

- 1 n8nジョブキュー最適化と高負荷対策 完全ガイド:設計原則から実践まで
- 1.1 最初におさえるべき ポイント
- 1.2 基礎理解:n8nの実行アーキテクチャとボトルネックの正体
- 1.3 実践ガイド:キュー最適化と高負荷対策の10ステップ
- 1.3.1 ステップ1:本番向けDocker Composeの土台を構築する
- 1.3.2 ステップ2:ワーカーの水平スケールと並列度を設計する
- 1.3.3 ステップ3:Webhookの即時応答とバックプレッシャーを制御する
- 1.3.4 ステップ4:バッチ処理、スロットリングでレート制限を遵守する
- 1.3.5 ステップ5:冪等性(Idempotency)と重複排除を実装する
- 1.3.6 ステップ6:エラー処理、リトライ、デッドレターパターンを確立する
- 1.3.7 ステップ7:実行データの保存方針を見直し、PostgreSQLの負荷を削減する
- 1.3.8 ステップ8:Redis(キュー)の可用性とパフォーマンスを確保する
- 1.3.9 ステップ9:AIワークフロー特有の最適化を行う
- 1.3.10 ステップ10:本番運用のためのセキュリティとSREプラクティスを導入する
- 1.4 ワークフロー設計パターン:具体例と実装ヒント
- 1.5 Kubernetesでのスケール指針
- 1.6 よくある質問(FAQ)
- 1.7 まとめ:強いn8nは「非同期×バッチ×冪等×保存最小×観測」で作る
n8nジョブキュー最適化と高負荷対策 完全ガイド:設計原則から実践まで
Webhookが詰まる、外部APIのレート制限でワークフローが失敗する、AIを使った処理が渋滞する…。n8nを本番環境で本格的に運用していると、誰もが一度はジョブキューの管理と高負荷対策という壁に突き当たります。そして、こう思うかもしれません。「n8nでは、この規模の処理は限界なのか?」と。
しかし、そのボトルネックは本当にn8nの限界なのでしょうか?多くの場合、それは実行アーキテクチャの選択、ワークフローの設計、そして運用方法に起因します。
この記事は、n8nをセルフホスト(Docker Compose / Kubernetes)で運用するすべての技術者のために書かれました。キュー(Redis/BullMQ)を前提とした実行アーキテクチャの解説から、負荷に強いワークフロー設計、インフラ運用、モニタリング、そして実践的なトラブルシューティングまで、本番運用で本当に役立つ知識を体系的に解説します。
単なるセットアップ手順の紹介ではありません。負荷に強い自動化基盤を構築するための設計原則と、現場で即座に効果を発揮するチューニング手法を、再現性のある形で提供します。この記事を読み終える頃には、あなたのn8nは「便利なツール」から「事業を支える堅牢な自動化基盤」へと進化しているはずです。
最初におさえるべき ポイント
時間がない方のために、この記事の最も重要な結論を先にまとめます。以下の原則を理解するだけでも、n8nのパフォーマンスは劇的に改善されるでしょう。
- 実行モードは「queue」+「プロセス分離(own)」が鉄則: Redisをジョブキューとして利用し、メインプロセスと実行ワーカーを分離します。これにより、ワーカーの水平スケールが可能になり、スループットと安定性が飛躍的に向上します。
- Webhookは「即時応答→非同期処理」へ: 「Respond to Webhook」ノードを活用し、リクエストを受け付けたら即座に
200 OKを返します。重い処理はバックグラウンドで非同期に実行することで、上流システムのタイムアウトやバックプレッシャー(処理遅延による圧力)を防ぎます。 - スループットは「ワーカー水平スケール × バッチ設計」で稼ぐ: ワーカーの数を増やすだけでなく、「Split In Batches」ノードで大量データを分割し、「Wait」ノードで間隔を調整します。これにより、外部APIのレート制限を遵守しながら、全体の処理能力を最大化します。
- 回復性のための必須設計(冪等性・リトライ・エラー処理): ワークフローは何度実行されても同じ結果になる「冪等性」を担保します。エラー発生時は、専用のエラーワークフローで検知し、計画的なリトライやデッドレターキュー(DLQ)への隔離を自動化します。
- 実行データは「成功時は保存しない」: 成功したワークフローの実行データをすべて保存すると、PostgreSQLの負荷が急増します。
EXECUTIONS_DATA_SAVE_ON_SUCCESS=noneを基本とし、データベースの肥大化を防ぎます。 - 観測して、改善する: Redisのキュー長、ワークフローの実行時間、失敗率などを常に監視します。ボトルネックをデータで特定し、的確な対策を打つことが安定運用の鍵です。
- セキュリティの基本を徹底: 本番環境ではHTTPS化、
N8N_ENCRYPTION_KEYの設定、ボリュームの永続化、リバースプロキシ(Nginx/Traefik)の導入は必須です。
これらの原則に基づき、具体的な手順を詳しく見ていきましょう。
基礎理解:n8nの実行アーキテクチャとボトルネックの正体
高負荷対策を講じる前に、n8nがどのように動作しているのか、そしてなぜ問題が起きるのかを正確に理解する必要があります。
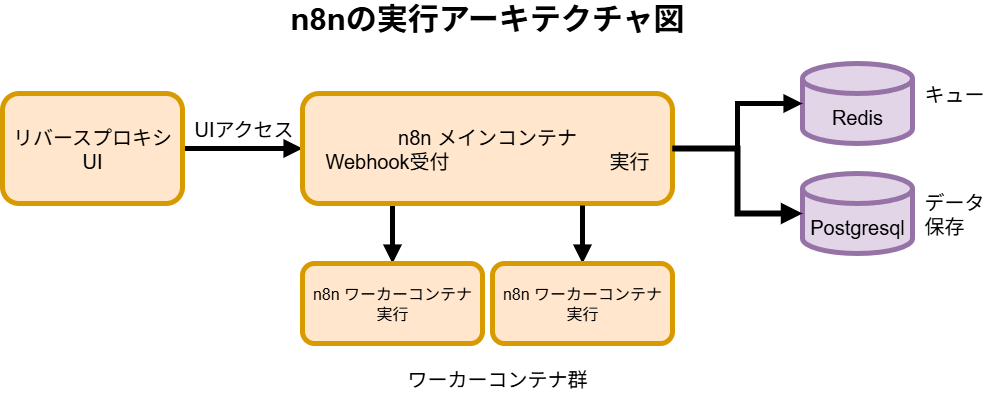
実行モードの選択がすべてを決める
n8nには主に2つの実行モードがあり、この選択がスケーラビリティを大きく左右します。
regularモード (デフォルト):単一のプロセスが、UIの提供、Webhookの受付、ワークフローの実行というすべての役割を担います。セットアップは簡単ですが、一つの重い処理が他のすべての動作をブロックしてしまうため、開発や低負荷な用途に限定されます。本番環境での高負荷運用には絶対に向きません。
queueモード:
このモードこそが、本番運用のためのアーキテクチャです。Redisをジョブキュー(タスクの待合室)として利用し、役割を分離します。- メインプロセス: UIの提供、Webhookの受付、ワークフローのスケジュール登録など、軽量なタスクを担当します。Webhookを受け付けると、実行すべきジョブをRedisのキューに登録するだけですぐに応答します。
- ワーカープロセス: Redisのキューを監視し、登録されたジョブを次々と取り出して実行することに専念します。このワーカーは複数起動でき、数を増やすことで並列処理能力を向上させられます(水平スケール)。
さらに、プロセス分離の設定も重要です。
- プロセス分離 (
EXECUTIONS_PROCESS=own):
この設定を有効にすると、各ワーカーはワークフローを実行するたびに新しい子プロセスを生成します。一つの実行がクラッシュしても他の実行に影響を与えず、メモリリークのリスクも低減します。特に、長時間実行されるAI処理や、大きなバイナリデータを扱うワークフローにおいて絶大な安定性をもたらします。
本番環境で頻発するボトルネックの正体
n8nが遅くなる、止まる原因は、主に以下の5つに集約されます。
- Webhookの同期待ち: Webhookを受け付けてから処理が完了するまで応答を返さないと、上流システムがタイムアウトしてしまい、リクエストが失敗したり、再送されて二重処理の原因になったりします。
- 外部APIのレート制限: 多くのAPIには「1秒あたり10リクエストまで」のような利用制限があります。これを無視して大量のリクエストを送ると、API側から
429 Too Many Requestsエラーが返され、ワークフローが失敗します。 - データベースの飽和: 成功した実行ログを含む大量のデータをPostgreSQLに書き込み続けると、ディスクI/OやCPUがボトルネックとなり、n8n全体のパフォーマンスが低下します。
- 長時間実行ジョブによるキューの渋滞: AIの推論や大規模なデータ変換など、一つの実行に数分かかるジョブがあると、後続の簡単なジョブが長時間待たされてしまいます。
- メモリ圧迫: 大きなファイルやAIのレスポンスなど、巨大なペイロードをメモリ上で処理しようとすると、メモリ不足(OOM Killer)でコンテナが強制終了されることがあります。
これらの問題への対処法は明確です。「非同期化」「バッチ化」「冪等化」「保存最小化」「水平スケール」「可観測性」という6つの原則に基づいて、システムを設計・運用していくことです。
実践ガイド:キュー最適化と高負荷対策の10ステップ
ここからは、理論を実践に移すための具体的な手順を10のステップで解説します。
ステップ1:本番向けDocker Composeの土台を構築する
最初のステップは、各コンポーネントが適切に分離され、永続化された構成を作ることです。以下は、本番運用を想定したdocker-compose.ymlの構成イメージです。
reverse-proxy: NginxやTraefikを使い、HTTPS通信の終端とn8nへのルーティングを担当します。Let’s Encryptによる証明書の自動更新を設定するのが一般的です。n8n-main: メインプロセス用のコンテナ。UIとWebhook受付に専念します。n8n-worker: 実行専用のワーカーコンテナ。scaleオプションで簡単に数を増減できます。postgres: ワークフロー定義や実行ログ、認証情報などを保存するデータベース。データが消えないよう、必ずボリュームをマウントして永続化します。redis: ジョブキューとして機能。こちらも永続化設定(AOF)を推奨します。
version: '3.8'
services:
# ... (Traefik or Nginx reverse proxy configuration) ...
postgres:
image: postgres:13
restart: always
environment:
- POSTGRES_USER=n8n
- POSTGRES_PASSWORD=your_secure_password
- POSTGRES_DB=n8n
volumes:
- postgres_data:/var/lib/postgresql/data
healthcheck:
test: ["CMD-SHELL", "pg_isready -U n8n"]
interval: 5s
timeout: 5s
retries: 10
redis:
image: redis:6.2-alpine
restart: always
command: redis-server --save 60 1 --loglevel warning --requirepass your_secure_redis_password
volumes:
- redis_data:/data
n8n-main:
image: n8nio/n8n
restart: always
ports:
- "127.0.0.1:5678:5678"
environment:
- DB_TYPE=postgresdb
- DB_POSTGRESDB_HOST=postgres
# ... other DB connection envs ...
- EXECUTIONS_MODE=queue
- EXECUTIONS_PROCESS=main # This container will not execute workflows
- QUEUE_BULL_REDIS_HOST=redis
- QUEUE_BULL_REDIS_PORT=6379
- QUEUE_BULL_REDIS_PASSWORD=your_secure_redis_password
# ... other essential envs like N8N_ENCRYPTION_KEY ...
volumes:
- n8n_data:/home/node/.n8n
depends_on:
postgres:
condition: service_healthy
redis:
condition: service_started
n8n-worker:
image: n8nio/n8n
command: n8n worker
restart: always
environment:
- DB_TYPE=postgresdb
- DB_POSTGRESDB_HOST=postgres
# ... same as main ...
- EXECUTIONS_MODE=queue
- EXECUTIONS_PROCESS=own # Key for stability
- QUEUE_BULL_REDIS_HOST=redis
# ... same as main ...
volumes:
- n8n_data:/home/node/.n8n
depends_on:
- n8n-main
volumes:
postgres_data:
redis_data:
n8n_data:
重要な環境変数(.envファイルに記述):
# --- Database ---
DB_TYPE=postgresdb
DB_POSTGRESDB_HOST=postgres
DB_POSTGRESDB_PORT=5432
DB_POSTGRESDB_DATABASE=n8n
DB_POSTGRESDB_USER=n8n
DB_POSTGRESDB_PASSWORD=your_secure_password
# --- Execution Mode & Queue ---
EXECUTIONS_MODE=queue
EXECUTIONS_PROCESS=own # Recommended for workers
QUEUE_BULL_REDIS_HOST=redis
QUEUE_BULL_REDIS_PORT=6379
QUEUE_BULL_REDIS_PASSWORD=your_secure_redis_password
# --- Security & Network ---
N8N_ENCRYPTION_KEY=a_very_long_and_random_string_for_encrypting_credentials # MUST BE SET
N8N_HOST=your.domain.com
N8N_PORT=5678
WEBHOOK_URL=https://your.domain.com/ # External URL
# --- Performance & Data Management (VERY IMPORTANT) ---
EXECUTIONS_DATA_SAVE_ON_SUCCESS=none
EXECUTIONS_DATA_SAVE_ON_ERROR=all
EXECUTIONS_DATA_SAVE_MANUAL_EXECUTIONS=true
EXECUTIONS_DATA_MAX_AGE=336 # Keep data for 14 days (336 hours)
# --- General ---
TZ=Asia/Tokyo
ステップ2:ワーカーの水平スケールと並列度を設計する
queueモードの最大の利点は、ワーカーをスケールさせることで処理能力を調整できる点です。
- スケール方法:
docker-compose up --scale n8n-worker=4のようにコマンドを実行するだけで、ワーカーを4つに増やせます。 - 並列度の考え方: 実際のスループットは「ワーカーの数 × 各ワーカーが並列で処理できるジョブの数」で決まります。
EXECUTIONS_PROCESS=ownを使うと、メモリ分離が強化され、重い処理でも安定して並列実行できます。 - 専用ワーカーの分離: AIの推論など、特にリソースを消費するワークフローがある場合、その処理専用のワーカー群を別のComposeファイルやKubernetesのDeploymentとして切り出すのが有効です。これにより、重い処理が他の軽快な処理を妨げる「ノイジーネイバー問題」を防げます。
ステップ3:Webhookの即時応答とバックプレッシャーを制御する
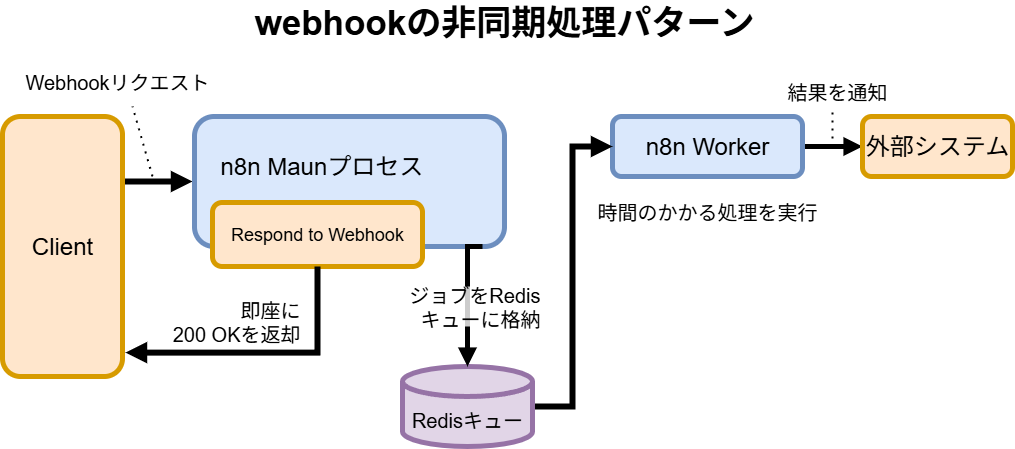
- 非同期化パターン: ワークフローの冒頭を「Webhook Trigger」→「Respond to Webhook」という構成にします。これでリクエストを受け付けた瞬間に応答を返し、上流システムを待たせません。実際の処理はその後のノードで非同期に進みます。
- 早期リジェクト: Webhookで受け取ったリクエストが不正である場合(署名検証の失敗、必須パラメータの欠損など)、キューに投入する前に
IFノードなどで弾き、早期にエラー応答を返すことで、無駄なリソース消費を防ぎます。
ステップ4:バッチ処理、スロットリングでレート制限を遵守する
- Split In Batches: 10,000件のデータを処理する場合、これを100件ずつのバッチに分割します。これにより、後続の処理が扱いやすいサイズのデータを受け取れ、メモリ効率も向上します。
- Wait: バッチとバッチの間に「Wait」ノードを挟み、例えば1秒待機させます。これで「1秒あたり100件」という単位で処理流量を制御でき、外部APIのレート制限(例: 1秒あたり10リクエスト)を正確に守ることができます。
- 指数バックオフによるリトライ: 外部APIが一時的に不安定で
503 Service Unavailableを返したり、レート制限で429 Too Many Requestsを返したりした場合、すぐにリトライするのではなく、待機時間を1秒、2秒、4秒…と指数関数的に増やしながら再試行(Exponential Backoff)します。これにより、APIの回復を待ち、無駄なリトライで状況を悪化させるのを防ぎます。
ステップ5:冪等性(Idempotency)と重複排除を実装する
冪等性とは、「同じ操作を何回繰り返しても、結果が同じになる」という性質です。ネットワーク障害などで同じWebhookが2回飛んできても、ユーザーが2人登録されるようなことがあってはなりません。
- 実装方法:
- リクエストに含まれる一意のID(
idempotency-keyヘッダやイベントID)を取得します。 - そのIDが既に処理済みかどうかを、RedisやPostgreSQLのテーブルで確認します。
- 未処理の場合のみ、処理を実行し、完了後にIDを「処理済み」として記録します。
- 処理済みの場合、何もせずに成功として終了します。
- リクエストに含まれる一意のID(
データベースへの書き込みは、単純なINSERTではなくUPSERT(ON CONFLICT DO UPDATE)を使うことで、二重登録を簡単に防げます。
ステップ6:エラー処理、リトライ、デッドレターパターンを確立する
本番環境ではエラーは必ず発生します。重要なのは、エラーを検知し、適切に処理し、回復させる仕組みです。
- エラー専用ワークフロー: 「Error Trigger」ノードを使って、失敗したすべてのワークフロー実行を補足する専用のワークフローを作成します。
- エラー処理の内容:
- 通知: Slackやメールで開発者に即時通知します。エラーメッセージ、ワークフロー名、実行IDなどの情報を含めます。
- 分類とリトライ: エラーの種類を判別します。一時的なエラー(ネットワーク障害など)であれば、少し待ってから自動でリトライさせます。恒久的なエラー(データ形式の誤りなど)であれば、リトライを諦めます。
- デッドレターキュー(DLQ): 自動リトライしても解決しないエラーは、DLQに相当する場所(例えばPostgreSQLの特定テーブルや別のキュー)に隔離します。これにより、問題のあるジョブがキューを詰まらせるのを防ぎます。
- 手動での再実行: DLQに隔離されたジョブは、開発者が原因を調査・修正した後、手動で再実行できる仕組み(例: 専用の管理画面やWebhook)を用意しておくと、運用が格段に楽になります。
ステップ7:実行データの保存方針を見直し、PostgreSQLの負荷を削減する
n8nのデフォルト設定では、成功した実行データもすべてデータベースに保存されます。これはデバッグには便利ですが、高負荷環境ではデータベースを圧迫する最大の原因となります。
- 保存は最小限に:
EXECUTIONS_DATA_SAVE_ON_SUCCESS=noneを設定し、成功した実行データは保存しないようにします。失敗時のデータは原因調査に不可欠なため、EXECUTIONS_DATA_SAVE_ON_ERROR=allで詳細を保存します。 - 定期的な自動削除:
EXECUTIONS_DATA_MAX_AGEで、古い実行データの保持期間を設定します(例: 14日間)。これにより、データベースが無限に肥大化するのを防ぎます。 - DBチューニング: PostgreSQLの
work_memやshared_buffersなどのパラメータを、サーバーのメモリに合わせて調整します。また、VACUUMが定期的に実行されていることを確認します。
ステップ8:Redis(キュー)の可用性とパフォーマンスを確保する
ジョブキューであるRedisは、システム全体の心臓部です。ここが止まると、すべての非同期処理が停止します。
- 永続化: RedisのAOF(Append Only File)永続化を有効にし、サーバーが再起動してもキューの中身が消えないようにします。
- メモリ管理:
maxmemory-policyはnoevictionに設定し、メモリ不足でキューのデータが勝手に削除されないようにします。必要なメモリ量を見積もり、十分なリソースを割り当てます。 - 監視: Redisのメモリ使用量、クライアント接続数、そして最も重要なキューの長さ(滞留しているジョブの数)を常に監視し、異常があれば即座にアラートが飛ぶようにします。
ステップ9:AIワークフロー特有の最適化を行う
LLMや画像生成AIを組み込んだワークフローは、特にリソースを消費し、実行時間も長くなりがちです。
- 専用ワーカーへの隔離: 前述の通り、AI処理は他のワークフローとリソースを奪い合わないよう、専用のワーカー群に隔離するのが賢明です。
- 巨大ペイロードの回避: AIからのレスポンスや生成された画像データは非常に大きくなることがあります。これらのデータをn8nの実行データとして直接引き回すのではなく、オブジェクトストレージ(S3など)に一旦保存し、n8n内ではそのURLだけをやり取りするように設計します。
- タイムアウトとコスト管理: 外部LLMのAPI呼び出しには、適切なタイムアウトを設定します。また、失敗時の無駄なリトライがAPI利用料の増大につながらないよう、リトライ回数には厳密な上限を設けます。
ステップ10:本番運用のためのセキュリティとSREプラクティスを導入する
機能するだけでは不十分です。安全で信頼性の高いシステムとして運用するためのプラクティスを導入します。
- HTTPS必須: ngrokでHTTPSトンネリングするかリバースプロキシでHTTPSを終端し、Let’s Encryptで証明書を自動更新します。これにより、通信が暗号化され、多くの外部サービスとのOAuth連携が可能になります。
- 資格情報の暗号化:
N8N_ENCRYPTION_KEYを必ず設定し、安全な場所に保管します。このキーがないと、保存した認証情報が復号できなくなります。 - ログの一元管理: すべてのコンテナの標準出力を、LokiやElasticsearchのようなログ集約基盤に転送します。これにより、障害発生時に横断的な原因調査が容易になります。
- アラート設定: 「キューの長さが100を超えたら」「5分間のエラー率が5%を超えたら」といった具体的な閾値を定め、アラートを設定します。問題の兆候を早期に捉え、大きな障害に発展する前に対処します。
- バックアップとリストア訓練: PostgreSQLの定期的なバックアップは必須です。さらに、そのバックアップから実際にリストアする訓練を定期的に行い、いざという時に確実に復旧できることを確認しておきます。
ワークフロー設計パターン:具体例と実装ヒント
理論だけでなく、具体的なワークフローの組み方を見ていきましょう。
| パターン名 | 使いどころ | 実装のコツ |
|---|---|---|
| Respond Early(即時応答) | Webhook起点で、上流システムを待たせたくない場合。 | 「Webhook」→「Respond to Webhook」で即座に応答を返す。実際の処理はその後のノードで行う。 |
| ファンアウト/バッチ集約 | 大量のデータを分割処理したり、APIのレート制限に対応したりする場合。 | 「Split In Batches」で分割し、ループ内で処理。ループの最後に「Wait」を挟んで流量を制御する。 |
| 冪等UPSERT | データベースへの二重登録を防ぎたい場合。 | 外部キーや一意のIDを使ってレコードを検索。存在すればUPDATE、存在しなければINSERT(UPSERT)する。 |
| サーキットブレーカー | 依存する外部APIが不安定な場合に、システム全体への影響を抑えたい場合。 | エラーカウンターをRedisなどで管理。連続エラーが閾値を超えたら、一定時間API呼び出しを停止し、代替処理(フォールバック)に切り替える。 |
| メタデータ最小化 | 実行データが肥大化し、DBを圧迫するのを防ぎたい場合。 | 大きなデータはS3などに保存し、n8nではそのURLやIDのみを保持する。成功時は結果のサマリだけを記録する。 |
Kubernetesでのスケール指針
Docker Composeからさらに進んだ環境として、Kubernetesを利用する場合の要点も押さえておきましょう。
- Pod分離:
main,worker,redis,postgresをそれぞれ別のDeploymentやStatefulSetとして定義します。 - 自動スケール:
HorizontalPodAutoscaler (HPA)を使い、Redisのキュー長やCPU使用率といったメトリクスに基づいて、workerのPod数を自動で増減させます。 - Ingress: Ingressコントローラを利用して、TLS終端と高度なルーティングを実現します。
- 永続ボリューム:
PersistentVolumeとStorageClassを使い、PostgreSQLやRedisのデータを信頼性の高いストレージに永続化します。
よくある質問(FAQ)
Q1: regularモードでもワーカーは増やせますか?
A: いいえ、できません。ワーカーによる並列実行と負荷分散は、queueモードの利用が前提です。小規模なテスト用途以外では、常にqueueモードを選択してください。
Q2: 適切なワーカー数はどうやって決めればよいですか?
A: 決まった答えはありません。ワークフローの特性(CPU負荷、I/O負荷、外部APIの待ち時間)に大きく依存します。まずは2〜4程度のワーカーから始め、負荷テストを行いながら、キューの待ち時間や成功率といったSLO(サービスレベル目標)を満たす最小限の数を見つけ出し、そこに少し余裕を持たせるのが良いアプローチです。
Q3: 外部APIの厳しいレート制限にどう対応すればいいですか?
A: まず「Split In Batches」で処理単位を小さくし、「Wait」で実行間隔を空けるのが基本です。それでも上限に達する場合は、指数バックオフによるリトライを実装します。根本的には、APIを呼び出す総量を減らせないか(差分更新にする、キャッシュを利用するなど)検討することも重要です。
Q4: 実行データを残さないと、後から処理内容を確認できず困りませんか?
A: そのトレードオフは常に存在します。基本戦略は「失敗時のみ詳細なデータを保存し、原因調査に役立てる。成功時は、重要なIDや結果のサマリなど、最小限のログ情報だけを専用のログ基盤(ELKなど)に出力する」というものです。これにより、DBの負荷と可監査性のバランスを取ります。
Q5: HTTPSは本当に必須ですか?ローカル開発でも必要ですか?
A: 本番環境では絶対に必須です。通信の暗号化はセキュリティの基本であり、多くの外部サービスとのOAuth認証でも前提条件となります。ローカル開発では、自己署名証明書を使うことでテストが可能ですが、公開環境では必ずリバースプロキシとLet’s Encryptなどによる正規の証明書を使用してください。
まとめ:強いn8nは「非同期×バッチ×冪等×保存最小×観測」で作る
n8nのスケーラビリティは、単一の設定やトリックで実現されるものではありません。アーキテクチャ、設計、運用の各レイヤーで、適切な原則を適用することによってのみ達成されます。
- アーキテクチャ:
queueモード+ワーカー分離(own)を基本とし、水平スケール可能な基盤を整える。 - 設計: Webhookは即時応答で非同期化し、大量データはバッチ処理で流量を制御する。そして、すべての処理を冪等に設計し、障害からの回復力を高める。
- 運用: 実行データは最小限しか保存せず、DBの健康を保つ。そして、システムのあらゆる側面を監視し、データに基づいて継続的な改善を行う。
もしあなたが今、n8nのパフォーマンスに悩んでいるなら、まずは以下のステップから始めてみてください。
次のアクションプラン
- 実行モードの見直し: 現在の環境が
regularモードなら、すぐにqueueモードへの移行計画を立てる。 - 保存ポリシーの変更:
.envファイルでEXECUTIONS_DATA_SAVE_ON_SUCCESS=noneとEXECUTIONS_DATA_MAX_AGEを設定する。 - Webhookの非同期化: 最も頻繁に呼び出されるWebhookワークフローに「Respond to Webhook」ノードを導入する。
- エラー処理の導入: 「Error Trigger」を使った基本的なエラー通知ワークフローを作成する。
- 監視の第一歩: 最低限、Redisのキュー長だけでも監視を始める。
この一連の取り組みを通じて、あなたのn8nは単なる自動化ツールから、ビジネスの成長を支える強力でスケーラブルな基盤へと変貌を遂げるでしょう。負荷に怯える日々は終わりです。自信を持って、自動化の世界をさらに推し進めていきましょう。

