料枠の提供内容は、時期やリージョンによって大きく変動します。利用規約をよく読み、リソース上限や無操作時のインスタンス停止条件などを事前に確認してください。
- 監視ツール: Uptime Kumaのようなオープンソースの監視ツールを併用し、n8nサーバーの死活監視、レスポンス時間の計測、SSL証明書の有効期限などを可視化することで、安定運用を支援します。
実装ガイド1:最小構成で「AI要約ボット」を作る
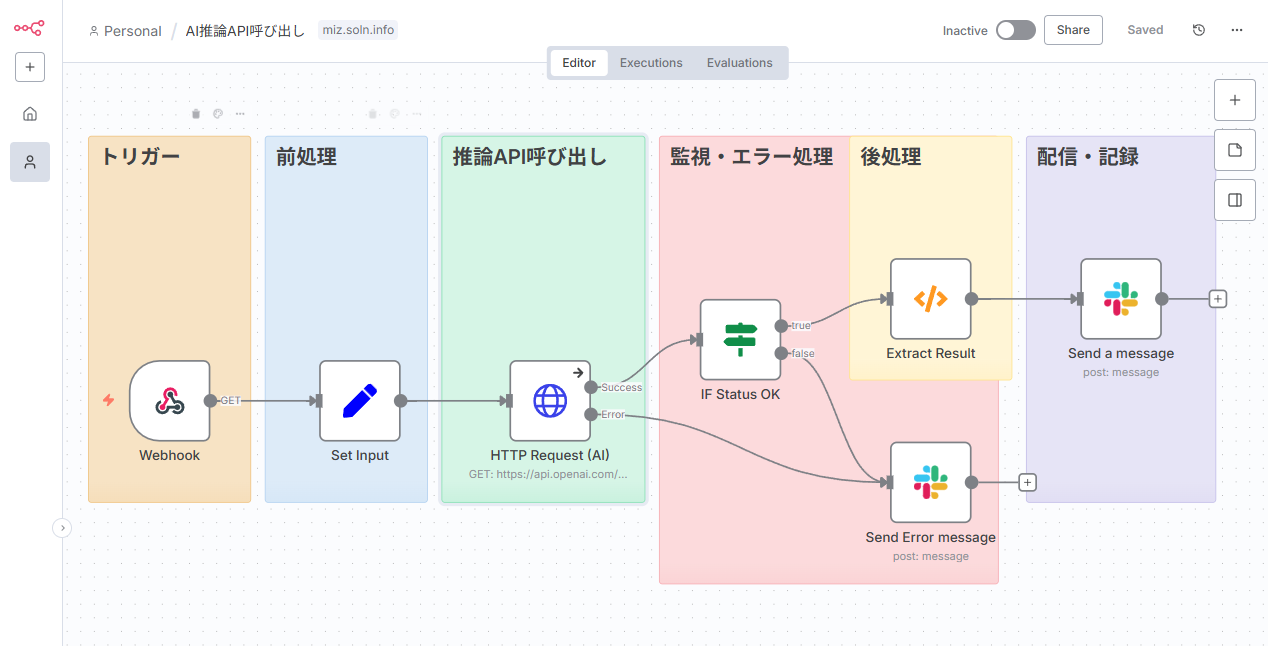
理論を学んだところで、早速手を動かしてみましょう。最初のステップとして、指定されたURLのウェブページをAIが要約し、その結果をSlackに投稿する「AI要約ボット」を作成します。これはn8n×AI自動化の最も基本的なパターンです。
目的と全体像(ノード構成)
- 目的: POSTリクエストでドキュメントのURLを受け取り、内容を日本語で要約してSlackに通知する。
- ノード構成(概略):
- Trigger:
Webhook(POST/summarize) - Get Content:
HTTP Request(対象URLから本文を取得) - Format Text: Code (テキストのクリーニングと長文分割)
- Inference:
HTTP Request(AI推論APIを呼び出し) - Output:
Slack(結果を投稿)
- Trigger:
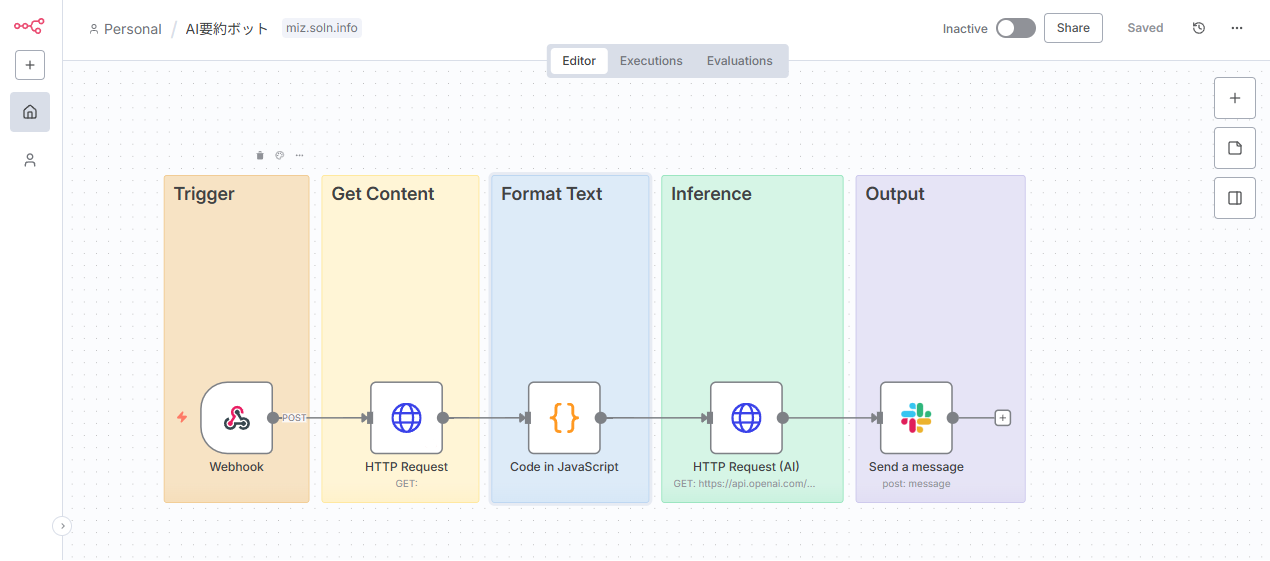
Step 1: Webhookトリガーの設定
まず、ワークフローの入り口となるWebhookノードを配置します。
HTTP Method: POSTAuthentication: Basic Auth(セキュリティ向上のため、ユーザー名とパスワードを設定)Path:summarize(URLはhttps://<あなたのn8nドメイン>/webhook/summarizeのようになります)- このWebhookは、
{ \"url\": \"https://example.com/article\" }のようなJSON形式のデータを受け取ることを想定します。
Step 2: HTTP Requestによるコンテンツ取得
次に、Webhookで受け取ったURLのコンテンツを取得します。
HTTP Requestノードを追加します。URL:{{ $json.body.url }}(Webhookで受け取ったJSONボディのurlキーを参照する式)Method: GETOptions>Timeout/Retries: 外部サイトへのアクセスは不安定な場合があるため、適切なタイムアウトとリトライ回数を設定しておくと堅牢性が増します。
HTMLから本文テキストだけを綺麗に抽出するのは意外と難しい処理です。ここでは簡易的な方法を紹介しますが、本格的な運用では専用のスクレイピングサービスやライブラリを挟むことを推奨します。
Step 3: Codeノードによるテキスト整形
取得したHTMLからテキストを抽出し、AIが処理しやすいように長文を分割します。
- Code ノードを追加し、以下のJavaScriptコード(またはそれに類するロジック)を記述します。
/**
* 入力: items[0].json.data (HTTP Requestのレスポンスボディ)
* 出力: items[0].json.chunks (最大N文字に分割したテキストの配列)
*/
const html = items[0].json.data;
// scriptタグやstyleタグ、その他のHTMLタグを簡易的に除去
const text = html
.replace(/<script[\\s\\S]*?<\\/script>/gi, '')
.replace(/<style[\\s\\S]*?<\\/style>/gi, '')
.replace(/<[^>]+>/g, ' ')
.replace(/\\s\\s+/g, ' ')
.trim();
// モデルのコンテキスト長やコストに応じて最大文字数を調整
const maxChunkSize = 2000;
const chunks = [];
for (let i = 0; i < text.length; i += maxChunkSize) {
chunks.push(text.slice(i, i + maxChunkSize));
}
// 分割したチャンクを後続のノードに渡す
return [{
json: {
chunks: chunks
}
}];Step 4: HTTP RequestによるAI推論API呼び出し
いよいよAIを呼び出します。ここではOpenAI互換APIとOllamaの2つの例を示します。
- OpenAI互換APIの場合(Chat Completions)
HTTP Requestノードを追加します。Method: POSTURL:https://api.openai.com/v1/chat/completions(または利用するサービスの互換エンドポイント)Authentication:Header AuthName:AuthorizationValue:Bearer {{ $credentials.openAiApiKey.apiKey }}(n8nのCredentials機能にAPIキーを保存した場合)Body Content Type:JSONBody Parameters(RAW JSON):
{ \"model\": \"gpt-4o-mini\", \"temperature\": 0.2, \"response_format\": { \"type\": \"json_object\" }, \"messages\": [ { \"role\": \"system\", \"content\": \"あなたは与えられた文章を分析し、要点を簡潔にまとめる日本語の専門家です。出力は必ず指定されたJSONスキーマに従ってください。\" }, { \"role\": \"user\", \"content\": \"以下のテキストを日本語で3つの箇条書きで要約し、関連する重要キーワードを5個抽出してください。\ \ テキスト:\ {{ $json.chunks.join('\\\ ---\\\ ') }}\ \ JSONスキーマ:\ {\\\"summary\\\": [\\\"要約1\\\", \\\"要約2\\\", \\\"要約3\\\"], \\\"keywords\\\": [\\\"キーワード1\\\", \\\"キーワード2\\\", \\\"キーワード3\\\", \\\"キーワード4\\\", \\\"キーワード5\\\"]}\" } ] } - Ollamaの場合(ローカル実行)
URL:http://localhost:11434/api/chat(Ollamaが動作しているサーバーのアドレス)Body Parameters(RAW JSON):
{ \"model\": \"llama3\", \"messages\": [ { \"role\": \"system\", \"content\": \"日本語で厳密に要約してください。箇条書き3点と、最後にハッシュタグ形式でキーワードを3つ付けてください。\" }, { \"role\": \"user\", \"content\": \"{{ $json.chunks.join('\\\ ---\\\ ') }}\" } ], \"stream\": false }
Step 5: Slackノードへの出力
最後に、AIの生成結果をSlackに投稿します。
Slackノードを追加します。Authentication:Webhookを選択し、Slackで発行したIncoming Webhook URLをCredentialsに保存して設定します。Textフィールドに、以下のようなメッセージを組み立てます。(AIのレスポンス形式に応じてパスを調整してください)
*要約結果*
? {{ $json.choices[0].message.content.summary.join('\
? ') }}
*キーワード*: {{ $json.choices[0].message.content.keywords.join(', ') }}運用のコツと注意点
- 長文処理: モデルのコンテキスト上限を超えないよう、必ずチャンク分割を行いましょう。分割したチャンクを並列処理し、最後に結果をマージする高度なパターンもあります。
- 出力形式の固定:
response_formatでJSON出力を指定できるモデルを積極的に利用し、出力の安定性を高めましょう。パースに失敗した場合は再試行するか、人手での確認へエスカレーションする分岐を入れると堅牢になります。 - 失敗通知: ワークフローが失敗した場合は、エラー内容と元のリクエスト情報をSlackやメールに通知し、後から原因調査や手動での再実行が可能なように設計します。
実装ガイド2:自然言語でワークフローを起動する(MCP活用)
次に、より未来的なユースケースとして、デスクトップAIクライアントから自然言語でn8nのワークフローを起動する方法を紹介します。例えば、「今日の会議の議事録を作成して」と話しかけるだけで、n8nが議事録生成フローを自動で実行するイメージです。
目的とコンセプト:「会議を開始」で自動化を始動
これは、MCP(Model Context Protocol)という仕組みに対応したツールを介して実現されます。ユーザーがAIに指示を出すと、AIはそれが特定のツール(この場合はn8nのWebhookを呼び出すこと)を実行すべきだと判断し、バックグラウンドでHTTPリクエストを送信します。
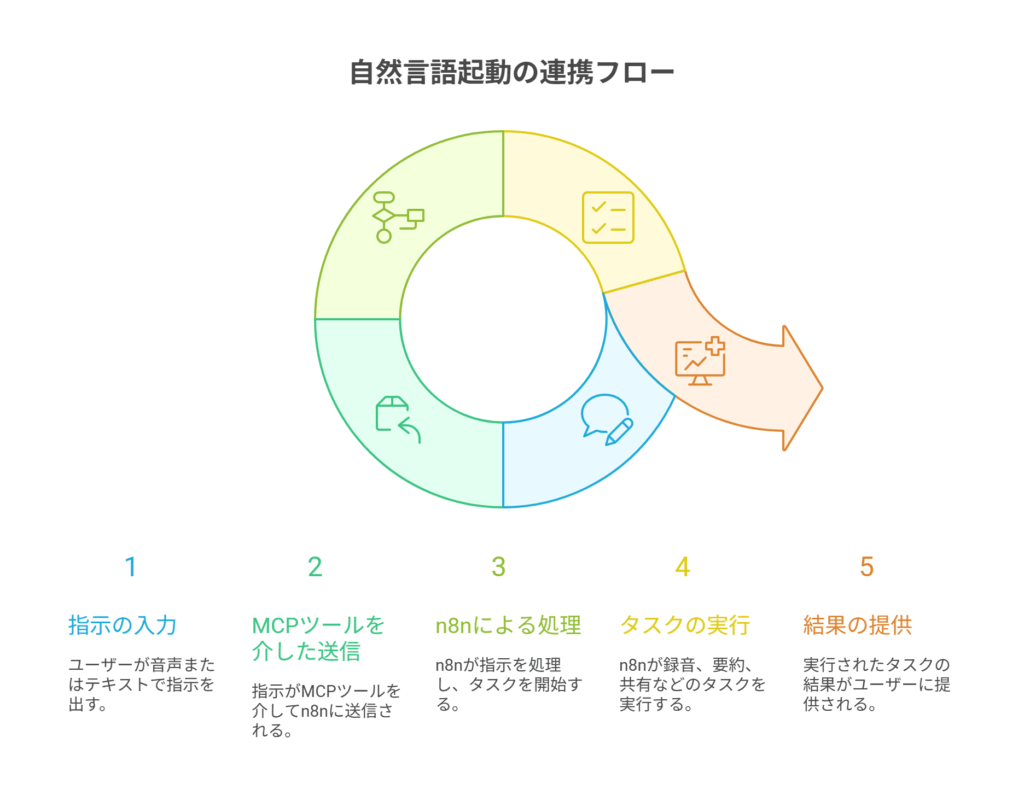
実装の考え方
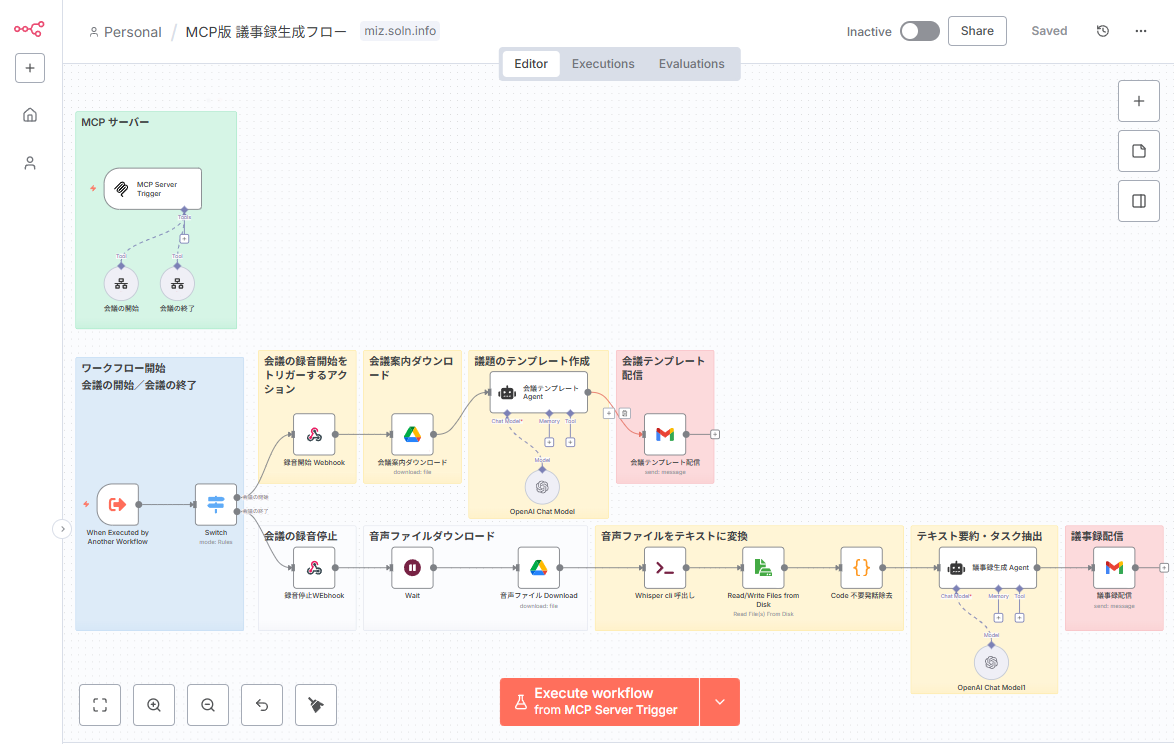
- n8n側:
Webhookノードを/meeting/startのような意味のあるパスで公開します。- セキュリティのため、Basic認証や、リクエストヘッダーに含まれる秘密キーを検証するロジックを入れます。
- Webhookの後続には、会議の録音開始をトリガーするアクション、議題のテンプレートを参加者に送付するアクション、会議終了後に音声ファイルを要約してタスクを抽出し、議事録として配信する一連のフローを接続します。
- MCP側(デスクトップAIクライアントの設定):
- 「会議を開始する」という意図を検知したら、n8nのWebhookを呼び出すツールを定義します。
- ツール名:
start_meeting - 引数:
{ \"title\": \"会議のタイトル\", \"participants\": [\"参加者のメールアドレス\"] } - 処理内容:
https://<あなたのn8nドメイン>/webhook/meeting/startに、引数をJSONボディとしてPOSTする。
セキュリティ上のポイント
n8nのWebhook URLはインターネットに公開されるため、誰でも叩ける状態は危険です。固定の認証トークンをヘッダーに含めることを必須にしたり、送信元のIPアドレスを制限したりするなど、適切な保護策を講じましょう。AIクライアント側に秘密情報を埋め込む場合は、その情報が漏洩しないよう厳重な管理が必要です。
実装ガイド3:コンテンツ自動生成・公開(常時稼働を無料枠で)
AIの得意分野であるコンテンツ生成を、n8nで自動化するワークフローです。24時間365日、指定したテーマに関する情報を収集し、記事を自動生成してWordPressに下書きとして投稿し続けるシステムを構築します。
目的と構成例
- 目的: 24/7でテーマ別の記事を自動作成し、WordPressへ下書き投稿する。
- 構成例:
- n8n: 全体の司令塔
- Ollama: ローカルAI推論エンジン(無料枠のVM上や自宅サーバーで稼働)
- Uptime Kuma: n8nとOllamaの死活監視
- WordPress: コンテンツの公開先
- スケジューラ: n8n内蔵のCronノード、または外部のcronジョブ
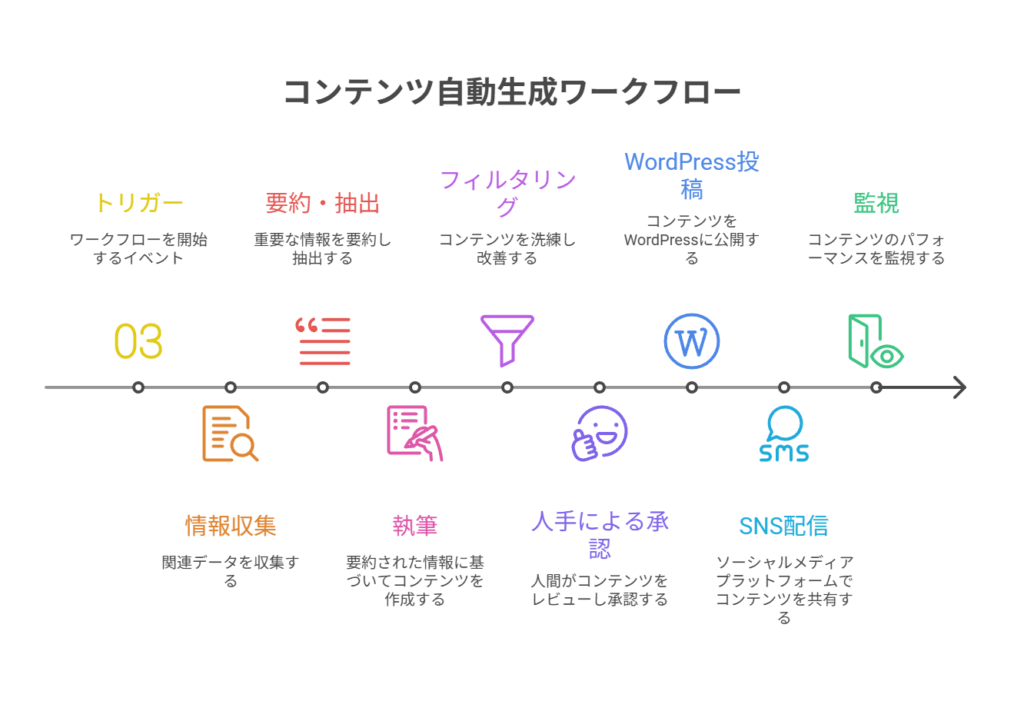
ワークフローの具体的な手順
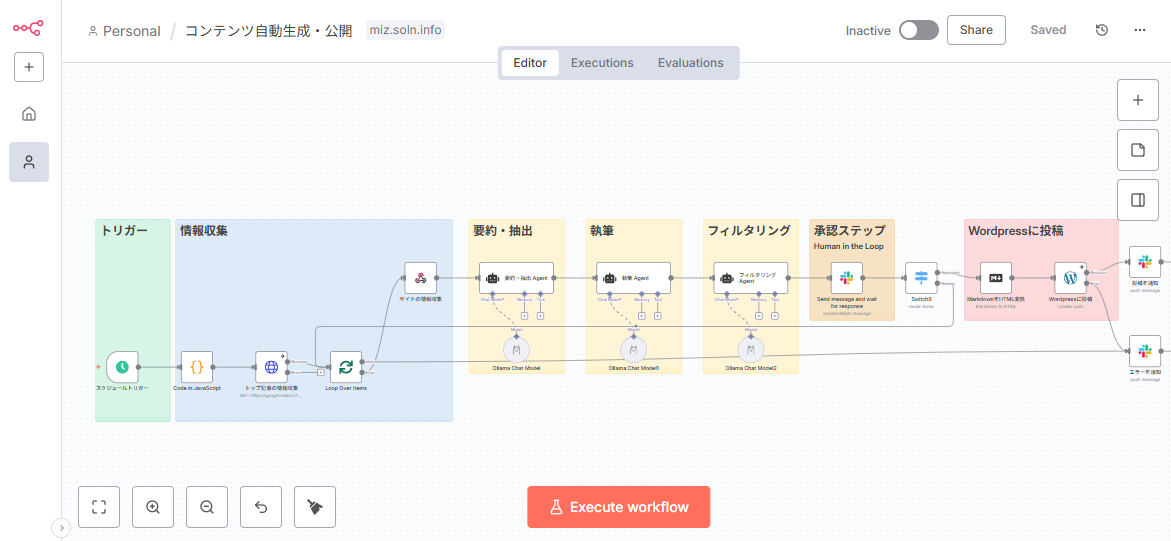
- トリガー:
Schedule Triggerノードで、例えば「毎朝9時」に実行するよう設定。 - 情報収集:
HTTP RequestやRSS Feed Readノードを使い、関連ニュースサイトや検索APIから最新の話題を収集。 - 要約・抽出: 収集した情報をAIに渡し、重要ポイントを抽出・要約させる。
- 執筆: 抽出したポイントを元に、別のプロンプトで記事全体(見出し、導入文、本文、CTA、メタ情報)の下書きを生成させる。
- フィルタリング: Code ノードやAIを使い、生成された文章に不適切な単語、権利を侵害する可能性のある表現、個人情報などが含まれていないかチェック。
- 承認ステップ:
SlackノードのSend and Wait for Responseを使い、生成された記事のプレビューと「承認」「修正依頼」ボタンを管理者に送信。この「Human-in-the-Loop」が品質を担保します。 - 投稿: 承認されたら、
WordPressノードまたはHTTP RequestノードでWordPress REST APIを叩き、下書きとして記事を投稿。 - 配信・後処理: 投稿成功後、SNSへの投稿予約や、サイトマップの更新通知などを実行。
- 監視: 各ステップでエラーが発生した場合、管理者に即座に通知する。
WordPressへの自動投稿(HTTP Requestノード例)
WordPress ノードを使うのが簡単ですが、より細かい制御をしたい場合は HTTP Request ノードで直接APIを呼び出します。
Method: POSTURL:https://your-domain.com/wp-json/wp/v2/postsAuthentication:Header Authを使い、WordPressの「アプリケーションパスワード」をBearerトークンとして送信します。Body Parameters(RAW JSON):
{
\"title\": \"{{ $json.title }}\",
\"content\": \"{{ $json.htmlContent }}\",
\"status\": \"draft\",
\"categories\": [{{ $json.categoryId }}],
\"tags\": [{{ $json.tagIds.join(',') }}]
}AI推論APIを使いこなす:実用パターンとプロンプト設計
APIをただ呼び出すだけでは、AIの能力を最大限に引き出すことはできません。ここでは、より安定して高品質な結果を得るための実践的なテクニックを紹介します。
API呼び出しの基本パラメータ
- 温度 (temperature): 0に近いほど決定的で一貫した出力、1に近いほど創造的で多様な出力になります。業務自動化では、安定性を重視して0.2~0.5程度に設定するのが無難です。
- JSON出力 (response_format): 対応しているAPIでは、
response_formatを{ \"type\": \"json_object\" }に設定することで、出力が必ず有効なJSONになるよう強制できます。これにより、後続の処理でのパースエラーを劇的に減らせます。 - ストリーミング (stream): 長文を生成する場合、
stream: trueに設定すると、結果が一度に返ってくるのではなく、トークン単位で段階的に送られてきます。リアルタイム性が求められるチャットボットなどで有効ですが、n8nで扱うにはカスタムロジックが必要になる場合があります。 - 関数呼び出し / ツール使用 (function calling / tool use): モデルがAPIの応答として、次に呼び出すべき関数(ツール)とその引数を返す機能です。これにより、モデルの判断に応じてn8nのワークフローを動的に分岐させることが可能になります。
デバッグに役立つcURLサンプル
ワークフローがうまく動かない時、まずはcURLコマンドでAPIが直接叩けるかを確認するのが定石です。
- OpenAI互換API (cURL):
curl https://api.openai.com/v1/chat/completions \\
-H \"Authorization: Bearer $OPENAI_API_KEY\" \\
-H \"Content-Type: application/json\" \\
-d '{
\"model\": \"gpt-4o-mini\",
\"messages\": [
{\"role\": \"system\", \"content\": \"あなたは日本語の専門家です。\"},
{\"role\": \"user\", \"content\": \"このテキストを3つのポイントで要約してください: ...\"}
],
\"temperature\": 0.2
}'- Ollama (cURL):
curl http://localhost:11434/api/chat \\
-H \"Content-Type: application/json\" \\
-d '{
\"model\": \"llama3\",
\"messages\": [
{\"role\":\"user\",\"content\":\"このテキストを日本語で要約してください: ...\"}
],
\"stream\": false
}'設計の核:日本語業務に最適化するプロンプト設計と検証
高品質な出力を得るための最も重要な要素は、プロンプトの設計です。
- システムメッセージで役割と制約を定義:
- 「あなたは厳密で簡潔な日本語の要約者です。」のように役割を明確に与えます。
- 「事実に基づかない推測はしないでください。」「出力は必ず指定のJSONスキーマに従ってください。」といった制約条件を課します。
- ユーザーメッセージに具体的指示と例を含める:
- 「以下を日本語で3点要約し、重要キーワードを5個抽出してください。」のように、何をすべきか具体的に指示します。
- 期待する出力形式が複雑な場合は、例(Few-shot)やJSONスキーマを直接プロンプトに埋め込みます。
- 出力のバリデーションを徹底する:
- AIからの応答を受け取ったら、必ずプログラムで検証します。JSONであれば
JSON.parseが成功するか、期待するキーが存在するか、値の型が正しいかなどをチェックします。 - 検証に失敗した場合は、自動で再試行するロジックを組み込みます。その際、「前回の出力はJSONとして不正でした。修正してください。」といったフィードバックをプロンプトに追加すると、成功率が上がります。
- AIからの応答を受け取ったら、必ずプログラムで検証します。JSONであれば
- 日本語特有の調整:
- 敬体(です・ます調)と常体(だ・である調)のどちらで出力すべきか、明確に指示します。
- 語尾やトーン、スタイルガイドがある場合は、それもシステムメッセージに含めます。
本番運用への道:セキュリティとコンプライアンス
プロトタイプを動かすことと、本番環境で安全に運用することは全く別の課題です。特に日本国内で業務利用する場合、セキュリティと法規制への配慮は必須です。
Webhookを保護する3つの方法
- Basic認証: 最も手軽な方法。Webhookノードでユーザー名とパスワードを設定します。
- HMAC署名検証: GitHubのWebhookなどで使われる堅牢な方法。リクエスト送信側が、リクエストボディと秘密キーを使って計算したハッシュ値(署名)をヘッダーに付与します。n8n側では、同じ計算を行って署名が一致するかを検証し、改ざんやなりすましを防ぎます。
- IP許可リスト: 送信元のIPアドレスが固定されている場合に有効。n8nをホストしているサーバーのファイアウォールやリバースプロキシで、許可されたIPアドレスからのアクセスのみを受け付けるように設定します。
資格情報(APIキー)の安全な管理
APIキーやパスワードなどの秘密情報は、ワークフロー内に直接書き込んではいけません。
- n8nのCredentials機能: 最も推奨される方法。暗号化された状態でデータベースに保存され、ワークフローからは
{{ $credentials.credentialName.keyName }}のような式で安全に参照できます。 - 環境変数: サーバーの環境変数として設定し、ワークフローから参照します。Dockerで運用する場合、
docker-compose.ymlファイルなどで管理します。 - 注意: ワークフローをJSONとしてエクスポートする際、誤って秘密情報が含まれないように注意が必要です。
日本の個人情報保護法(APPI)準拠のためのデータガバナンス
AIに個人情報を含むデータを渡す際は、個人情報保護法への準拠が絶対条件です。
- データ最小化の原則: ワークフローで扱う個人情報は、処理に必要な最小限に留めます。可能であれば、AIに渡す前に匿名化や仮名化処理を施します。
- 利用目的の明確化と同意: 個人情報を取得する際には、その利用目的(AIによる処理を含む)を本人に明示し、適切な同意を得る必要があります。
- ログ管理: 誰が、いつ、どのデータにアクセスし、どう処理したかのログを記録し、監査に備える必要があります。ログに個人情報が平文で残る設計は避け、暗号化や保持期間の設定を行いましょう。
- サプライヤーリスクの評価: 外部のクラウドAIサービスを利用する場合、その事業者の利用規約やデータプライバシーポリシーを精査し、データがどのように扱われるか(学習データとして利用されないかなど)を確認する必要があります。
ローカルAIがもたらすセキュリティ上のメリット
機密性の高い情報を扱う場合、Ollamaなどを使ってローカル環境でAIを動かすことは非常に有効な選択肢です。
- 機密保持: データを外部のサーバーに送信する必要が一切ないため、情報漏洩のリスクを根本的に断ち切れます。
- コスト予測: 従量課金ではないため、処理量が増えてもコストが変動せず、予算管理が容易になります。
- 低レイテンシ: ネットワークの遅延がないため、高速な応答が期待できます。
ただし、モデルのアップデートや性能チューニング、サーバーリソースの管理といった運用コストは自己負担となる点を考慮する必要があります。
安定稼働を実現する運用ベストプラクティス
動くものを作った後は、それを安定して動かし続けるための「運用」のフェーズに入ります。ここでは、本番環境で必須となるベストプラクティスを紹介します。
[図3:監視とエラーハンドリング](代替テキスト:ワークフローの実行中にエラーが発生した場合、まず指数バックオフで数回再試行し、それでも失敗した場合はデッドレターキューに処理を移して管理者に通知する、という関係性を描いた図。)
スケールする実行基盤(DB+キュー構成)
小規模なテスト運用はデフォルトのSQLiteデータベースでも可能ですが、本番環境ではより堅牢な構成が推奨されます。
- データベース: PostgreSQLなどの外部データベースを利用することで、データの信頼性とパフォーマンスが向上します。
- キュー: Redisなどのキューイングシステムを導入し、
queueモードでn8nを起動すると、大量のワークフロー実行リクエストを一度キューに溜め、ワーカープロセスが順次処理するようになります。これにより、突発的な負荷急増(スパイク)にも耐えられるようになり、システム全体の安定性が向上します。 - 暗号化キー: 複数のn8nインスタンスでCredentialsを共有する場合、
N8N_ENCRYPTION_KEY環境変数を必ず設定し、すべてのインスタンスで同じキーを共有する必要があります。
Gitによるワークフローのバージョン管理
ワークフローは重要な資産です。手動でのバックアップは漏れやミスが発生しやすいため、Gitを使ってコードと同様にバージョン管理することを強く推奨します。
- n8nのCLI(コマンドラインインターフェース)ツールを使い、ワークフローのJSONファイルを定期的にエクスポート/インポートするスクリプトを作成します。
- 開発環境、ステージング環境、本番環境でブランチを分け、変更履歴を追いかけられるようにします。
- CI/CDパイプラインを組むことで、Gitへのプッシュをトリガーに、自動でテストを実行したり、本番環境へデプロイしたりすることも可能です。
失敗に強いエラーハンドリング設計
「自動化はいつか必ず失敗する」という前提で設計することが重要です。
- 再試行(リトライ): 外部APIの一時的なエラーなど、時間をおけば回復する可能性のある失敗に対しては、自動で再試行する設定を入れます。その際、毎回同じ間隔でリトライするのではなく、間隔を徐々に広げていく「指数バックオフ」方式が効果的です。
- デッドレター処理: 何度再試行しても成功しない処理は、「デッドレター(失敗した処理)」として別の場所に隔離し、人手による原因調査と対応を促します。
- 冪等性(べきとうせい): Webhookの再送などで同じリクエストが2回来てしまった場合に、処理が2回実行されてしまわないようにする設計です。外部APIが
Idempotency-Keyヘッダーに対応していればそれを活用するか、処理の最初にユニークなIDで実行済みかどうかをデータベースで確認するロジックを入れます。
監視と可観測性:何を計測し、どう改善するか
問題の発生を迅速に検知し、パフォーマンスを継続的に改善するためには、システムの内部状態を可視化することが不可欠です。
- 死活監視: Uptime Kumaなどで、n8nサーバーが正常に応答しているかを定期的にチェックします。
- ログ集約: n8nの実行ログを外部のログ管理システム(例: Loki, Elasticsearch)に転送し、エラーの検索や分析を容易にします。
- 主要KPIの計測:
- 成功率: 全実行回数のうち、成功した割合。
- 平均実行時間: ワークフローが完了するまでの平均時間。
- 1実行あたりのトークン数/コスト: AI呼び出しにかかるコストを把握。
- 失敗原因の上位: どのノードで、どのようなエラーが頻発しているか。
暴走を防ぐコスト管理術
従量課金のAI APIを利用する場合、意図しない大量実行によるコスト暴走は最も避けたいリスクの一つです。
- コスト計算: モデルごとに「1,000トークンあたりの単価」を管理し、ワークフローの実行ログに毎回のおおよそのコストを記録します。
- 上限設定とアラート: 1回の実行で消費するトークン数に上限を設定します。また、月間の累計コストが事前に設定した閾値を超えた場合に、管理者にアラートを飛ばす仕組みを構築します。
Human-in-the-Loop:AIと人間の最適な協業とは
全ての判断をAIに任せるのは危険です。特に、顧客へのメール送信や公開記事の投稿など、クリティカルな処理の前には必ず人間の承認ステップを挟むべきです。
- Slackのボタンやメールの承認リンクをクリックするまで、後続の処理を一時停止させます。
- 承認依頼にはタイムアウトを設定し、一定時間応答がない場合は自動的にキャンセルするか、デフォルトのアクションを実行するように設計します。
次のレベルへ:n8n×AIの拡張戦略
基本をマスターしたら、さらに高度なテクニックで自動化の価値を高めていきましょう。
モデル選定と使い分けの判断基準
[表1:モデル選定の比較軸](代替テキスト:クラウドAPIとローカルAPI(Ollamaなど)の比較表。強み、弱み、日本語性能、コスト、レイテンシ、データプライバシーの観点でそれぞれの特徴がまとめられている。)
| 項目 | クラウドAPI (OpenAI, Anthropic, etc.) | ローカルAPI (Ollama) |
|---|---|---|
| 強み | 最新・最高性能のモデルが利用可能、運用が容易 | 機密保持、予測可能なコスト、低レイテンシ、オフライン利用可 |
| 弱み | コストが変動、データ送信が必須、レート制限あり | モデル性能はクラウドに劣る場合あり、初期セットアップとリソース管理が必要 |
| 日本語性能 | 高い傾向にあるが、モデルによる差が大きい | モデルの選択肢による。日本語特化モデルも利用可能 |
| コスト | 従量課金(トークン単位) | ハードウェアと電気代のみ |
| レイテンシ | ネットワーク遅延がある | 非常に低い |
| データプライバシー | サービス提供者のポリシーに依存 | 非常に高い(外部送信なし) |
使い分けの指針:
- 機密情報: ローカルAPI一択。
- 最高品質のクリエイティブ: 最新のクラウドAPI。
- 大量の定型処理: コスト効率の良い小型のローカルモデルか、安価なクラウドAPI。
- リアルタイム応答: ローカルAPIか、低レイテンシを謳うクラウドAPI。
自社のデータセットで複数のモデルをA/Bテストし、用途ごとに最適なモデルを使い分けるのが理想です。
よくある失敗パターンとその対策
- プロンプトインジェクション: ユーザーからの入力に「これまでの指示をすべて無視して…」といった悪意のある指示が含まれる問題。
- 対策: 入力テキストをサニタイズする、禁止ワードを検出するガードレールを設ける、AIの役割をシステムメッセージで強く固定する。
- 出力の不定形・破損JSON: AIの出力が期待した形式になっていない。
- 対策:
response_formatでJSON出力を強制する、出力後にバリデーションライブラリで検証する、失敗時に「前回の出力は不正でした」とフィードバックして再試行させる。
- 対策:
- レート制限・タイムアウト: 外部APIの呼び出し制限に引っかかる。
- 対策: キューイングでAPI呼び出しの速度を平準化する、指数バックオフによる再試行を実装する、代替モデルへのフェイルオーバー(切り替え)ロジックを用意する。
- 無料枠サーバーの停止: クラウドの無料枠インスタンスが、仕様変更や長期間の無操作で停止・削除される。
- 対策: 定期的にヘルスチェック用のジョブを実行してアクティブ状態を保つ、定期的なバックアップを取得する、有料プランへの移行計画を常に準備しておく。
応用・発展:RAG、多段プロンプト、ツール実行で価値を高める
- RAG (検索拡張生成):
- 社内ドキュメントやマニュアルなどを事前にベクトルデータベース(例: Qdrant, Chroma)に保存しておきます。
- ユーザーからの質問が来たら、まずベクトルDBを検索して関連性の高い情報を取得し、それをプロンプトに含めてAIに渡します。
- これにより、AIは公開情報だけでなく、社内のプライベートな知識に基づいて回答できるようになり、精度が劇的に向上します。
- 多段プロンプトと役割分離:
- 一つの巨大なプロンプトで全ての処理を行わせるのではなく、「情報収集役」「要約役」「校正役」「マーケティングコピーライター役」のように、役割ごとにプロンプトを分けたAIをチェーンのようにつなぎます。
- 各ステップの途中成果物を保存しておくことで、デバッグや再実行が容易になります。
- ツール実行 (関数呼び出し):
- モデル自身に、次に何をすべきかを判断させる高度なテクニック。
- 例えば「今日の東京の天気は?」と聞かれたら、モデルは「
get_weather(city='Tokyo')という関数を呼び出すべきだ」と判断し、その情報を返します。 - n8n側では、その応答を受けて実際に天気APIを呼び出し、得られた結果を再度モデルに渡して自然な文章を生成させます。
実践のためのリソース集
チェックリスト(導入前?運用)
| フェーズ | チェック項目 |
|---|---|
| 技術設計 | [ ] トリガー/前処理/推論/後処理/出力/監視の6層が定義されているか |
| [ ] モデル選定基準(性能/コスト/日本語/速度/ポリシー)が明文化されているか | |
| [ ] 長文はチャンク分割され、最大トークン数が適切に設定されているか | |
| セキュリティ | [ ] Webhookは認証、署名検証、レート制限などで保護されているか |
| [ ] APIキーはCredentials機能と安全な環境変数で管理されているか | |
| [ ] 個人情報の取り扱い方針が定義され、マスキング処理が実装されているか | |
| 運用 | [ ] 再試行、デッドレター、通知のフローが設計されているか |
| [ ] 監視(死活、エラー率、コスト)が可視化されているか | |
| [ ] ワークフローのバージョン管理、移行、バックアップ計画が存在するか | |
| 組織 | [ ] Human-in-the-Loopによる承認プロセスが適切な箇所に導入されているか |
| [ ] 出力の信頼性を担保するため、出典・プロンプト・モデルバージョンを記録しているか | |
| [ ] システム障害時の代替手段(手動オペレーションなど)が用意されているか |
FAQ(よくある質問)
Q1. n8nでAIを呼ぶ時、専用ノードとHTTP Requestノードのどちらが良い?
A. まずはHTTP Requestノードで始めることを強く推奨します。APIの仕組みやパラメータへの理解が深まります。専用ノードは手軽ですが、機能が限定的であったり、APIの最新機能への追随が遅れたりすることがあります。ワークフローの要件が固まり、再利用性が重要になった段階で、専用のカスタムノード開発を検討するのが良いでしょう。
Q2. ローカルのOllamaはCPUでも動きますか?
A. はい、動きます。ただし、応答速度はモデルのサイズに大きく依存します。高速な応答が不要なバッチ処理や、非同期での実行であれば、CPUでも十分に実用的です。小型化・高速化された量子化モデルを選択することも有効です。
Q3. 日本語の要約が不自然になったり、内容が崩れたりする原因は?
A. 主な原因は、(1)コンテキスト不足、(2)チャンク分割の境界が不適切、(3)温度設定が高すぎる、(4)日本語の禁則処理に対応していないモデル、などが考えられます。対策として、システムメッセージで役割を厳密に定義し、チャンク分割時に見出しや段落番号などの文脈情報を付与することが有効です。
Q4. Webhookをインターネットに直接公開したくありません。
A. いくつか方法があります。社内ネットワークからのみアクセスできるようにVPNやリバースプロキシでIP制限をかけるのが一つです。また、直接Webhookを叩くのではなく、Amazon SQSやRabbitMQのようなメッセージキューを介してイベントを受け渡し、n8nはキューをポーリングするように設計することもできます。
Q5. 無料枠での24/7運用は本当に安定しますか?
A. 「条件次第で可能」というのが正直な答えです。クラウドプロバイダーのポリシーは予告なく変更される可能性があるため、無料枠はあくまで実験や学習用途と割り切り、ミッションクリティカルな本番システムは、課金を前提としたスモールスタートから始めるのが現実的です。
結論:AI自動化を成功させるためのロードマップ
本記事では、n8nとAI推論APIを組み合わせた業務自動化について、設計思想から実装、そして本番運用に至るまでの具体的なノウハウを網羅的に解説してきました。
本記事の要点
- n8nは、AI推論APIを中核に据えた業務自動化を構築するための「現実的な選択肢」です。自己ホスティングにより、データ主権とコスト効率を両立できます。
- 実装は「トリガー → 推論 → 整形 → 出力」というシンプルな4点セットから始め、徐々にガードレール(検証)、承認プロセス、監視といった堅牢性を高める要素を追加していくのが王道です。
- 無料枠やローカルAIを活用して低コストで実験を重ねつつ、品質の要となるのはプロンプト設計、出力の検証、そして「Human-in-the-Loop」の思想であることを忘れないでください。
- MCPによる自然言語起動やRAGによる社内知識の活用など、拡張の可能性は無限大です。常に日本の法規制や商習慣に適合した運用を心がけましょう。
今すぐできる3つのアクションステップ
- ステップ1:ローカルで最小ワークフローを動かす
- Dockerを使ってローカル環境にn8nを起動し、本記事で紹介した「Webhook → AI要約 → Slack通知」の最小フローをまずは自分の手で完成させてみましょう。
- ステップ2:ワークフローを堅牢にする
- 作成したフローに、JSON出力の検証、人手による承認ステップ、エラー発生時の再試行と通知機能を追加し、失敗に強い作りに改良します。
- ステップ3:常時稼働と発信に挑戦する
- 常時稼働できる環境(クラウドの無料枠や社内サーバー)にワークフローをデプロイし、監視ツールを導入します。そして、構築の過程で得た学びや失敗談を「ビルド・イン・パブリック」の精神でチームやコミュニティに発信してみましょう。
よくある誤解を一刀両断
- 「AIが全部やってくれる」は幻想: 業務に耐えうる自動化は「AI × 優れた設計 × 堅実な運用」の掛け算で成り立ちます。人間の判断を介在させることで、AIの価値は最大化されます。
- 「無料枠なら永遠に安泰」は危険: 条件は常に変動します。無料枠はあくまでスタート地点であり、事業の成長に合わせた移行計画とバックアップ戦略は常に用意しておくべきです。
- 「高性能モデル一択」は思考停止: 用途に応じてモデルは適材適所です。コスト効率の良い小型モデルと、優れたプロンプト設計の工夫で十分な成果を出せる場面は数多く存在します。
n8nとAI推論APIの組み合わせは、単なる作業の自動化を超え、組織の「意思決定プロセス」そのものを拡張するポテンシャルを秘めています。最小構成で素早く価値を実証し、徐々に堅牢性を高め、チームに馴染ませていく。この順序で着実に進めれば、数週間後にはあなたの手元に“本当に使えるAI自動化”の仕組みが残るはずです。
まずは、小さく、速く、そして安全に。この記事のテンプレートを参考に、あなたの現場の課題解決に向けた第一歩を踏み出してください。

