

- 1 n8n権限管理と監査ログ設計の構築ガイド:AI連携時代の安全な自動化運用
- 2 はじめに:自動化は「便利」から「責任」を問われる時代へ
- 3 基礎理解:n8nで守るべき対象と、監査で問われること
- 4 権限モデルの設計原則:人・ワークフロー・クレデンシャルの三層で考える
- 5 監査ログ設計の原則:目的別に「必要十分」な情報を記録する
- 6 実装ガイド①:n8nの基本設定(ログと実行データ)
- 7 実装ガイド②:本番用Docker Compose構成例
- 8 実装ガイド③:GitOpsで「変更の監査ログ」を確実なものにする
- 9 実装ガイド④:実行ログの拡張(相関ID・実行者情報の付与)
- 10 実装ガイド⑤:承認ゲート(4-eyes)をワークフローに組み込む
- 11 AI連携(MCP的パターン)における権限ガードレール
- 12 本番構成のアーキテクチャ指針:安定性と安全性を両立させる
- 13 よくある誤解/失敗と是正策
- 14 FAQ:よくある質問
- 15 最後に:安全な自動化基盤を足場に、次のステージへ
n8n権限管理と監査ログ設計の構築ガイド:AI連携時代の安全な自動化運用
はじめに:自動化は「便利」から「責任」を問われる時代へ
業務自動化ツールn8nは、その柔軟性と拡張性から多くの技術者に支持されています。近年では、ChatGPTに代表される大規模言語モデル(LLM)と組み合わせることで、これまで考えられなかった高度な「自動実行型AI」の実装も可能になりました。
しかし、その利便性の裏側には、大きな責任が伴います。メールの自動送信、顧客データの更新、インフラ設定の変更など、人手の操作をソフトウェアが肩代わりする範囲が広がるほど、誤操作や不正利用、そして「誰が何をしたのか」という証跡の不備が、ビジネスに深刻な影響を与えるリスクも増大します。
もし監査が入った場合、あなたは次の5つの問いに明確に答えられるでしょうか?
「誰が、何を、いつ、どこで、なぜ(承認の根拠は何か)実行したのか」
この記事は、n8nを開発環境での「お試し」から、本番環境での「本格運用」へと移行させたいすべての技術者に向けて書かれています。n8nを安全に、そして統制を効かせた形で運用するための権限設計と監査ログ設計について、導入の基礎からエンタープライズレベルの運用まで、一気通貫で解説します。
特に、自然言語の指示から自動実行までを橋渡しするAI連携を前提に、具体的な実装パターン、設定例、GitOpsを用いた運用プロセス、そして誰もが陥りがちな落とし穴まで、現場で即実践できるレベルの知見を網羅しました。この記事を読み終える頃には、あなたは自信を持ってn8nの安全な自動化基盤を設計・構築できるようになるでしょう。
この記事で得られること(先に結論)
- 最小権限の原則の徹底: 「人」「ワークフロー」「クレデンシャル」の三層構造で権限を分離し、職務分掌(SoD)を実現する方法を学びます。
- 監査に耐えるログ設計: 「設定変更ログ」「実行ログ」「外部呼び出しログ」「承認ログ」を明確に分離し、必要な情報を確実に記録する手法を習得します。
- モダンな運用体制の構築: n8nの実運用におけるデファクトスタンダードである「GitOps」の具体的なフローと、レビュー体制の作り方を理解します。
- AI連携のリスク管理: AIによる自動実行を安全に制御するための「ツール許可リスト」「予算ガード」「承認ゲート」といったガードレールを実装する方法がわかります。
- 本番環境の鉄板構成: PostgreSQL、Redis、ワーカー分離、リバースプロキシといった本番稼働に必須のアーキテクチャと、その設定例を具体的に把握します。
- 監査対応力の強化: 「誰が、何を、なぜ」を追跡可能にするメタデータ設計と、レポーティングの勘所を掴みます。
基礎理解:n8nで守るべき対象と、監査で問われること
効果的な権限管理と監査ログ設計を行うためには、まず「何を守るべきか(アセット)」と「監査で何が問われるか」を明確に定義する必要があります。
1. 守るべき対象(アセット)
n8n環境における主要な保護対象は以下の通りです。
- ワークフロー: 自動化のロジックそのものです。定義内容、アクティベーション状態(有効/無効)、バージョン履歴が管理対象となります。
- クレデンシャル: APIキーやOAuthトークンなど、外部サービスへアクセスするための秘密情報です。どの権限スコープを持つか、所有者は誰か、誰と共有されているかが重要です。
- 実行(Execution): ワークフローが実際に動作した記録です。「誰が/何から」「いつ/どこで」起動し、どのような入出力データを扱い、どの外部サービスを呼び出したかが対象です。
- ノード実装・拡張: FunctionノードやCodeノードで書かれた任意のコードや、独自にインストールされた外部モジュールは、予期せぬ動作を引き起こす可能性があるため管理が必要です。
- トリガー: Webhook、スケジュール、イベントなど、ワークフローを開始させる起点です。意図しないトリガー設定は、不正実行の温床となり得ます。
2. 想定される行為(誰が何をできるか)
ユーザーが行う操作は、権限によって制御されるべきです。
- 閲覧、編集、有効化/無効化
- 手動実行、共有設定
- クレデンシャルの参照/利用
これらの行為を、誰が、どのアセットに対して行えるかを厳密に管理することが権限設計の核となります。
3. 監査の観点(証跡として残すべき内容)
監査では、単にログが残っているだけでは不十分です。目的を持った証跡が求められます。
- 設定変更ログ: 「誰が、どの設定を、いつ、どの値からどの値に変更したか」を追跡できること。
- 実行ログ: 「どのワークフローが、どのトリガー/誰によって、いつ実行され、どのクレデンシャルを使い、どの外部にアクセスし、結果はどうだったか」が明確であること。
- 承認ログ: 高リスクな操作に対して、「誰の承認(理由や関連チケット番号を含む)があり、いつ有効化/実行が許可されたか」を証明できること。
- データ保護: ワークフローが扱う入出力データのうち、個人情報や機密情報をどのように保護しているか(マスキング、保存期間など)の方針が示せること。
4. 日本市場特有の留意点
グローバルなベストプラクティスに加え、日本国内での運用では以下の点にも配慮が必要です。
- 個人情報保護法への準拠: 特にマイナンバーなどの特定個人情報や、要配慮個人情報は、原則としてn8nの実行ログに保存しない、または不可逆的な形でハッシュ化するなどの対策が求められます。
- 情報セキュリティ監査の証憑要求: 日本の監査では、操作履歴ログ、定期的なアクセス権レビューの記録、変更管理台帳(いつ、誰が、何を、なぜ変更したか)といったドキュメントの提出を求められることが一般的です。
- アナログ業務との連携: 郵送やFAXといった日本独自の業務プロセスとの連携が残る場合、自動化の例外処理フローと、その手動介入に関する承認プロセスを併せて設計する必要があります。
権限モデルの設計原則:人・ワークフロー・クレデンシャルの三層で考える
堅牢な権限管理は「最小権限の原則」に基づきます。n8nでは、この原則を「人(ロール)」「ワークフロー」「クレデンシャル」という三つの階層で適用することが極めて重要です。
1. 人(ロール)に対する原則:職務分掌の徹底
ユーザーの役割に応じて権限を明確に分離します。SSO(シングルサインオン)と組み合わせることで、IdP(Identity Provider)側でのグループ管理と同期させるのが理想です。
- Owner / Platform Admin: インスタンス全体の管理者。ユーザー管理、システム設定などすべてが可能です。この権限は最小人数のインフラ担当者などに限定し、日常業務では使用しないようにします。二要素認証は必須です。
- Admin(ドメイン/部門管理者): 担当部署内のユーザー招待やワークフローの共有設定などを行いますが、クレデンシャルなどの機密情報には直接触れない運用を心がけます。
- Editor(開発者): ワークフローの開発・編集が可能です。本番環境では直接的な編集権限を持たせず、後述するGitOpsプロセスを通じて変更を反映させるのがベストプラクティスです。
- Operator(運用者): 開発済みのワークフローの手動実行や、有効化/無効化のみが許可されます。ワークフローのロジックは編集できません。
- Viewer(閲覧者): ワークフローの構成や実行結果のサマリーを閲覧できます。デバッグ用の詳細な入出力データは見せない設定が推奨されます。
[実装TIPS]
エンタープライズ版などでSSO(SAML/OIDC)が利用できる場合は、IdPのグループとn8nのロールを同期させ、入退社や異動に伴う権限変更を自動化しましょう。Community Editionを利用する場合は、リバースプロキシによるIPアドレス制限や、強固なパスワードポリシーの徹底を組み合わせることでセキュリティレベルを高めます。
2. ワークフローに対する原則:編集と実行の分離
ワークフロー自体にも、ライフサイクルに応じた管理が必要です。
- 「編集権限」と「実行権限」の分離: ワークフローの編集は開発環境で行い、テストが完了したものだけを本番環境にデプロイして実行する、という流れを徹底します。
- 有効化/無効化の制限: ワークフローを有効化する行為は、本番環境へのリリースと同義です。この権限はOperator以上の役割に限定し、誰でも自由に有効化できないようにします。
- 責任者の明確化: すべてのワークフローには「責任者(オーナー)」「作成者」「レビュー担当者」をメタデータとして(タグやドキュメントで)明記します。
- 命名規約とタグ付け:
PRD_Finance_InvoiceProcessingのように環境、部門、目的がわかる命名規則を徹底します。タグ(例:Risk:High,PII:Include)を活用し、棚卸しや監査を容易にします。 - 仕様のドキュメント化: ワークフローが期待するインプットのスキーマと、生成するアウトプットのスキーマを簡潔に記述し、変更管理の際の承認根拠として添付します。
3. クレデンシャルに対する原則:最小スコープとライフサイクル管理
クレデンシャルは最も厳重に管理すべきアセットです。
- 権限スコープの最小化: 外部サービスのAPIキーを発行する際は、必要な権限(例:
readonly)のみを付与します。全権限を持つキーは絶対に使用しないでください。可能な限り、専用のサービスアカウントを作成します。 - ワークフロー単位での専用化: 複数のワークフローで一つの強力なクレデンシャルを使い回すのは避けましょう。ワークフローごとに専用のクレデンシャルを用意することで、万が一漏洩した際の影響範囲を限定できます。
- 定期的なローテーション: クレデンシャルの有効期限とローテーション周期(例: 四半期ごと)を定め、計画的に更新します。更新作業は、ロールバック手順を準備した上で、業務影響の少ない時間帯に実施します。
- 暗号鍵(N8N_ENCRYPTION_KEY)の厳重保管: n8nはクレデンシャル情報をこのキーで暗号化してDBに保存します。このキーを紛失すると、すべてのクレデンシャルが復号できなくなり、システムが壊滅的なダメージを受けます。必ず設定し、安全な場所にバックアップしてください。
- 外部シークレット管理サービスの利用: より高度なセキュリティが求められる環境では、HashiCorp VaultやAWS Secrets Managerなどの外部サービスで機密情報を管理し、n8nからは環境変数経由で参照する方法も有効です。
監査ログ設計の原則:目的別に「必要十分」な情報を記録する
やみくもにすべてのログを保存するのは、ストレージコストを増大させるだけでなく、監査時に必要な情報を見つけにくくする原因にもなります。ログは目的別に設計し、データ最小化の原則を適用します。
- 目的別のログ設計
- セキュリティ監査ログ: 不正アクセスや権限昇格の検知・追跡が目的です。ユーザーのログイン履歴、ロール変更、IPアドレス、承認の有無などを記録します。
- 運用監視ログ: システムの安定稼働が目的です。ワークフローの失敗率、実行遅延、リトライ回数、外部APIの応答時間などを監視します。
- 品質保証ログ: データの正当性担保が目的です。ワークフローへの入力データの品質、処理結果の妥当性、例外処理の発生状況などを分析します。
- データ最小化の原則
実行データ(ワークフローの各ノードが受け渡すJSONデータ)は、個人情報(PII)や機密情報を含む可能性が高いため、保存は必要最小限に限定します。特に成功した実行のデータは、メタ情報(実行ID、ステータス、時刻など)のみを保存し、詳細なペイロードは破棄するのが基本です。PIIは保存前に必ずマスクまたはハッシュ化します。 - 保存期間の明確化
ログの種類に応じて保存期間を変えます。例えば、成功ログは7日、失敗ログ(デバッグに必要)は30日、セキュリティ監査や承認に関するログは180日や1年、といったルールを定めます。 - 相関ID(Correlation ID)の活用
一連の処理を追跡可能にするため、すべての実行にユニークな相関IDを付与します。このIDを外部API呼び出し時のヘッダーにも含めることで、システムを横断したログの突合が容易になります。 - 監査容易性の確保
後からログを検索・分析しやすいように、検索キーとなる情報(ユーザーID、ワークフローID、クレデンシャルID、関連チケット番号など)を構造化されたログ(JSON形式など)に必ず含めます。
実装ガイド①:n8nの基本設定(ログと実行データ)
n8nの動作は環境変数によって細かく制御できます。特にログと実行データの保存戦略は、本番運用の根幹をなす重要な設定です。
実行データの保存戦略(主要な環境変数)
EXECUTIONS_DATA_SAVE_ON_SUCCESS=false
成功したワークフローの実行データ(各ノードの入出力)を保存しません。これにより、DBの肥大化を防ぎ、個人情報がログに残るリスクを大幅に低減できます。本番環境ではfalseが強く推奨されます。EXECUTIONS_DATA_SAVE_ON_ERROR=true
失敗したワークフローの実行データは保存します。これにより、エラー発生時の原因調査(デバッグ)が可能になります。EXECUTIONS_DATA_PRUNE=true
古い実行データを自動的に削除する機能を有効にします。EXECUTIONS_DATA_MAX_AGE=720
実行データの最大保存期間を時間単位で指定します(例: 30日 = 720時間)。EXECUTIONS_MODE=queue
本番環境では、実行をキューイングするモードを推奨します。これにより、Webhookの同時アクセスなどによる高負荷時にも、実行の取りこぼしを防ぎ、安定した処理が可能になります。このモードではRedisが必須です。
アプリケーションログの設定
N8N_LOG_LEVEL=info
通常運用時はinfoレベルで十分です。障害調査時には一時的にdebugに変更して詳細なログを取得します。N8N_LOG_OUTPUT=console
コンテナ環境では標準出力(console)に出力し、DockerのロギングドライバーやFluentdなどのログ収集ツールで集約するのが一般的です。
セキュリティ関連の必須設定
N8N_ENCRYPTION_KEY
最重要項目です。 必ず32文字以上のランダムな文字列を設定してください。このキーがないとクレデンシャルが平文で保存される可能性があり、非常に危険です。NODE_FUNCTION_ALLOW_BUILTIN=
Functionノード内でrequire()できるNode.jsの組み込みモジュールを制限します。crypto,urlなど、本当に必要なものだけにホワイトリスト形式で限定します。NODE_FUNCTION_ALLOW_EXTERNAL=
Functionノードでrequire()できる外部npmモジュールを制限します。原則として空にし、安易に任意のコードを実行させないようにします。
実装ガイド②:本番用Docker Compose構成例
ここでは、PostgreSQL、Redis、Worker分離、リバースプロキシ(Nginx)を含んだ、本番運用を想定した最小構成の docker-compose.yml を示します。
# docker-compose.yml
version: "3.8"
services:
postgres:
image: postgres:15
restart: always
environment:
- POSTGRES_USER=n8n
- POSTGRES_PASSWORD=YOUR_STRONG_POSTGRES_PASSWORD # 強固なパスワードに変更
- POSTGRES_DB=n8n
volumes:
- pgdata:/var/lib/postgresql/data
healthcheck:
test: ["CMD-SHELL", "pg_isready -U n8n"]
interval: 5s
timeout: 5s
retries: 10
redis:
image: redis:7
restart: always
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 5s
timeout: 5s
retries: 10
n8n:
image: n8nio/n8n:latest
restart: always
environment:
- DB_TYPE=postgresdb
- DB_POSTGRESDB_HOST=postgres
- DB_POSTGRESDB_PORT=5432
- DB_POSTGRESDB_DATABASE=n8n
- DB_POSTGRESDB_USER=n8n
- DB_POSTGRESDB_PASSWORD=YOUR_STRONG_POSTGRES_PASSWORD # postgresと同じパスワード
- QUEUE_BULL_REDIS_HOST=redis
- EXECUTIONS_MODE=queue
# --- 暗号鍵:必ず生成・設定してください ---
- N8N_ENCRYPTION_KEY=YOUR_VERY_LONG_AND_RANDOM_ENCRYPTION_KEY
# --- ログと実行データ設定 ---
- N8N_LOG_LEVEL=info
- EXECUTIONS_DATA_SAVE_ON_SUCCESS=false
- EXECUTIONS_DATA_SAVE_ON_ERROR=true
- EXECUTIONS_DATA_PRUNE=true
- EXECUTIONS_DATA_MAX_AGE=720 # 30 days
# --- Webhook用設定 ---
- N8N_PROTOCOL=https
- N8N_HOST=n8n.yourdomain.com # あなたのドメインに変更
- N8N_PORT=5678
- WEBHOOK_URL=https://n8n.yourdomain.com/
# --- Functionノードの制限 ---
- NODE_FUNCTION_ALLOW_BUILTIN=
- NODE_FUNCTION_ALLOW_EXTERNAL=
ports:
- "127.0.0.1:5678:5678"
depends_on:
postgres:
condition: service_healthy
redis:
condition: service_healthy
worker:
image: n8nio/n8n:latest
command: n8n worker
restart: always
environment:
# n8nサービスと同じ環境変数を設定
- DB_TYPE=postgresdb
- DB_POSTGRESDB_HOST=postgres
- DB_POSTGRESDB_PORT=5432
- DB_POSTGRESDB_DATABASE=n8n
- DB_POSTGRESDB_USER=n8n
- DB_POSTGRESDB_PASSWORD=YOUR_STRONG_POSTGRES_PASSWORD
- QUEUE_BULL_REDIS_HOST=redis
- EXECUTIONS_MODE=queue
- N8N_ENCRYPTION_KEY=YOUR_VERY_LONG_AND_RANDOM_ENCRYPTION_KEY
- NODE_FUNCTION_ALLOW_BUILTIN=
- NODE_FUNCTION_ALLOW_EXTERNAL=
depends_on:
postgres:
condition: service_healthy
redis:
condition: service_healthy
# ... (オプション: リバースプロキシ Nginx の設定)
# ... (オプション: ログ収集 Fluentd の設定)
volumes:
pgdata: {}[運用TIPS]
- この構成では、n8n本体は外部にポートを公開せず、リバースプロキシ経由でのみアクセスさせます。プロキシ側でTLS終端、IPアドレスによるアクセス制限、基本的なWAF機能などを実装します。
- ログ収集のために、FluentdやVectorのようなエージェントをサイドカーコンテナとして追加し、DatadogやElasticsearchなどの外部SIEM/ログ管理基盤にログを転送する構成が理想的です。
- Workerサービスは、
docker-compose up --scale worker=3のようにスケールアウトさせることで、ワークフローの並列処理能力を高めることができます。
実装ガイド③:GitOpsで「変更の監査ログ」を確実なものにする
n8nのUI上でのワークフロー編集は直感的で便利ですが、本番運用では「いつ、誰が、何を、なぜ変更したのか」という証跡が曖昧になりがちです。この問題を解決する強力な手法が GitOps です。
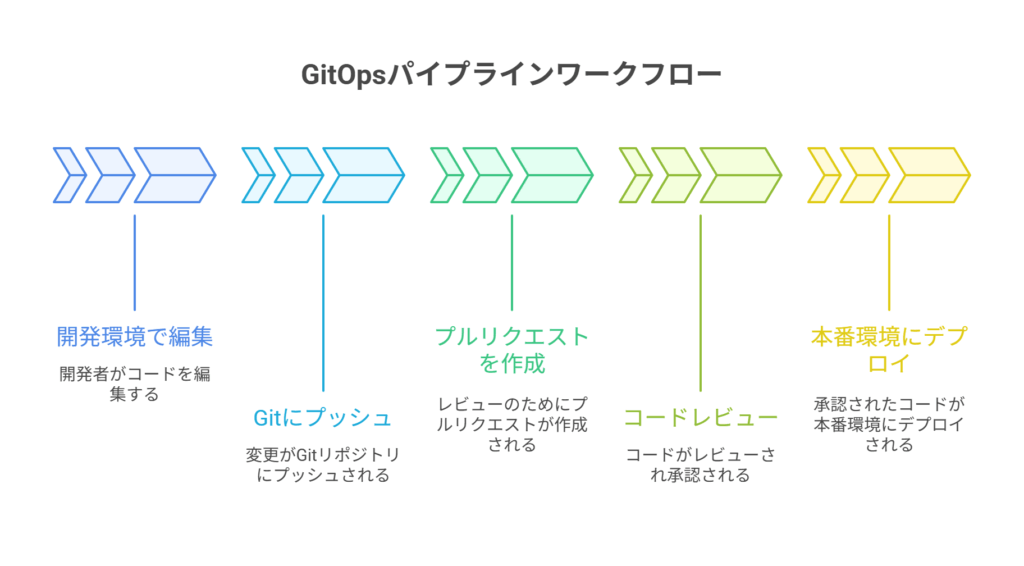
基本的なフロー
- 開発環境で編集: 開発者(Editor)は、ローカルや開発用のn8nインスタンスでワークフローを自由に編集・テストします。
- エクスポートとPR作成: 完成したワークフローをJSON形式でエクスポートし、Gitリポジトリにコミットしてプルリクエスト(PR)を作成します。コミットメッセージには、変更理由や関連するチケット番号(Jiraなど)を必ず記載します。
- レビュー(4-eyes principle): 別の開発者や運用担当者など、最低でも1人以上のレビュアーがPRの内容(変更差分)をレビューします。これにより、一人による誤操作や意図しない変更が本番に反映されるのを防ぎます(4-eyes principle: 二人による確認)。
- マージと自動デプロイ: PRが承認されてメインブランチにマージされると、CI/CDパイプライン(GitHub Actions, GitLab CIなど)がトリガーされます。
- インポートと有効化: パイプラインはn8nのCLIを使い、JSONファイルを本番環境のn8nインスタンスにインポートし、自動で有効化(activate)します。
CLIコマンド例(概念)
# ワークフローをエクスポート
n8n export:workflow --all --output-dir=/path/to/repo/workflows
# ワークフローをインポート
n8n import:workflow --separate --input=/path/to/repo/workflows運用上の重要ポイント
- 機密情報をGitに含めない: クレデンシャルは絶対にGitで管理しません。本番環境のクレデンシャルIDは環境変数で管理し、ワークフローJSON内では
{{ $env.CREDENTIAL_ID }}のように参照するか、開発用と本番用で同じ名前のクレデンシャルを用意して、n8nが自動でマッピングするようにします。 - コミットメッセージの規律:
feat(Finance): JIRA-123 請求書処理のAPI仕様変更に対応 (Approved by @reviewer)のように、変更内容、チケット番号、承認者を明記するルールを徹底します。これにより、Gitのログ 자체가強力な監査ログとなります。 - ロールバック手順の確立: 問題が発生した際に、Gitで以前のコミットに戻す(revert)ことで、即座にワークフローを以前のバージョンにロールバックできる手順を確立・文書化しておきます。
実装ガイド④:実行ログの拡張(相関ID・実行者情報の付与)
デフォルトの実行ログだけでは、「この実行はどのリクエストに起因するものか?」「誰が手動で実行したのか?」といった追跡が困難な場合があります。Setノードなどを活用して、ログにメタデータを付与する工夫が重要です。
- 相関ID(Correlation ID)の付与
Webhookトリガーの最初のノードで、X-Correlation-IdのようなHTTPヘッダーを確認します。もしヘッダーが存在しなければ、CodeノードやSetノードでUUIDを生成し、{{ $json.meta.correlationId }}のように後続のノードに引き回せる場所に格納します。
外部APIを呼び出す際も、この相関IDをHTTPヘッダーに含めることで、相手側のシステムのログと自システムのログを紐付けて調査できます。 - 実行者情報の記録
手動で実行された場合、n8nは実行ユーザーの情報を保持しています。これを{{ $user.email }}のように参照し、{{ $json.meta.executedBy }}といったフィールドに記録します。
外部システムからのAPIコールによってトリガーされる場合は、認証に使用したAPIキーに紐づくサービスアカウント名などを必須パラメータとして受け取り、同様に記録します。 - SIEM連携による高度な監視
より高度な監査要件に応えるには、n8nのDBから実行ログを定期的に抽出し、SIEM(Security Information and Event Management)ツールに転送する専用のワークフローを用意します。 [転送用ワークフローの概念]- Scheduleトリガー: 5分ごとに実行
- Postgresノード:
execution_entityテーブルから、直近5分間に完了した実行ログ(特に失敗したもの)をクエリ - Ifノード: 新しいログがある場合のみ後続へ
- HTTP Requestノード: 取得したログを加工し、SIEMのエンドポイントへ送信
実装ガイド⑤:承認ゲート(4-eyes)をワークフローに組み込む
支払処理、顧客アカウントの削除、大量のデータ更新など、リスクの高い操作は、自動実行される前に必ず人間の承認を挟むべきです。この「承認ゲート」をワークフロー自体に組み込むことができます。
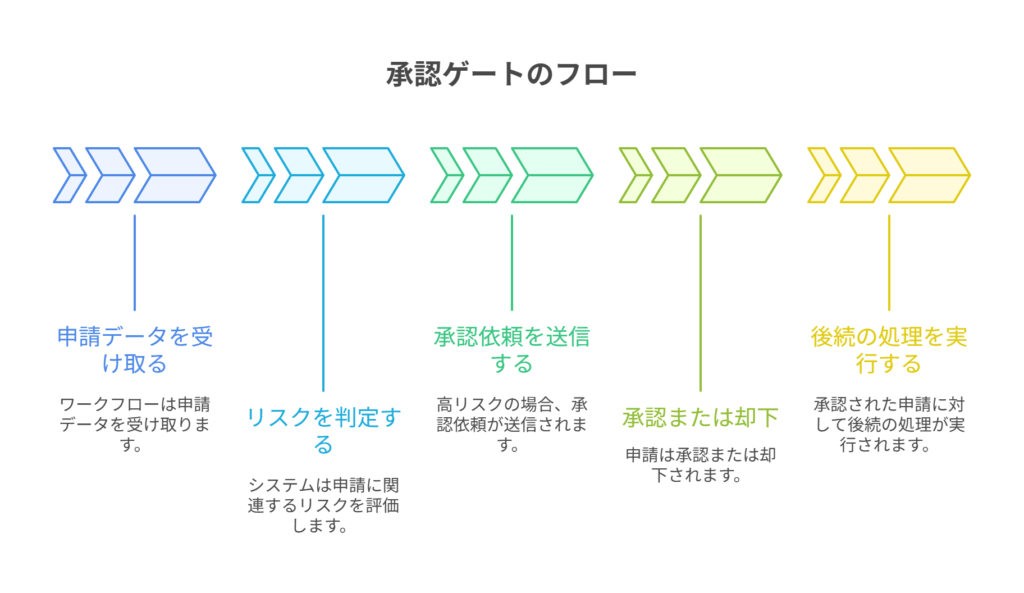
承認ゲートの典型的なパターン
- 申請ノード: Webhookやフォームからリクエストを受け取ります。
- リスク判定ノード: 申請内容(例: 金額、件数、対象範囲)を分析し、事前に定義したルールに基づいてリスクレベル(Low/Mid/High)を決定します。
- Ifノード: リスクレベルが
Highの場合のみ、承認プロセスへ進みます。 - 承認リクエストノード: SlackやMicrosoft Teamsに、承認依頼を送信します。メッセージには「誰が」「何を」しようとしているのか、そして金額や件数などの重要情報を太字で強調表示し、承認者が一目でリスクを判断できるように工夫します。承認/却下ボタンも付けます。
- 待機ノード (Wait): 承認または却下の応答があるまで、あるいはタイムアウト(例: 24時間)するまでワークフローの実行を一時停止します。
- 監査ログ記録ノード: 誰が、いつ、どの理由で承認/却下したか、関連チケット番号などの情報を、専用のログテーブル(Google SheetsやDB)に記録します。
- 本処理実行ノード: 承認された場合のみ、支払APIの実行など、本来の処理を続行します。
[実装TIPS]
この承認ゲートのロジックは、多くの高リスクワークフローで再利用可能です。「Execute Workflow」ノードを使い、承認プロセスを共通のサブワークフローとして呼び出すことで、管理が容易になります。
AI連携(MCP的パターン)における権限ガードレール
自然言語の指示でn8nワークフローを実行させるようなAI連携は非常に強力ですが、同時に大きなリスクも伴います。AIが予期せぬ、あるいは悪意のある操作を実行しないように、多層的なガードレールが必要です。
- ツール許可リスト(Tool Whitelist): AIが呼び出し可能なn8nのワークフロー(ツール)を、明示的な許可リストで厳格に制限します。最初はデータの読み取り(Read-only)系ワークフローから始め、安全性が確認できたものから段階的に更新(Write)系ワークフローを追加します。
- コスト/影響範囲ガード: AIの誤動作による被害を最小限に抑えます。
- 予算ガード: 外部API(特にLLM API)の呼び出し回数やトークン使用量に上限を設定します。
- 件数ガード: DBを更新するようなワークフローでは、一度に処理できるレコード数を制限します(例: 10件まで)。
- ドライランモード: デフォルトでは、実際に変更を加えない「ドライランモード」で実行させ、AIが生成した実行プランを人間が確認した後に本実行する、というステップを設けます。
- プロンプトと応答の透明性: ユーザーが入力したプロンプトと、それに対するAIの応答(どのツールを、どのパラメータで実行しようとしたか)は、すべて監査ログとして記録します。ただし、ログに含まれる個人情報はマスキング処理を施します。
- 人間による最終判断(Human in the Loop): 前述の「承認ゲート」を必ず組み込み、AIが高リスクと判断した操作や、一定金額以上の処理を実行しようとした場合は、人間の承認なしには実行できないようにします。
- Functionノードの厳格な制限: AI連携用のワークフローでは、
NODE_FUNCTION_ALLOW_BUILTINやNODE_FUNCTION_ALLOW_EXTERNALを空に設定し、任意のコード実行の可能性を完全に排除します。 - 出力スキーマ検証: AIが生成した結果(例: 顧客への返信メール文面)が、期待される形式やスキーマに準拠しているかを検証し、逸脱した場合はエラーとして扱い、人間によるレビューに回します。
本番構成のアーキテクチャ指針:安定性と安全性を両立させる
個別の設定だけでなく、システム全体のアーキテクチャも重要です。
- 環境分離: 最低でも開発(DEV)、ステージング(STG)、本番(PRD)の三つの環境を用意します。本番環境への変更は、GitOpsパイプライン経由のみに限定し、UIからの直接編集は禁止します。
- ネットワーク分離: 本番環境のn8nインスタンスは、プライベートなネットワーク内に配置し、外部からのアクセスはリバースプロキシやAPIゲートウェイ経由に限定します。Webhookのエンドポイントでは、リクエストの署名検証やIPアドレス制限を行い、正規の送信元からのリクエストのみを受け付けます。
- 可用性の確保:
EXECUTIONS_MODE=queueとWorkerの冗長化は必須です。データベースは定期的なバックアップとリストア訓練を行い、監視を徹底します。 - 多角的な監視:
- メトリクス監視: 成功率、実行遅延、キューの滞留数などをPrometheus/Grafanaなどで監視します。
- ログ監視: エラーログやタイムアウトを検知し、アラートを発報します。
- 合成モニタリング: 定期的にヘルスチェック用の簡単なワークフローを実行し、n8nシステム全体が正常に機能しているかを外部から監視します。
よくある誤解/失敗と是正策
長年の運用で見られる、典型的なアンチパターンとその対策です。
- 誤解1:実行データはすべて保存しておけば安心
- 現実: これはストレージを圧迫し、個人情報漏洩のリスクを高める最悪の選択です。
- 是正策: 保存は必要最小限に。「原則として個人情報は保存しない」という方針を先に決めます。成功した実行はメタ情報のみ、失敗した実行もデバッグに必要な情報に限定します。
- 誤解2:管理者が多いほど、いざという時に対応できて安心
- 現実: 権限の集中はリスクの集中です。OwnerやAdmin権限を持つユーザーが多いほど、誤操作やアカウント乗っ取り時の被害が甚大になります。
- 是正策: Owner/Adminは最小人数に限定します。日常業務は、権限が制限されたEditor/Operatorロールで行うことを徹底し、職務分掌と二重承認(GitOpsのPRレビューなど)を基本とします。
- 失敗1:クレデンシャルを一つ作り、複数のワークフローで使い回す
- 現実: あるワークフローで使うためだけに強力な権限を与えたキーが、別の簡単なワークフローからも使えてしまい、影響範囲の特定が困難になります。ローテーション時の影響調査も大変です。
- 是正策: 「1ワークフロー(または1用途)=1クレデンシャル」を原則とします。用途別にクレデンシャルを分離することで、影響範囲を限定し、安全なローテーションを可能にします。
- 失敗2:AI連携で、AIが自由に外部APIを叩けるようにしてしまう
- 現実: 悪意のあるプロンプト(プロンプトインジェクション)により、AIが想定外のAPIを実行し、情報漏洩やデータ破壊につながる可能性があります。
- 是正策: 「AIはサンドボックス内で動作させる」という意識を持ちます。ツール許可リスト、予算ガード、承認ゲート、ドライランモードといった多層的なガードレールを必ず実装します。
FAQ:よくある質問
Q1. Community Editionでも、ここで解説されているような監査は十分に可能ですか?
A. はい、可能です。SSO連携や高度なチーム管理機能は上位エディションが必要ですが、本記事で解説した中核的な要素、すなわち「実行データ保存設定」「アプリログの外部収集」「GitOpsによる変更履歴管理」「相関IDや承認メタデータの自前実装」は、すべてCommunity Editionで実現できます。これらを組み合わせることで、多くの実務要件に耐えうる監査体制を構築できます。
Q2. 実行データは具体的にどの程度の期間、保存すべきですか?
A. これは業務要件と法的規制によりますが、一般的な指針は以下の通りです。
- 成功した実行: メタ情報のみ、7日間(傾向分析に使う場合)
- 失敗した実行: デバッグに必要なペイロードを含め、30日間
- 承認に関するログ: 監査証憑として、180日〜1年間
まずはこの基準で始め、自社のルールに合わせて調整してください。
Q3. AIとの連携で最も重要なセキュリティ対策は何ですか?
A. ツール許可リスト(AIにできることを限定する)と承認ゲート(人間に最終判断を委ねる)の二つです。この二つを実装するだけで、AIが暴走するリスクを劇的に低減できます。加えて、予算ガードやドライランモードを組み合わせることで、より堅牢になります。
Q4. クレデンシャルをチーム内で安全に共有するにはどうすればいいですか?
A. n8nの機能を使えば、クレデンシャルの値を直接見せることなく、「使用権限」だけを共有できます。開発チームには、専用のサービスアカウントから発行した開発用のクレデンシャルを共有し、本番環境のクレデンシャルは運用担当者のみが管理・設定するのが理想です。
最後に:安全な自動化基盤を足場に、次のステージへ
自動化は、単に「楽をする」ためのツールではありません。適切に統制されて初めて、その価値を最大限に発揮し、ビジネスをスケールさせる力となります。「自動化は『任せきり』にするほど危険になる」ということを、常に心に留めておいてください。安全な自動化は、権限・承認・監査の三位一体で初めて実現します。
この記事で得た知識を、ぜひあなたのn8n環境に適用してみてください。まずは小さな一歩からで構いません。
次の一歩
- 今すぐ確認: あなたのn8nインスタンスの
N8N_ENCRYPTION_KEYと実行データ保存設定(EXECUTIONS_DATA_SAVE_ON_SUCCESS)を見直しましょう。 - 一つ作ってみる: 汎用的な「承認ゲート」のサブワークフローを一つ作成し、最もリスクの高いワークフローに組み込んでみましょう。
- 小さく始める: 最も重要なワークフローを一つ選び、GitOps化に挑戦してみましょう。チームでのPRレビューの運用を始めてみてください。
本記事で解説した原則と実践的な手法を導入すれば、n8nとAIを組み合わせた先進的な自動化であっても、エンタープライズ水準の統制と監査を、無理なく段階的に実現できるはずです。安全な自動化基盤という強固な足場を築き、より創造的で価値の高い業務へとシフトしていきましょう。

