

- 1 n8n × Nextcloud × プラグイン連携 完全ガイド:Ubuntuセルフホストで実運用を回すための設計・構築・運用ベストプラクティス
- 2 はじめに:この記事で解決できること
- 3 1. 基礎理解:n8n × Nextcloud × Ubuntu セルフホストの全体像
- 4 2. 実践ガイド:セットアップからワークフロー構築まで
- 5 3. 主要ユースケース別ハンズオン
- 6 4. プラグイン・拡張:Community Nodesとカスタムノード
- 7 5. 運用ベストプラクティス(信頼性・可観測性・セキュリティ)
- 8 6. パフォーマンス最適化:DB・Queue・I/O
- 9 7. よくある誤解・失敗と対策
- 10 8. まとめと次のアクション
n8n × Nextcloud × プラグイン連携 完全ガイド:Ubuntuセルフホストで実運用を回すための設計・構築・運用ベストプラクティス
はじめに:この記事で解決できること
「n8nを使ってNextcloudのファイル運用を自動化したい」
「ローカル(Ubuntu)で動かしているn8nを、Redis・PostgreSQL・pgvectorと統合して本格運用したい」
「プラグインや拡張機能を活用して、ワークフローを自社の要件に最適化したい」
もしあなたがこのような課題を抱えるエンジニアなら、この記事はまさにうってつけです。本稿では、n8n v1.115.0以上の安定版を前提に、Ubuntu上にセルフホストしたn8nとNextcloudを中心に、ngrok、PostgreSQL(pgvector拡張)、Redisを組み合わせた堅牢な自動化基盤を構築・運用するためのノウハウを網羅的に解説します。
単なる機能紹介に留まらず、企画・設計思想から具体的な構築手順、そして実運用で必ず直面する信頼性やパフォーマンスの課題まで、現場で本当に役立つベストプラクティスを凝縮しました。この記事を最後まで読めば、あなたのn8n環境を「面白いおもちゃ」から「止まらない業務基盤」へと昇華させるための、確かな知見と具体的な手順をすべて手に入れることができるでしょう。
要点サマリ(先に結論から)
この記事で解説するベストプラクティスの核心を、先に箇条書きでご紹介します。
- 推奨アーキテクチャ: n8nをqueueモード(Redis利用)で運用し、永続化DBとしてPostgreSQL、セマンティック検索基盤としてpgvectorを組み合わせるのが、中長期的な拡張性と安定性に最も優れています。
環境変数のWEBHOOK_TUNNEL_URLとWEBHOOK_URLとを正しく設定し、ngrokで外部からのイベント受信と社内のイントラネットを安全に運用する構成が基本です。 - Nextcloud連携の王道パターン: 連携には大きく分けて2つのアプローチがあります。まずは堅実なCron+ポーリングで安定稼働を実現し、次にリアルタイム性が求められる要件に対してNextcloudフロー+Webhook(イベント駆動型)へ移行するのが失敗の少ない進め方です。
- ファイル自動化の黄金ルート:
メール添付の自動保存→命名規則に基づくフォルダ整流化→共有リンクの自動発行→関係者への通知という一連の流れは、多くの業務で応用可能です。このとき、バイナリデータの適切な扱いとファイル名の衝突回避が成功の鍵を握ります。 - 知的検索の実装指針: pgvectorに文書の埋め込みベクトルを保持し、類似度検索(cosine)で関連文書の候補を取得。その後、AIによる要約やメタデータで再ランキングする手法が有効です。パフォーマンスを確保するために、
ivfflatやHNSWといった索引の作成は必須です。 - プラグイン拡張の安全運用: Community Nodesは非常に強力ですが、ホワイトリスト方式での運用とステージング環境での十分な検証を徹底すべきです。
N8N_ENCRYPTION_KEYによる資格情報保護、EXECUTIONS_DATA_*による実行データ管理、DIAGNOSTICSの無効化といったセキュリティ設定は必ず行いましょう。 - 本番運用の勘所: ワークフローの信頼性を高めるリトライ処理とデッドレターキューの設計、
/healthzエンドポイントとメトリクスによる監視、DB・.n8nディレクトリ・Nextcloudの三位一体でのバックアップ、そしてRBACと監査ログによるガバナンス強化が不可欠です。API制限に備えたスロットリングも忘れてはなりません。 - 代表的な落とし穴:
WEBHOOK_TUNNEL_URLとWEBHOOK_URLの未設定、エディタでのテスト実行用の/webhook-testの本番誤用、バイナリデータからJSONへの変換漏れ、pgvectorの索引未作成による性能劣化、ngrokの動的URLに対する追従漏れは、多くのユーザーが陥る典型的な失敗です。
それでは、これらの要点を具体的にどのように実現していくのか、詳細に見ていきましょう。
1. 基礎理解:n8n × Nextcloud × Ubuntu セルフホストの全体像
効果的なシステムを構築するためには、まず各コンポーネントの役割と全体のデータフローを正確に理解することが重要です。
1-1. 本記事の前提となる技術スタック
この記事は、以下の環境を前提として解説を進めます。
- n8n: v1.115.0 以上の安定版
- OS: Ubuntu Server(セルフホスト環境)
- 併用サービス:
- ngrok(ローカル環境への安全な外部アクセス経路)
- PostgreSQL(pgvector拡張を有効化)
- Redis(n8nのキューイングシステムとして利用)
- Nextcloud(ファイル管理の中核)
- 想定読者: インフラ、バックエンド、SRE、情シス部門に所属する技術者。DockerまたはLinux上でのサービス運用経験がある方を対象としています。
1-2. 各コンポーネントの役割分担とデータフロー
このアーキテクチャにおいて、それぞれのツールは以下のような役割を担います。
- n8n (オーケストレーター): システム全体の司令塔。ノーコード/ローコードのUIでワークフローを設計・実行します。Webhookによるイベント受信、各種サービスへのAPIコール、データベース操作、ファイルハンドリング、AI APIの呼び出しといった異なる処理を柔軟に結合します。
- Nextcloud (ファイル管理ハブ): ファイル、ユーザー、共有設定の中心的な管理基盤。WebDAVプロトコルをベースとしたファイル操作に優れており、「Flow」アプリなどを活用したファイルイベントをトリガーにしたWebhook送信や「Flow」アプリを活用したチャット・通知によるWebhook連携や「Forms」アプリを活用した申請内容をn8nで受信 → 自動処理・通知・記録等も可能です。
- PostgreSQL + pgvector (永続化・検索): n8nのワークフロー実行履歴や、業務で扱う構造化データを永続的に保存します。pgvector拡張により、文書の埋め込みベクトルを保存し、高速な近似近傍探索(セマンティック検索)を実現します。
- Redis (ジョブキュー): n8nを
queueモードで運用する際の心臓部。実行されるべきジョブを一時的に保持し、Workerプロセスに順次渡す役割を担います。これにより、システムのスケールアウトと、突発的な高負荷に対する耐性が飛躍的に向上します。 - ngrok (セキュアなトンネル): ローカルネットワーク内で稼働するn8nに対して、インターネット側から安全にアクセスするための公開URLを提供します。Nextcloudや外部SaaSからのWebhookイベントを受信するためには、事実上必須のツールです。
1-3. 典型的な推奨アーキテクチャ
これらのコンポーネントを組み合わせた、推奨アーキテクチャの構成は以下のようになります。
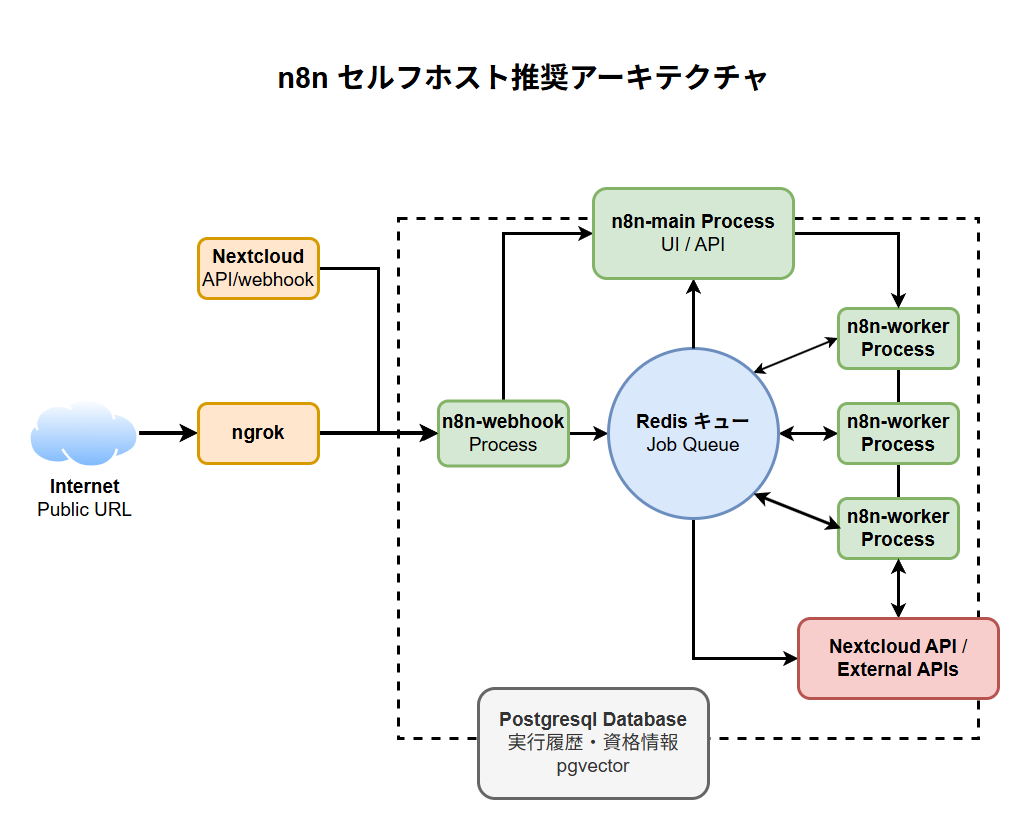
この構成により、UIの応答性とバックグラウンド処理の実行性能を分離し、スケーラブルで信頼性の高い自動化基盤を構築できます。
2. 実践ガイド:セットアップからワークフロー構築まで
理論を理解したところで、次は実際に手を動かして環境を構築していきましょう。
2-1. 事前チェックと推奨設定(Ubuntu)
まず、ホストとなるUbuntuサーバーの準備をします。
- OSの最新化:
bash sudo apt update && sudo apt upgrade -y - Docker/Docker Composeの導入 (推奨):
本番運用ではコンテナ化が管理を容易にします。公式ドキュメントに従い、DockerとDocker Composeをインストールしてください。 - ポートの確認:
n8n (デフォルト: 5678), PostgreSQL (5432), Redis (6379) が使用するポートを把握しておきます。これらのポートは原則として外部に直接公開せず、ngrokやリバースプロキシ経由でのアクセスを基本とします。 - DNS/SSL:
本番環境では必ずTLSによる暗号化が必須です。ngrokのTLS機能を利用するか、自前のドメインとリバースプロキシ(Caddy, Nginxなど)でSSL証明書を設定します。
n8nの必須環境変数
n8nの動作は環境変数によって細かく制御されます。以下は、本番運用で設定すべき最重要の変数リストです。
N8N_ENCRYPTION_KEY: 資格情報(Credentials)を暗号化するためのキー。32文字以上のランダムな文字列を設定し、厳重に管理してください。これを失うと、保存した資格情報がすべて復号できなくなります。EXECUTIONS_MODE=queue: パフォーマンスと安定性のために、必ずQueueモードを指定します。DB_TYPE=postgresdb: データベースにPostgreSQLを使用することを宣言します。DB_POSTGRESDB_*: PostgreSQLへの接続情報(ホスト、ポート、ユーザー名、パスワード、DB名)を設定します。QUEUE_BULL_REDIS_*: Redisへの接続情報を設定します。WEBHOOK_TUNNEL_URL=https://<あなたの公開URL>: 最重要項目の一つ。 n8nがWebhookのURLを生成する際に使用するベースURLです。ngrokで取得したドメインや、自社のFQDNをhttpsプロトコルで指定します。WEBHOOK_URL=http://n8n.internal.local:5678/: n8nが社内lANからのアクセス用のWebhookのURLを生成する際に使用するベースURLです。N8N_HOST,N8N_PORT,N8N_PROTOCOL: n8nがリッスンするホストやポート、プロトコルを指定します。リバースプロキシ配下ではN8N_EDITOR_BASE_URLも必要になる場合があります。N8N_METRICS=true: Prometheus形式でメトリクスを公開する場合に有効化します。EXECUTIONS_DATA_SAVE_ON_SUCCESS=summary: ワークフロー成功時の実行データ保存量を最小限(サマリーのみ)にし、DBの肥大化を防ぎます。EXECUTIONS_DATA_SAVE_ON_ERROR=all: 失敗時はデバッグのため、全てのデータを保存します。EXECUTIONS_DATA_PRUNE=true: 古い実行データを自動的に削除する機能を有効化します。EXECUTIONS_DATA_MAX_AGE=336: 実行データの保持期間を時間単位で指定します(例: 336時間 = 14日間)。
補足: /webhook と /webhook-test の違い
n8nにはWebhookエンドポイントが2種類あります。
/webhook-test: ワークフローエディタ上で「Listen for test event」をクリックした際に使用される、手動テスト専用のエンドポイントです。/webhook: ワークフローを有効化(Active)した後に使用される、本番用のエンドポイントです。WEBHOOK_URLの設定と合わせて、これらの違いを理解し、本番では必ず/webhookパスを含むURLを外部サービスに登録してください。
2-2. コンテナ運用の標準テンプレート(Docker Compose 例)
以下のdocker-compose.ymlは、前述の推奨アーキテクチャを実装するためのテンプレートです。環境に合わせて値を書き換えてご利用ください。
version: '3.8'
services:
postgres:
image: postgres:15
restart: always
environment:
- POSTGRES_USER=n8n
- POSTGRES_PASSWORD=your_strong_password_here
- POSTGRES_DB=n8n
volumes:
- pgdata:/var/lib/postgresql/data
healthcheck:
test: [\"CMD-SHELL\", \"pg_isready -U n8n -d n8n\"]
interval: 5s
timeout: 5s
retries: 10
redis:
image: redis:7
restart: always
command: [\"redis-server\", \"--appendonly\", \"yes\"]
volumes:
- redisdata:/data
healthcheck:
test: [\"CMD\", \"redis-cli\", \"ping\"]
interval: 5s
timeout: 5s
retries: 10
n8n-main:
image: n8nio/n8n:1.113.0
restart: always
ports:
- \"127.0.0.1:5678:5678\"
environment:
- N8N_ENCRYPTION_KEY=change_me_to_a_very_long_and_random_string
- DB_TYPE=postgresdb
- DB_POSTGRESDB_HOST=postgres
- DB_POSTGRESDB_PORT=5432
- DB_POSTGRESDB_DATABASE=n8n
- DB_POSTGRESDB_USER=n8n
- DB_POSTGRESDB_PASSWORD=your_strong_password_here
- EXECUTIONS_MODE=queue
- QUEUE_BULL_REDIS_HOST=redis
- QUEUE_BULL_REDIS_PORT=6379
- N8N_PROTOCOL=https
- N8N_HOST=0.0.0.0 # 社内LANからの接続も行う場合
- WEBHOOK_URL=http://n8n.internal.local:5678 # ここを必ず設定
- WEBHOOK_TUNNEL_URL=https://<your-ngrok-or-fqdn> # ここを必ず設定
- N8N_METRICS=true
- EXECUTIONS_DATA_SAVE_ON_SUCCESS=summary
- EXECUTIONS_DATA_SAVE_ON_ERROR=all
- EXECUTIONS_DATA_PRUNE=true
- EXECUTIONS_DATA_MAX_AGE=336
- N8N_COMMUNITY_NODES_ENABLED=true # Community Nodesを使う場合
volumes:
- n8n_data:/home/node/.n8n
depends_on:
postgres:
condition: service_healthy
redis:
condition: service_healthy
n8n-worker:
image: n8nio/n8n:1.113.0
restart: always
command: n8n worker
environment:
- N8N_ENCRYPTION_KEY=change_me_to_a_very_long_and_random_string
- DB_TYPE=postgresdb
- DB_POSTGRESDB_HOST=postgres
# ... (mainと同様のDB, Redis設定)
volumes:
- n8n_data:/home/node/.n8n
deploy:
replicas: 4 # ← ここでワーカーのレプリカ数を指定
depends_on:
- n8n-main
n8n-webhook:
image: n8nio/n8n:1.113.0
restart: always
command: n8n webhook
environment:
- N8N_ENCRYPTION_KEY=change_me_to_a_very_long_and_random_string
- DB_TYPE=postgresdb
# ... (mainと同様のDB, Redis, WEBHOOK_URL設定)
volumes:
- n8n_data:/home/node/.n8n
depends_on:
- n8n-main
volumes:
n8n_data:
pgdata:
redisdata:ポイント:
main(UI/API)、worker(ジョブ実行)、webhook(Webhook受信)のプロセスを分離することで、耐障害性とスケーラビリティが向上します。特に負荷が高い場合は、n8n-workerのレプリカ数を増やすことで、並列処理能力を強化できます。WEBHOOK_TUNNEL_URLは外部から到達可能なFQDN(ngrokのドメインでも可)を常に最新の状態に保つ必要があります。(ngrokの無料プランは再起動のたびにURLが変わるため、)本番運用では固定サブドメインが使える有料プランの利用や、URL変更を自動で検知・更新するスクリプトの導入を検討しましょう。
2-3. ngrok の設定
ローカル環境のn8nを外部に公開するために、ngrokを設定します。
- ngrokのアカウントを作成し、認証トークンを取得します。
ngrok config add-authtoken <your_token>を実行してトークンを設定します。ngrok http 5678を実行し、n8nのポートを公開します。- コンソールに表示される
httpsから始まるForwarding URLをコピーし、n8nのWEBHOOK_TUNNEL_URL環境変数に設定します。 - Nextcloudやその他の外部SaaSのWebhook設定画面で、エンドポイントとして
https://<ngrokのURL>/webhook/<ワークフロー固有パス>を登録します。
2-4. PostgreSQL(pgvector)の準備
セマンティック検索機能を活用するために、PostgreSQLでpgvector拡張を有効化します。
- PostgreSQLに接続し、スーパーユーザー権限で拡張を有効化します。
CREATE EXTENSION IF NOT EXISTS vector;- 文書データを保存するためのテーブルを作成します。埋め込みベクトルの次元数(例:
1536)は、使用するAIモデルに合わせてください。
CREATE TABLE IF NOT EXISTS docs (
id BIGSERIAL PRIMARY KEY,
path TEXT NOT NULL UNIQUE, -- Nextcloud上のファイルパスなど
mime TEXT,
content TEXT, -- 抽出したテキスト
embedding VECTOR(1536), -- 埋め込みベクトル
updated_at TIMESTAMPTZ DEFAULT now()
);- 高速な近似近傍探索のために、索引を作成します。
listsの値はデータ件数の平方根あたりを目安に調整します。
-- データ投入後に実行するのが望ましい
CREATE INDEX IF NOT EXISTS docs_embedding_idx
ON docs USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);
-- 統計情報を更新
ANALYZE docs;注意: ivfflat索引は、クラスタリングの品質を高めるため、ある程度のデータ(数千?数万件)をテーブルに投入した後に作成するのが定石です。また、pgvectorのバージョンによっては、より高性能なHNSW索引が利用できる場合もあります。
2-5. Nextcloud の資格情報(n8n 側)
n8nからNextcloudに接続するための認証情報を設定します。
- Nextcloudにログインし、「設定」→「セキュリティ」→「アプパスワード」から、n8n専用のアプリパスワードを新規作成します。表示されたパスワードは一度しか見れないため、安全な場所にコピーしてください。
- n8nのUIで「Credentials」→「Add credential」を選択し、「Nextcloud」を検索します。
- 以下の情報を入力します。
- Base URL: あなたのNextcloudのURL(例:
https://nextcloud.example.com) - Authentication:
User/App Passwordを選択 - User: あなたのNextcloudのユーザー名
- App Password: 先ほど生成したアプリパスワード
- Base URL: あなたのNextcloudのURL(例:
- 「Test」ボタンをクリックし、接続が成功することを確認してから保存します。
これで、自動化基盤の準備は完了です。
3. 主要ユースケース別ハンズオン
構築した基盤を使って、実践的なワークフローを組み立てていきましょう。
3-1. 基本形:Cron × Nextcloud ファイル整流化(安全・堅牢)
目的: 毎時、特定のフォルダにアップロードされた新規ファイルを検出し、社内ルールに基づいた名前にリネームし、日付ごとのフォルダへ移動させます。完了後、共有リンクを生成して関係者に通知します。
ワークフロー構成:
- Trigger:
Cronノードを設定し、実行間隔を「Every Hour」にします。 - Nextcloud:
List Filesノードを使い、対象フォルダを指定します。「Options」→「Updated Since」に{{$now.minus({hours:1}).toISO()}}のような式を入力し、直近1時間以内に更新されたファイルのみを差分取得します。 - IF / Filter:
IFノードやSplit In Batchesノードを使い、後続の処理をファイルごとに行います。ファイル種別(MIMEタイプや拡張子)で処理対象を絞り込むこともできます。 - (任意) Code:
CodeノードでJavaScriptを使い、ファイル名を正規化します(例: 全角文字を半角に、不要なスペースをアンダースコアに置換)。 - Nextcloud:
Move/Rename Fileノードを使い、新しいファイルパス(例:/Processed/{{$now.toFormat('yyyy/MM/dd')}}/{{$json.newName}})を指定してファイルを移動します。 - Nextcloud:
Create Share Linkノードで、移動後のファイルに対する共有リンクを生成します。有効期限やパスワードを設定し、セキュリティを高めます。 - 通知:
Email,Slack,Chatworkなどのノードを使い、生成した共有リンクを含むメッセージを送信します。
ポイント:
このポーリング方式は、Webhookと比べて実装がシンプルで、イベントの取りこぼしが発生しにくいため、最初のワークフローとして最適です。ファイル名の衝突を避けるため、ファイルハッシュ(SHA-256など)の一部をファイル名に含める設計も有効です。
3-2. 速報性重視:Nextcloud Flow × Webhook(イベント駆動)
目的: 特定のフォルダにファイルがアップロードされた瞬間にワークフローを起動し、即時処理を行います。
準備:
- Nextcloud側で「Workflow (Flow)」アプリと、Webhook送信機能を持つアプリ(例: \”Workflow external scripts\”)を有効化します。
- Nextcloudのフロー設定で、「ファイルが作成されたとき」をトリガーとし、条件(特定のフォルダ内など)を指定し、アクションとして「外部URLを呼び出す」を選択します。
ワークフロー構成:
- Trigger:
Webhookノードを作成します。HTTP MethodはPOSTを選択し、Pathに一意のパス(例:nc/file-created)を設定します。テストURLが生成されるので、これをNextcloudのフロー設定に登録します。 - 後続処理: Webhookで受信したペイロード(ファイルパスやファイルIDなど)を元に、後続のノードで処理を行います。情報が不足している場合は、
Nextcloud: Get Fileノードで詳細情報を取得します。 - 以降の処理は、前述のCronパターンと同様です。
注意点:
- ngrokの無料プランではURLが頻繁に変わるため、本番運用では固定サブドメインの利用が強く推奨されます。URLが変わるたびにNextcloud側の設定も変更する必要があります。
(現在、無料プランで1エンドポイントのみ固定で使えるようですが、制限についてはご確認ください) - ワークフローを有効化した後は、本番用のURL(
/webhook/を含む)をNextcloudに設定し直すことを忘れないでください。
3-3. 定番:メール添付のNextcloud自動保存+共有リンク通知
目的: 特定のメールアドレスに届いたメールの添付ファイルを自動でNextcloudに保存し、共有リンクを生成して通知します。
ワークフロー構成:
- Trigger:
Email (IMAP)ノードを使い、監視対象のメールサーバーとフォルダを設定します。 - Filter: メールの件名や送信元アドレスで処理対象を絞り込みます。
- Split In Batches: 1通のメールに複数の添付ファイルがあるケースに対応するため、このノードで添付ファイルごとに処理を分割します。Batch Sizeは
1に設定し、{{$json.attachments}}を分割対象にします。 - Move Binary Data: n8nでは、ファイルのようなバイナリデータは特別な形式で扱われます。このノードを使い、バイナリデータを後続のノードが扱いやすいように準備します。
- Nextcloud:
Upload a Fileノードを使い、Binary DataをNextcloudにアップロードします。ファイル名は式の機能を使って動的に生成します(例:{{$now.toFormat('yyyyMMdd_HHmmss')}}_{{$json.fileName}})。 - (オプション) Nextcloud:
Create Share Linkノードで共有リンクを生成します。 - 通知:
EmailやSlackノードで、保存完了の旨と共有リンクを通知します。
実装のコツ:
- バイナリデータは
items[x].binaryというプロパティで参照されます。ファイル名などのメタデータはitems[x].json側にあります。式を使ってこれらを組み合わせることが重要です。 - セキュリティの観点から、生成する共有リンクには必ず有効期限とパスワードを設定し、共有範囲を最小限に留めるべきです。
3-4. 価値拡張:pgvectorで文書を検索可能にする
目的: Nextcloudに保存されたPDFやOffice文書の内容をテキスト化し、埋め込みベクトルを生成してPostgreSQL(pgvector)に格納。これにより、自然言語での高速なセマンティック検索を可能にします。
登録パイプライン(ワークフロー)
- Trigger:
CronまたはWebhookで新規・更新ファイルを検知します。 - Nextcloud:
Get Fileノードでファイル本体(バイナリデータ)を取得します。 - テキスト抽出:
Execute Commandノードを使い、サーバーにインストールしたpdftotextやsoffice(LibreOffice)コマンドを実行してテキストを抽出します。- または、
HTTP Requestノードで外部のテキスト抽出APIサービスを呼び出します。
- 埋め込み生成:
HTTP Requestノードを使い、任意の埋め込み生成API(OpenAI, Googleなど)を呼び出します。入力は抽出したテキスト、出力はfloatの配列(ベクトル)です。
- Postgres:
Postgresノードを使い、データベースに登録します。ファイルパスをキーにしたUpsert(ON CONFLICT DO UPDATE)処理が便利です。
INSERT INTO docs (path, mime, content, embedding)
VALUES ($1, $2, $3, $4)
ON CONFLICT (path) DO UPDATE
SET content = EXCLUDED.content,
embedding = EXCLUDED.embedding,
updated_at = now();検索クエリの例(n8nのPostgresノードで実行)
ユーザーからの検索クエリ(例: 「先月のプロジェクトXに関する報告書は?」)を埋め込みベクトル化し、以下のクエリで類似文書を検索します。<=>はコサイン距離を計算する演算子で、値が小さいほど類似度が高いことを意味します。
-- $1に検索クエリから生成したベクトルを渡す
WITH q AS (
SELECT '...'::vector AS v -- ここに検索クエリのベクトル
)
SELECT
id,
path,
mime,
1 - (embedding <=> q.v) AS similarity_score
FROM docs, q
ORDER BY embedding <=> q.v
LIMIT 5;実践のヒント:
- 非常に長い文書は、埋め込みモデルのトークン制限を超える可能性があります。数百~千文字程度のチャンクに分割し、それぞれを別のレコードとして保存する戦略が有効です。
- 検索結果の精度を高めるには、類似度スコアだけでなく、ファイルの更新日やフォルダパスといったメタデータを加味して、後段で再ランキングする処理を追加すると効果的です。
4. プラグイン・拡張:Community Nodesとカスタムノード
n8nの真価は、その拡張性にあります。
4-1. Community Nodesの安全な使い方
n8nには、コミュニティによって開発された多くのノード(Community Nodes)が存在します。これらを活用することで、標準ノードでは対応していないサービスとの連携も可能になります。
- 有効化:
docker-compose.ymlでN8N_COMMUNITY_NODES_ENABLED=trueを設定します。 - インストール: n8nがマウントしているボリューム(例:
/home/node/.n8n/custom)に移動し、npm install <n8n-nodes-xxx>を実行します。
ベストプラクティス:
- いきなり本番に入れない: 必ずステージング環境で十分に動作検証を行い、意図しない挙動やセキュリティリスクがないかを確認します。
- バージョンを固定する:
package.jsonを使い、インストールするノードのバージョンを固定(例:\"n8n-nodes-my-node\": \"1.2.3\")することで、意図しないアップデートによる破壊的変更を防ぎます。 - 素性を確認する: インストール前に、GitHubリポジトリで開発の活発度、Issueの状況、依存ライブラリ、ライセンスを必ず確認しましょう。
4-2. カスタムノードの作り方(概要)
より深いカスタマイズが必要な場合は、自分でノードを作成することも可能です。
例: Nextcloudの特定メタ情報(ETagなど)を軽量に取得するノード
- 目的: 通常の
Get Fileノードはファイル全体をダウンロードしてしまいますが、ファイルの更新チェックだけを行いたい場合、HTTPのHEADリクエストでETagを取得するだけの軽量なノードが欲しくなります。 - 手順概要:
- n8nの公式開発テンプレート (
n8n-node-dev) を使ってプロジェクトの雛形を作成します。 credentialsファイルで、既存のNextcloud資格情報を利用する定義を記述します。- メインの
node.tsファイルに、WebDAVプロトコルに基づいたHEADやPROPFINDリクエストを送信するロジックを実装し、レスポンスヘッダーからETagやContent-Typeなどの情報を抽出して返却するようにします。 - ビルドしたパッケージを、Community Nodesと同様に
customディレクトリに配置してインストールします。
- n8nの公式開発テンプレート (
カスタムノード開発は、共通処理を再利用可能な部品としてカプセル化し、ワークフローの可読性とメンテナンス性を向上させるための強力な手段です。
5. 運用ベストプラクティス(信頼性・可観測性・セキュリティ)
ワークフローを「作って終わり」にしないためには、運用を見据えた設計が不可欠です。
5-1. ジョブ実行の信頼性
- リトライ戦略: 各ノードの「Settings」タブにある「Continue On Fail」は、エラーを無視して処理を続行させるため、乱用は禁物です。代わりに、
Try/CatchサブフローやError Triggerノードを組み合わせ、特定のエラーに対してリトライ処理を実装したり、失敗を明確にハンドリングする設計を心がけましょう。 - デッドレターキュー (DLQ): 何度リトライしても成功しないジョブは、専用のPostgreSQLテーブルやファイルに失敗情報(入力データ、エラーメッセージなど)を記録し、後で手動調査や再処理ができるようにします。
- スロットリング: 連携先のAPIに利用回数制限がある場合、
Rate LimitノードやWaitノードを挟むことで、リクエストの間隔を調整し、API制限によるエラーを防ぎます。
5-2. 観測とメトリクス
- ヘルスチェック: n8nには
/healthzというエンドポイントがあり、サービスが正常に起動しているかを確認できます。監視システムにこのURLを登録しましょう。 - メトリクス監視:
N8N_METRICS=trueを設定すると、/metricsエンドポイントからPrometheus形式で詳細なメトリクスが取得できます。特に以下の指標は重要です。- Redisのキューの深さ(ジョブの滞留状況)
- ワークフローの成功/失敗率
- ワークフローの実行時間(特にP95, P99)
- Webhookのエンドポイントごとのレイテンシ
- PostgreSQLの接続数
- ログ: 通常は
N8N_LOG_LEVEL=infoで運用し、障害調査時には一時的にdebugに切り替えて詳細なログを取得します。
5-3. データ保持・コンプライアンス
- 実行データの管理:
EXECUTIONS_DATA_PRUNEとEXECUTIONS_DATA_MAX_AGEを適切に設定し、古い実行データを定期的に削除することで、データベースの肥大化を防ぎます。これはパフォーマンス維持と、不要な個人情報を長期間保持しないというコンプライアンスの観点からも重要です。 - 機密データの保護:
N8N_ENCRYPTION_KEYはパスワードマネージャーなどで厳重に管理し、定期的なローテーション計画を立てます。環境変数は.envファイルにまとめて、適切なパーミッション(例:600)を設定しましょう。 - 日本法規への配慮: 個人情報を含むファイルを扱う場合、生成する共有リンクの有効期限は必要最小限に設定します。また、誰がいつどのような操作を行ったかを追跡できるよう、n8nの監査ログやNextcloudのログは、社内規定に基づいた十分な期間、保管・監視する必要があります。
5-4. セキュリティハードニング
- アクセス制御: n8nの管理画面には、Basic認証やSSO(エンタープライズ版)を導入し、不正アクセスを防ぎます。管理者権限を持つユーザーは最小限に絞りましょう。
- Webhookの検証: 可能であれば、送信側(Nextcloudなど)でリクエストに署名(HMACなど)を付与し、n8n側でその署名を検証するロジックを組み込みます。これが難しい場合は、送信元IPアドレスの制限や、URLに含めるシークレットトークンでの認証を検討します。
- テレメトリの無効化: 社内ポリシーによっては、外部への情報送信を完全に無効化する必要があります。その場合は
N8N_DIAGNOSTICS_ENABLED=falseとN8N_PERSONALIZATION_ENABLED=falseを設定します。 - ngrokのセキュリティ: ngrokの有料プランでは、Basic認証やOAuthをトンネルに設定できます。これにより、意図しないアクセスからn8nのWebhookエンドポイントを保護できます。
5-5. バックアップとDR(ディザスタリカバリ)
- n8n本体: ワークフロー定義や資格情報が保存されている
.n8nディレクトリ(コンテナの場合はマウントしたボリューム)を定期的にスナップショットします。N8N_ENCRYPTION_KEYとセットで保管することが極めて重要です。 - データベース: PostgreSQLの定期的なバックアップ(
pg_dumpやWALアーカブ)は必須です。ただバックアップを取るだけでなく、実際にリストアできるかどうかの復旧演習を定期的に実施しましょう。 - Nextcloud: Nextcloud本体のバックアップ手順に従い、ファイルデータとデータベースの両方を保護します。
- 復旧手順書の整備: 障害発生時に慌てないよう、Webhook URLの再設定、DNSレコードの切り替え、pgvectorの索引再作成といった手順まで含めた、具体的な復旧手順書を事前に作成しておきます。
6. パフォーマンス最適化:DB・Queue・I/O
運用が軌道に乗ってくると、次はパフォーマンスが課題になります。
6-1. PostgreSQL チューニング
- 基本パラメータ: サーバーのメモリ量に応じて、
shared_buffers,work_mem,effective_cache_sizeといった基本的なメモリ関連パラメータを適切に調整します。 - pgvector:
- 索引作成は、前述の通りまとまったデータ投入後に実行します。
ivfflat索引のlistsパラメータは、データ件数に応じて定期的に見直し、再作成を検討します。- 類似度計算には、要件に応じて適切な演算子(コサイン距離:
<=>、内積:<#>、ユークリッド距離:<->)を選択します。
- メンテナンス:
VACUUMとANALYZEを定期的に実行し、テーブルの断片化を解消し、統計情報を最新に保ちます。autovacuumの閾値調整も効果的です。
6-2. Redis/Queue
- Workerの数:
n8n-workerコンテナのレプリカ数は、CPUコア数と処理の特性(CPUバウンドかI/Oバウンドか)を考慮して決定します。API呼び出しのようなI/O待ちが多い処理なら多めに、重い計算処理ならCPUコア数程度に設定するのが一般的です。 - 並列実行制御: 特定の重いAPIを呼び出すノードに対しては、そのノードの設定で同時実行数を制限することで、相手サーバーに過度な負荷をかけるのを防ぎます。
- 大容量バイナリの扱い: ワークフローの実行データに大きなファイル(バイナリデータ)を含めると、n8nとDB間の通信がボトルネックになります。
EXECUTIONS_DATA_SAVE_ON_SUCCESS=summaryを設定し、ファイル自体はNextcloud上に置いたまま、パス情報だけをやり取りする設計を徹底します。
6-3. I/O とファイル処理
- ストリーム処理: 巨大なファイルを扱う際は、ファイル全体をメモリに読み込むのではなく、ストリームとして処理することで、メモリ使用量を抑えることができます。
- 一時ファイル: 処理の途中で一時ファイルが必要になる場合は、高速なtmpfs(メモリベースのファイルシステム)を利用することを検討します。
- チャンクアップロード: 大容量ファイルをNextcloudにアップロードする際は、HTTPリクエストノードでチャンク分割アップロードを実装すると、ネットワークが不安定な環境でも成功率が向上します。
7. よくある誤解・失敗と対策
最後に、多くのユーザーが陥りがちな典型的な失敗例とその対策をまとめます。
- 誤解1:
WEBHOOK_URLを設定しなくても外部Webhookが動くはずだ。- 対策: 動きません。n8nが自身のエンドポイントURLを正しく生成するために、
WEBHOOK_URLは必須です。必ず外部から到達可能なhttpsのURLを設定してください。ngrokのURLが変わったら、この環境変数も更新してn8nを再起動する必要があります。
- 対策: 動きません。n8nが自身のエンドポイントURLを正しく生成するために、
- 誤解2:
/webhook-testを本番のエンドポイントとして使って良い。- 対策: いけません。
/webhook-testは、エディタ画面で手動テストを実行している間だけ有効な一時的なエンドポイントです。本番運用では、ワークフローを有効化した後に生成される、/webhookパスを含む永続的なURLを使用してください。
- 対策: いけません。
- 失敗1: 資格情報の暗号化キー (
N8N_ENCRYPTION_KEY) を変えてしまい、保存した資格情報が復号できなくなった。- 対策: このキーは厳重に管理し、決して安易に変更してはいけません。バックアップから復旧する際も、必ず同じキーを使用する必要があります。変更が必要な場合は、計画的なメンテナンス期間を設け、すべての資格情報を再登録する覚悟で行ってください。
- 失敗2: pgvectorで検索しているが、なぜか非常に遅い。
- 対策: ほとんどの場合、索引(Index)を作成し忘れていることが原因です。
ivfflatやHNSWといった索引を構築し、ANALYZEコマンドで統計情報を更新してください。性能が劇的に改善します。
- 対策: ほとんどの場合、索引(Index)を作成し忘れていることが原因です。
- 失敗3: ファイルを扱っているはずなのに、後続のノードで「データがない」とエラーになる。
- 対策: n8nのバイナリデータとJSONデータの区別を理解していない可能性があります。
Move Binary Dataノードなどを使い、バイナリデータが後続ノードのどのプロパティに格納されるかを明示的に意識してワークフローを設計する必要があります。
- 対策: n8nのバイナリデータとJSONデータの区別を理解していない可能性があります。
- 失敗4: 便利そうなので、検証せずにたくさんのCommunity Nodesを導入してしまった。
- 対策: Community Nodesは、システムの不安定化やセキュリティリスクの原因になり得ます。導入は必要最低限に留め、必ずステージング環境での検証、バージョン固定、定期的な脆弱性チェックを行う運用プロセスを確立してください。
8. まとめと次のアクション
本稿では、n8nとNextcloudを中心に、Ubuntu上でのセルフホスト環境で堅牢な自動化基盤を構築・運用するための包括的なガイドを提供しました。Queueモード、PostgreSQL (pgvector)、Redis、ngrokを組み合わせたアーキテクチャは、スケーラビリティと信頼性の両面で、実運用に耐えうる強力な選択肢です。
あなたの自動化プロジェクトを成功に導くために、以下のステップで進めることを推奨します。
- ステップ1: 環境の健全化
- まずは本記事で紹介したDocker Composeテンプレートを参考に、n8n v1.113.0以上、
WEBHOOK_URL、Queueモード、PostgreSQL+pgvector、Redis、ngrokの基本構成を確立させます。
- まずは本記事で紹介したDocker Composeテンプレートを参考に、n8n v1.113.0以上、
- ステップ2: 安全なNextcloud基本連携の確立
Cron+List Filesによるポーリング型のワークフローから始め、ファイルの命名規則統一、フォルダへの自動振り分け、共有リンク発行、関係者への通知といった、安定的で価値の高い自動化を実現します。
- ステップ3: イベント駆動型への進化
- リアルタイム性が求められる要件に対して、Nextcloudのフロー機能とn8nのWebhookを組み合わせた、イベント駆動型のワークフローを導入します。Webhookのセキュリティ強化も忘れずに行いましょう。
- ステップ4: 知的検索機能の導入
- テキスト抽出、埋め込みベクトル生成、pgvectorへの登録、そして自然言語での検索という一連の流れをテンプレート化し、ファイル資産の価値を最大化します。
- ステップ5: 標準化と監視体制の構築
- 共通処理をサブフロー化し、リトライやデッドレターキューの設計を標準化します。同時に、メトリクス監視やバックアップ・DR計画を整備し、システムを「止まらない」状態に近づけていきます。
よくある誤解(/webhook-testの本番利用、WEBHOOK_URLの未設定、pgvectorの索引未作成など)を避け、冪等性(何度実行しても同じ結果になること)とセキュリティを常に意識して設計すれば、n8nとNextcloudの連携は、あなたの組織の業務効率を劇的に改善する力強い味方となります。
さあ、今日から最初のワークフローを構築し、まずはファイル整流化と共有リンクの自動発行から始めてみましょう。小さく始め、継続的に改善を重ねることで、メンテナンスコストは確実に低下し、自動化の恩恵を最大限に享受できるはずです。
このガイドが、あなたのn8nとNextcloud連携プロジェクトを、単なる技術検証から、ビジネスに貢献する実務基盤へと押し上げる一助となれば幸いです。
【付録】Nextcloud × n8n 同居環境で特に有用なプラグイン
| プラグイン名 | 機能 | n8n連携での活用例 |
|---|---|---|
| Talk | チャット・通話・通知 | ファイルアップロード後にTalkで承認依頼通知を送信(Webhook連携) |
| Group Folders | グループ単位の共有管理 | 承認済みファイルを部署別フォルダに自動振り分け |
| Forms | アンケート・申請フォーム | 申請内容をn8nで受信 → 自動処理・通知・記録 |
| Calendar | CalDAV対応カレンダー | n8nで予定登録・変更通知・リマインダー送信 |
| Deck | カンバン式タスク管理 | 承認後にDeckカードを自動生成し進捗管理へ連携 |
| External Storage Support | WebDAV/SFTP/S3連携 | n8nで外部ストレージからNextcloudへ同期・バックアップ |
| Extract | ZIP/RAR解凍 | n8nで受信した圧縮ファイルを自動展開して処理 |
| Notifications | 通知API | n8nからNextcloudユーザーへ直接通知送信可能 |
| Metadata Viewer | ファイルのEXIF・メタ情報表示 | n8nで画像分類・タグ付け処理に活用可能 |
| README.md Viewer | フォルダ内の説明表示 | テンプレート配布時に自動で説明を表示(UX向上) |
| Password Policy | パスワード強度制御 | n8nでユーザー作成時にポリシー準拠を保証 |
| ocDownloader | YouTube/Torrent/HTTPダウンロード | n8nで教材・動画を自動収集しNextcloudへ保存 |
ワークフローのアイディア例
- 「議事録アップロード → PDF化 → Talk通知 → Deckで進捗管理」までをn8nで自動化
- 「Formsで申請 → 承認 → Group Folderへ格納 → Calendarに予定登録」という業務フローをNextcloud内で完結
- ocDownloader + n8n + Extractで教材収集・展開・分類まで自動処理

