

- 1 n8nで実現するオーケストレーターAIエージェント:設計原則・実装レシピ・運用プラクティスガイド
- 2 はじめに:なぜ今、n8nでAIエージェントを「オーケストレーション」するのか
- 3 基礎理解:AIワークフロー/AIエージェント/エージェンティックAIの違い
- 4 n8nを選ぶ理由:開発者に効く自由度とコスト最適性
- 5 アーキテクチャ設計:オーケストレーターAIエージェントの基本構造
- 5.1.1 1) エントリ/トリガー (Entry / Trigger)
- 5.1.2 2) セッション/メモリ管理 (Session / Memory Management)
- 5.1.3 3) コンテキスト収集 (RAG – Retrieval-Augmented Generation)
- 5.1.4 4) プランニング (オーケストレーター) (Planning / Orchestrator)
- 5.1.5 5) 実行 (ツールハンドラ) (Execution / Tool Handler)
- 5.1.6 6) 検証/評価 (Verification / Evaluation)
- 5.1.7 7) 出力/人手介入 (Output / Human-in-the-Loop)
- 5.1.8 8) ログ/監視/分析 (Logging / Monitoring / Analytics)
- 6 実践ガイド:n8nでの構築手順(レシピ完全版)
- 7 コンテキスト維持の実務:メモリの正攻法
- 8 デバッグ・テスト:JSON地獄から抜け出す手順
- 9 スケーリングとコスト最適化:Queueモードと賢い節約術
- 10 FAQ(よくある質問)
- 11 おわりに:理想と現実をつなぐのは「設計の地力」
n8nで実現するオーケストレーターAIエージェント:設計原則・実装レシピ・運用プラクティスガイド
はじめに:なぜ今、n8nでAIエージェントを「オーケストレーション」するのか
SaaS連携による業務自動化は飛躍的に進みました。しかし、私たちの日常業務には依然として「人間による判断」が必要な、非定型なプロセスが数多く残されています。問い合わせ内容の意図を汲み取って適切な資料を探す、複数の情報源からデータを集めてレポートの骨子を作成する、顧客との過去のやり取りを踏まえてメールの文面を調整する??。
生成AIの登場は、これらの知的タスクを自動化する「AIエージェント」という新たな可能性を切り開きました。しかし、多くの技術者がプロトタイプ開発で壁にぶつかります。チュートリアル通りに作ってみたものの、会話の文脈を維持できない、複雑な処理をさせるとデバッグが困難になる「JSON地獄」に陥る、本番運用に耐えうるスケーラビリティやセキュリティを確保できない、といった現実的な課題です。
この記事は、オープンソースのワークフロー自動化ツール「n8n」を使い、実務に耐えうる堅牢な「オーケストレーターAIエージェント」を設計・実装・運用するための、包括的な実践ガイドです。単なるLLMのAPI連携にとどまらず、LangChainノードの活用、RAG(Retrieval-Augmented Generation)の組み込み、サブワークフローによる処理のモジュール化、キュー実行によるスケーリング、そして監視・テスト・コスト管理といった、競合記事が十分に触れてこなかった「運用の現実」に深く踏み込みます。
この記事を読み終える頃には、あなたは単なるプロトタイプではなく、ビジネスの現場で価値を生み出し続けるAIエージェントを構築するための、明確な設計図と具体的な実装手順を手にしているはずです。
要点サマリ(すぐに実装したい方へ)
- AI自動化の3階層を理解する: 自動化の成熟度を3つのレベルで捉え、現在のニーズに合った層を見極めることが重要です。
- AIワークフロー: 事前に定義された手順を実行する(例:メール要約→チケット起票)。
- AIエージェント: 自律的に思考・行動し、ツールを使いこなし目的を達成する。
- エージェンティックAI: 複数の専門エージェントが協調して、より大きな目標に取り組む。
- n8nが選ばれる理由: 開発者にとっての自由度と実用性が最大の魅力です。
- データ主権と拡張性: セルフホスト可能で、機密データを自社インフラ内で管理できます。
- 強力なLangChain統合: 約70種類の関連ノードを駆使し、RAGやエージェント機能をローコードで構築できます。
- コードによる柔軟性: 標準のJavaScript実行に加え、Python連携も可能。NPMパッケージも利用でき、複雑な処理にも対応します。
- コスト最適化: セルフホストにより、特にAPI呼び出しが多いAI処理において実行コストを大幅に削減可能です。
- 本番運用の難所を乗り越える: 設計段階から以下の点を考慮することが成功の鍵です。
- コンテキスト維持、ノード間のデータ連携、APIのレート制限、そしてシステムの観測性(Observability)。これらを見越して、メモリ戦略、テレメトリー、キュー実行を標準装備として計画します。
- 最重要の設計原則: 堅牢なシステムは優れた設計から生まれます。
- 役割の分離: 思考役の「オーケストレーター(Planner)」と実行役の「ツール(Executor)」を明確に分離します。
- 知識の拡張: RAGによる外部知識の参照と、判断に迷った際の「人手介入(Human-in-the-Loop)」をアーキテクチャに組み込みます。
- 標準化: セッション管理、永続メモリ、スロットリング、エラーリカバリといった仕組みを標準部品として整備します。
- 具体的な構築レシピ: 以下のステップで段階的に実装を進めます。
- ドキュメント取り込み: 文書を分割→ベクトル化→ベクターストアへ格納。
- 問い合わせ処理: 関連情報を検索(リトリーバル)→行動計画を立案(プランニング)→ツールを実行→結果を検証・要約→出力。
- 運用の肝: システムを安定稼働させ、継続的に改善するためのポイントです。
- スケーラビリティ: Queueモードとワーカーの水平スケールで高負荷に対応します。
- 品質とコスト管理: ベンチマークテストとコスト上限設定を徹底します。
- 信頼性: プロンプトの出力をJSONモードで契約化し、スキーマ検証を行います。実行ログには相関IDを付与し、個人情報はマスキングします。
- ツール選定の指針: 適材適所でツールを使い分けることが重要です。
- n8n: 技術者がAPI、DB、RAG、エージェントを深く作り込み、運用まで責任を持つ場合に最適。
- Zapier: 非技術者でも使える手軽さ。定型的なSaaS連携に。
- Make: ノーコードで複雑な分岐やデータ操作を行いたい場合に。
- Dify: AIアプリ開発、特にプロンプトエンジニアリングや評価に特化。n8nと連携させることで両者の強みを活かせます。
基礎理解:AIワークフロー/AIエージェント/エージェンティックAIの違い
AIによる自動化を成功させるには、まずその成熟度レベルを正しく理解し、解決したい課題に最適なアプローチを選択することが不可欠です。
1. AIワークフロー (AI-Powered Workflow)
- 特徴: これは、あらかじめ人間が定義した一連の手順(ワークフロー)の中に、LLMによるテキスト処理(要約、分類、翻訳など)を組み込んだものです。「トリガーが発火したら、A→B→Cの順で処理する」というルールベースの自動化が基本です。
- 適用例: 顧客からの問い合わせメールをトリガーに、内容をLLMで要約・カテゴリ分類し、その結果を基に社内チケットシステムに起票し、担当部署のSlackチャンネルに通知する。
- 勘所: 定型的なタスクの効率化に絶大な効果を発揮します。再現性が高く、動きが予測可能なため、管理しやすいのがメリットです。想定外のケースは、人間にエスカレーションする設計が基本となります。
2. AIエージェント (AI Agent)
- 特徴: AIエージェントは、単に決められた手順をこなすだけではありません。「最終的な目的」を与えられると、それを達成するために自律的に「思考→行動→観察」のサイクル(ReActフレームワークなどが有名)を繰り返します。その過程で、Web検索、データベース参照、API呼び出しといった様々な「ツール」を状況に応じて使い分けます。
- 適用例: 「競合製品Aの最新の市場評価について調査し、サマリーレポートを作成して」という目的を与えると、エージェントは自らWeb検索ツールで関連ニュースやレビューを収集し、それらを分析・要約してレポートを生成します。
- 勘所: 情報探索や意思決定補助など、ある程度の自律性が求められる半定型的なナレッジワークに適しています。自由度が高い分、意図しない動作をするリスクもあり、適切な制約や監視が重要になります。
3. エージェンティックAI (Agentic AI)
- 特徴: これは、複数の専門的な役割を持つAIエージェントが協調し、一つの大きな目標を達成するシステムです。例えば、「リサーチ担当エージェント」「分析・執筆担当エージェント」「校閲・レビュー担当エージェント」がチームを組み、それぞれの専門性を活かして相互に作用します。全体を統括する「オーケストレーター」が、各エージェントのタスク割り当てや連携を管理します。
- 適用例: 新規事業の企画立案。リサーチ担当が市場データを集め、分析担当が事業計画のドラフトを作成し、レビュー担当がリスク評価を行う、といった一連のプロセスをAIチームで実行します。
- 勘所: 大規模で複雑なプロジェクトや、多角的な視点が必要な業務に適しています。構築と管理の難易度は高くなりますが、人間とAIの協業を新たなレベルに引き上げる可能性を秘めています。
実務においては、まず単純な「AIワークフロー」から始め、徐々にRAG(後述)を組み込んで知識を拡張し、必要に応じて自律的な「AIエージェント」へと進化させていくのが、着実で現実的なアプローチです。
n8nを選ぶ理由:開発者に効く自由度とコスト最適性
数ある自動化ツールの中で、なぜ技術的な作り込みを要するAIエージェントの基盤としてn8nが適しているのでしょうか。その理由は、開発者にとって魅力的な以下の特徴に集約されます。
- セルフホストとデータ主権 (Self-Hosting & Data Sovereignty)
社内の機密文書や顧客データといったセンシティブな情報を扱う際、データを外部のクラウドサービスに預けることに抵抗があるケースは少なくありません。n8nはセルフホストが可能なため、自社のインフラ(オンプレミスまたはプライベートクラウド)上でシステムを完結させることができます。これにより、日本の個人情報保護法(APPI)や業界固有の厳しいガイドラインを遵守しやすくなり、データ主権を完全に維持できます。 - LangChain統合と充実したAIノード群 (LangChain Integration & Rich AI Nodes)
n8nは、LLMアプリケーション開発フレームワークであるLangChainと深く統合されており、約70種類ものAI関連ノードが標準で提供されています。これにより、RAGの構築に必要なテキスト分割、ベクトル化、ベクターストアへの格納・検索といった一連の処理や、エージェントの思考プロセスなどを、複雑なコーディングなしにローコードで組み立てることが可能です。 - コードによる無限の拡張性 (Extensibility with Code)
ローコードの便利さを享受しつつも、標準ノードだけでは対応できない特殊な処理が必要になる場面は必ず訪れます。n8nのCodeノードやFunctionノードを使えば、JavaScript(Node.js)を直接実行できます。セルフホスト環境ではNPMパッケージを追加することも可能で、専門的なライブラリを活用したデータ処理や、独自の認証ロジックの実装も自由自在です。Pythonを使いたい場合も、専用ノードや外部コマンド実行、コンテナ連携といった方法で対応できます。 - 卓越したコスト効率 (Cost-Effectiveness)
AIエージェント、特にRAGやマルチステップの処理を行うシステムは、多数のLLM APIコールを伴います。SaaS型の自動化ツールでは、実行回数やステップ数に応じた課金がコストを押し上げる要因となりがちです。セルフホストのn8nでは、インフラコストはかかるものの、実行ごとの追加料金は発生しません。これにより、高頻度で実行されるワークフローの運用コストを劇的に削減できたという実例も報告されており、コストを気にせずトライ&エラーを繰り返せる環境は、AI開発において大きなアドバンテージとなります。 - 本番運用に耐えるアーキテクチャ (Production-Ready Architecture)
n8nはプロトタイピングツールにとどまりません。Redisをバックエンドにしたキュー実行モード(Queue Mode)に切り替えることで、大量のリクエストをキューイングし、複数のワーカープロセスで並列処理することが可能です。これにより、ワーカーを水平スケールさせることで、高いスループットを実現できます。Webhook、サブワークフロー、堅牢なエラーハンドリング機構も備わっており、ビジネスの根幹を支えるシステムの基盤として十分な信頼性を確保できます。
他ツールとの使い分け指針
- Zapier: 非技術者の方が、主にSaaS間の定型的な連携を迅速に設定したい場合に最適です。AI機能は搭載されていますが、簡易的な用途に限定されます。
- Make (旧Integromat): ノーコードで、より複雑な条件分岐やデータマッピングを含むフローを構築したい場合に強みを発揮します。ビジュアルなUIで完結させたい場合に適しています。
- Dify: AIチャットボットやAIアプリの開発、特にプロンプトの管理・評価(PromptOps)に特化したプラットフォームです。DifyでAIアプリケーションのコア部分を作り、n8nでその周辺のデータ連携やバックエンド処理をオーケストレーションする、という組み合わせは非常に強力です。
- n8n: 技術者が主体となり、API、データベース、RAG、カスタムコードを駆使して、システム全体を深く制御したい場合に最適です。監視やスケーリングといった運用面の責任も自社で持つチームにとって、最も自由度とパワーを発揮する選択肢です。
アーキテクチャ設計:オーケストレーターAIエージェントの基本構造
堅牢で拡張性の高いAIエージェントを構築するには、場当たり的な実装ではなく、最初にしっかりとした論理的な構造設計を行うことが極めて重要です。以下に、我々が推奨する基本アーキテクチャの構成ブロックを示します。
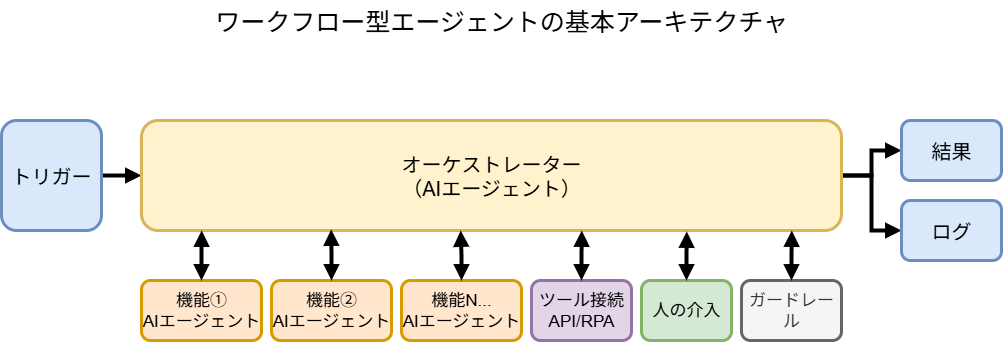
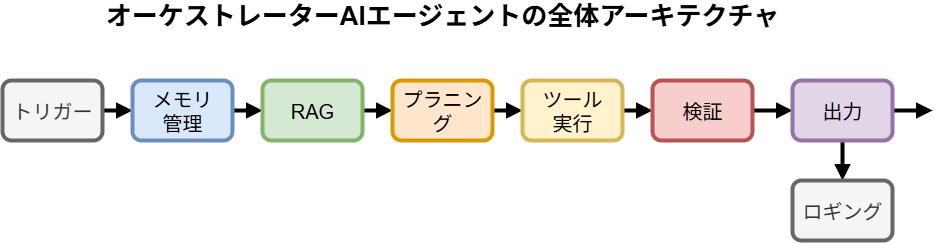
オーケストレーターAIエージェントの例(全てを実装している訳ではありません)
1) エントリ/トリガー (Entry / Trigger)
- 役割: エージェントを起動する起点です。
- 実装: Webhook(APIコール)、キューからのメッセージ受信、定期実行(Cron)、社内チャット(Slack/Teams)への投稿など、ユースケースに応じて選択します。ここで、後続の処理を追跡するためのユニークな
correlation_id(相関ID)を必ず付与します。
2) セッション/メモリ管理 (Session / Memory Management)
- 役割: 対話の文脈を維持するための「短期記憶」を管理します。
- 実装: ユーザーIDや会話IDをキーにして、過去のやり取りをデータベースに保存・読み込みします。無限に履歴を保持するとコストとノイズが増えるため、直近のK件の会話履歴に加えて、それ以前の対話を要約した「サマリスナップショット」を保持するハイブリッド方式が効果的です。
3) コンテキスト収集 (RAG – Retrieval-Augmented Generation)
- 役割: 対話の文脈だけでは不足する専門知識や最新情報を補うための「長期記憶」です。
- 実装: ユーザーの質問を基に、社内ドキュメントやナレッジベースが格納されたベクターストアから関連性の高い情報を検索(リトリーバル)します。特に日本語文書の場合、文書を意味のある塊に分割する「チャンキング」戦略が検索精度を大きく左右します。
4) プランニング (オーケストレーター) (Planning / Orchestrator)
- 役割: エージェントの「頭脳」です。受け取った目的と収集したコンテキストを基に、「何を」「どの順番で」「どのツールを使って」実行すべきかの行動計画を立案します。
- 実装: LLM(大規模言語モデル)に対して、思考プロセスと最終的な行動計画をJSON形式で出力させるプロンプトを設計します。ここでのプロンプトエンジニアリングが、エージェント全体の性能を決定づける最も重要な要素となります。
5) 実行 (ツールハンドラ) (Execution / Tool Handler)
- 役割: プランナーが立案した計画を実行する「手足」です。
- 実装: HTTPリクエスト、データベースクエリ、Web検索、計算、社内API呼び出しなど、具体的なアクションを実行するn8nノードやサブワークフロー群です。各ツールは、何度実行しても同じ結果になる「べき等性(idempotency)」を意識して設計することが重要です。
6) 検証/評価 (Verification / Evaluation)
- 役割: 実行結果が目的を達成しているか、品質基準や社内ポリシーに準拠しているかをチェックする「品質保証」の役割を担います。
- 実装: 実行結果を別のLLMやルールベースのチェッカーに通し、目標達成度、個人情報(PII)の漏洩、不適切な表現、根拠の有無などを検証します。問題があれば、再度プランニングのステップに戻す(再プランニング)か、人手にエスカレーションします。
7) 出力/人手介入 (Output / Human-in-the-Loop)
- 役割: 最終的な成果物をユーザーに提供、または人間の承認を仰ぐプロセスです。
- 実装: 自動で回答を確定する場合と、リスクの高い操作(例:顧客へのメール送信、契約関連文書の生成)の前に人間の承認を求める場合があります。承認プロセスは、SlackやTeamsに承認・却下ボタン付きのメッセージを送信し、その応答をWebhookで受け取る形でシンプルに実装できます。
8) ログ/監視/分析 (Logging / Monitoring / Analytics)
- 役割: システム全体の健全性を維持し、継続的な改善を行うための基盤です。
- 実装: 全てのステップの実行ログ(入力、出力、実行時間、トークン消費量、コストなど)を、
correlation_idで紐付けて記録します。これらのメトリクスを集計し、成功率、レイテンシ、コストなどを可視化するダッシュボードを構築することで、性能のボトルネックや改善点を発見できます。
実践ガイド:n8nでの構築手順(レシピ完全版)
ここからは、前述のアーキテクチャをn8nで具体的に構築していくためのステップ・バイ・ステップのレシピを解説します。
前提条件
- n8n環境: セルフホスト環境が構築済みであること(Dockerでのデプロイを強く推奨)。データベースには、保守性と拡張性のため、デフォルトのSQLiteではなくPostgreSQLを別コンテナで用意します。
- LLMプロバイダ: OpenAI, Anthropic, Google Geminiなど、利用したいLLMのAPIキーが取得済みであること。日本語の処理性能を考慮し、目的に応じて高精度なモデルと低コストなモデルを使い分けられるように準備しておくと良いでしょう。
- ベクターストア: Chroma, pgvector, Weaviate, Pineconeなど、RAGの知識源を格納するベクターストアが利用可能であること。社内環境で手軽に始めるなら、PostgreSQLの拡張機能であるpgvectorが運用しやすい選択肢です。
n8nで作るRAG実装ガイド:Postgres PGVector Storeで実現する実運用レベルの社内AI はじめに:その社内文書、AIで「使える資産」に変えませんか? 「社内の膨大なドキュメントから、必要な情報を根拠付きで[…]
1. セットアップ(最小構成から本番構成へ)
- 開発用(単一プロセス):
- まずはシンプルな
docker runコマンドやDocker Composeでn8nを起動します。この時点ではDBにSQLiteを使い、手早く開発を始めることができます。 - 必ず環境変数
N8N_ENCRYPTION_KEYを設定し、資格情報(Credentials)が安全に暗号化されるようにしてください。 - ローカル開発であっても、SSL化はリバースプロキシ(Nginx, Caddyなど)を前段に置く構成を推奨します。
- まずはシンプルな
- 本番用(Queueモード):
- Redisを導入し、環境変数
N8N_EXECUTIONS_MODE=queueを設定します。 - n8nのプロセスを、リクエストを受け付ける
webhookプロセスと、実際の処理を行うworkerプロセスに分離します。これにより、重い処理が実行されていても、Webhookは即座に応答を返すことができます。 - Workerの数は、CPUコア数や外部APIのレート制限(RPS: Requests Per Second)を考慮して設定します(例:同時実行数は、依存する外部APIのRPSの80%程度に抑える)。
- データベースはPostgreSQLに移行し、永続ストレージと定期的なバックアップ計画を確立します。
- Redisを導入し、環境変数
2. 資格情報と秘密管理
- n8nのCredentials機能を使って、APIキーやデータベースのパスワードを安全に保存します。ワークフロー内に直接書き込むのは絶対に避けてください。
- 各Credentialsには、必要最小限の権限(least privilege)のみを付与したアカウントを使用します(例:データベース接続には読み取り専用ユーザーを使う)。
- 監査対応のため、n8nのアクセスログやワークフローの変更履歴を定期的にエクスポート、または外部のログ管理システムに転送する仕組みを検討します。
3. ドキュメント取り込み(RAGインジェスト用ワークフロー)
これは、RAGの知識源となるドキュメントをベクターストアに登録するための、一度だけ、あるいは定期的に実行するワークフローです。
- トリガー: クラウドストレージ(S3, Google Driveなど)へのファイル追加を検知するWebhook、またはCronノードによる定期的なディレクトリのスキャン。
- 前処理: ファイルの拡張子などからタイプ(PDF, Docx, HTML, TXT)を判別します。
- 分割 (Chunking): LangChain Text Splitter系のノードを使用します。日本語は単語の区切りが曖昧なため、単純な文字数での分割は性能が低下しやすいです。「句点(。)や改行を基準に大まかに分割し、長すぎる塊はさらに再帰的に分割する」戦略が有効です。チャンクサイズは400?800トークン、チャンク間のオーバーラップは80?120トークン程度が一般的な出発点です。
- 正規化: 文書から不要なヘッダーやフッター、無関係な改行を削除します。表形式のデータは、可能であれば構造を保ったままテキストに変換します。
- 埋め込み (Embedding): テキストチャンクをベクトルに変換します。コストと精度のバランスを考え、モデルを選択します(例:法務文書のような厳密性が求められるものは高精度モデル、社内FAQのような一般的な内容は軽量モデル)。
- ベクターストア格納: ベクトルデータと共に、メタデータ(文書の出典、部署、機密区分、作成日、バージョンなど)を必ず格納します。これが後々の検索精度向上(メタデータフィルタリング)に不可欠です。
- エラーハンドリング: パースに失敗したファイルは、隔離フォルダに移動させ、その旨を管理者に通知する仕組みを用意します。
サンプル(Codeノード):日本語の句点を意識した擬似的なテキスト分割
// これは概念を示す擬似コードです。
// 実際にはLangChainのRecursiveCharacterTextSplitterの利用を推奨します。
const text = $json.body.text || '';
const MAX_CHUNK_LENGTH = 500; // 文字数ベースの上限
const chunks = [];
let currentChunk = '';
// テキストを句点(。)で分割
const sentences = text.split('。');
for (let i = 0; i < sentences.length; i++) {
const sentence = sentences[i];
if (!sentence.trim()) continue;
const sentenceWithPeriod = sentence + '。';
// 現在のチャンクに追加しても上限を超えないかチェック
if ((currentChunk + sentenceWithPeriod).length <= MAX_CHUNK_LENGTH) {
currentChunk += sentenceWithPeriod;
} else {
// 上限を超える場合は、現在のチャンクを保存して新しいチャンクを開始
if (currentChunk) {
chunks.push({ text: currentChunk.trim() });
}
// 長すぎる単一の文はそのままチャンクにする(あるいはさらに分割するロジックを追加)
currentChunk = sentenceWithPeriod;
}
}
// 最後のチャンクを追加
if (currentChunk) {
chunks.push({ text: currentChunk.trim() });
}
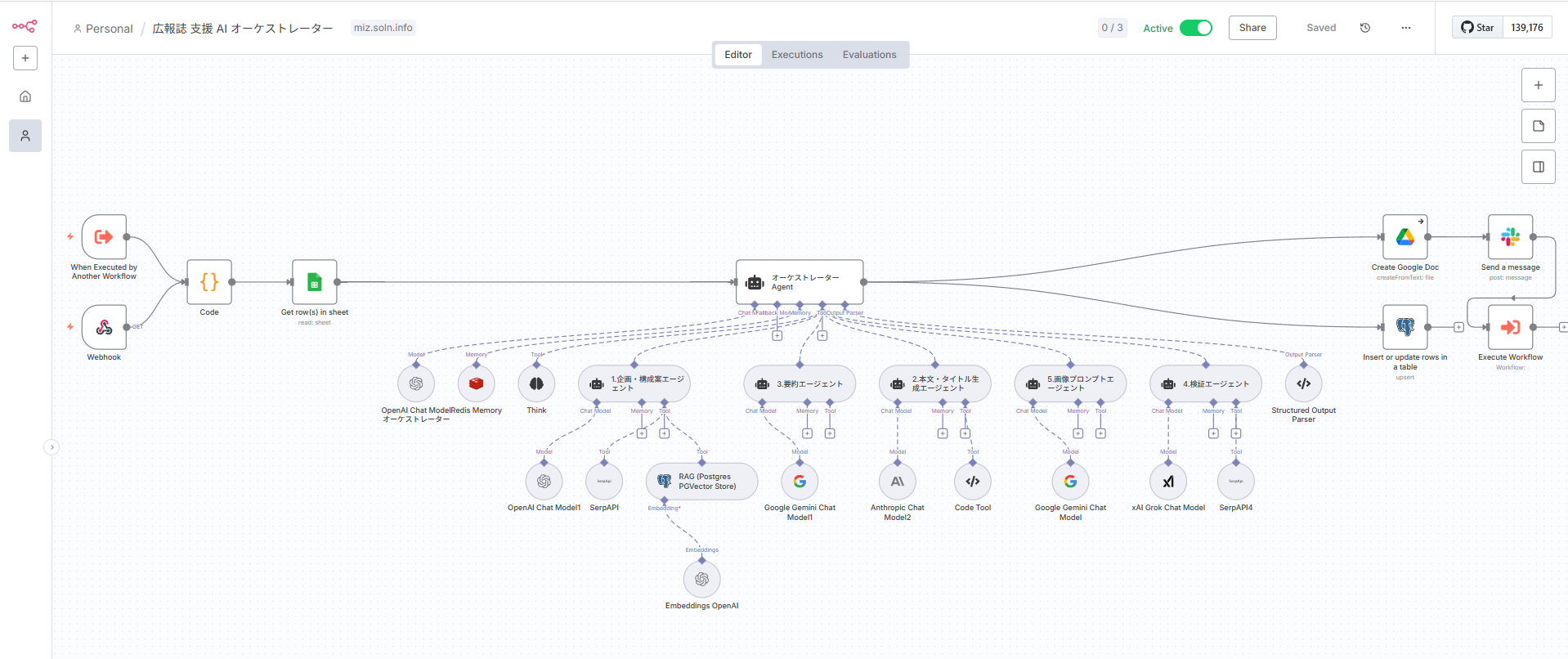
return chunks;4. 推論時ワークフロー(問い合わせからエージェント実行まで)
こちらがユーザーからのリクエストを処理するメインのワークフローです。
- トリガー: Webhookノード。入力JSONには
correlation_id(なければ生成)、user_id、session_id、適用すべきpolicy(ポリシー)タグなどを含めることを推奨します。 - セッション管理:
user_idとsession_idをキーに、DBから過去の会話履歴を取得します。 - RAG: ユーザーのクエリをベクトル化し、ベクターストアを検索してTop-K件の関連文書を取得します。取得した文書をそのまま使うのではなく、検索結果を再度LLMで評価し、関連性の高い順に並べ替える再ランキング(Re-ranking)を行うと、ノイズが減り精度が向上します。
- プランニング (オーケストレーター): 取得した会話履歴とRAGの検索結果をコンテキストとしてLLMに渡し、「行動計画」をJSON形式で出力させます。必ずLLMのJSONモードを有効にし、n8n側でJSONスキーマ検証を行うことで、後続の処理が安定します。
- 実行: プランナーが出力したJSONに基づき、
SwitchノードやIFノードで処理を分岐させ、対応するツールを実行します。ツールはそれぞれサブワークフローとして実装すると、再利用性が高まり、メインワークフローがシンプルに保てます。各ツールにはタイムアウトとリトライ処理(指数バックオフ付き)を設定します。 - 評価: ツールの実行結果を評価し、目的が達成されたか、あるいは追加のアクションが必要かを判断します。必要であれば、再度プランニングのステップに戻ります。
- 出力: 最終的な回答を生成します。その際、回答の根拠となったRAGの参照元ドキュメントへのリンクをリストとして併記することで、回答の信頼性が格段に向上します。
オーケストレーター用プロンプトの例(抜粋)
# Role
あなたは、ユーザーの質問に対して社内ナレッジベースから最適な回答を導き出すための、優秀なプランナーです。あなたの仕事は回答を生成することではなく、回答を生成するための最適な「計画」をJSON形式で出力することです。
# Context
- ユーザーの質問: {{ $json.userInput }}
- 会話履歴: {{ $json.chatHistory }}
- 関連ナレッジ: {{ $json.ragResults }}
# Constraints
- 利用可能なツールは [\"internal_db_query\", \"web_search\", \"final_answer\"] のみです。
- 機密区分「社外秘」のナレッジは最終回答に含めてはいけません。
- 実行コストは最大$0.05まで、処理時間は60秒以内に収めてください。
- 最終回答を生成する前には、必ず根拠となる情報が揃っている必要があります。
# Instructions
上記の情報を基に、以下のJSONスキーマに従った行動計画を生成してください。
{
\"thought\": \"ユーザーは製品Xの価格について質問している。まず社内DBで価格表を検索し、もし情報がなければWeb検索で公開情報を探し、最終的に回答を生成する、という計画を立てる。\",
\"plan\": [
{
\"step\": 1,
\"tool_name\": \"internal_db_query\",
\"tool_input\": \"SELECT price FROM products WHERE name = '製品X'\"
},
{
\"step\": 2,
\"tool_name\": \"final_answer\",
\"tool_input\": \"製品Xの価格情報を基に、ユーザーへの回答を作成する。\"
}
],
\"needs_human_review\": false,
\"estimated_cost\": 0.02
}5. ツール実装の具体例
- Web検索:
HTTP RequestノードでGoogle Custom Search APIやBing Search APIなどを呼び出します。APIのレート制限に抵触しないよう、短時間のキャッシュ機構(例:Redisに結果を数分間保存)を挟むと効果的です。 - 社内API:
HTTP Requestノードを使用し、認証情報はCredentialsから取得します。リトライ設定は、ノードのSettingsタブから「Retry on Fail」を有効にし、指数バックオフ(例:1秒、2秒、4秒)を設定します。 - DBクエリ:
Postgres,MySQLなどの専用ノードを使用します。必ず読み取り専用のDBユーザーを用意し、書き込み権限を与えないようにします。 - 計算・データ整形:
CodeノードでJavaScriptを実行します。LLMからのJSON出力をパースした後、後続の処理でエラーが発生しないよう、ajvなどのライブラリ(セルフホストでNPMインストールが必要)を使って厳密なスキーマ検証を行うことを強く推奨します。
6. 検証とポリシー適合
- PII検出:
Codeノード内で正規表現(電話番号、メールアドレスなど)とLLMによる補助的なチェックを組み合わせ、個人情報が含まれている可能性のあるテキストを検出します。検出された場合は、自動的にマスキング処理を行うか、人手承認キューに回します。 - 根拠の必須化: 最終回答を生成する前に、参照した
evidence(根拠情報)が空でないことをチェックするIFノードを設置します。空の場合は、再度RAG検索を試みるか、情報が見つからなかった旨をユーザーに伝えます。
7. 人手介入(Human-in-the-Loop)
- リスクの高いカテゴリ(例:契約、顧客への謝罪文など)や、エージェントが「低確信度」と判断した回答は、
IFノードで分岐させ、承認待ちキューに入れます。 SlackノードやMicrosoft Teamsノードを使い、承認者に対して「承認」「却下」「編集」のボタンが付いたメッセージを送信します。- 各ボタンには、承認結果をn8nに送り返すためのユニークなURLを持つ
Webhookトリガーを紐づけます。承認者がボタンをクリックすると、その結果に応じてワークフローが再開します。
8. ロギングと観測性
- 全てのワークフローの起点で生成した
correlation_idを、全てのノードのログ出力に含めるようにします。これにより、一連の処理の流れを容易に追跡できます。 Error Triggerノードを使い、ワークフローでエラーが発生した際に、そのエラー情報(エラーメッセージ、発生ノード、入力データ)を要約して管理者に通知するフローを構築します。- 実行ログに個人情報が含まれないよう、必要なマスキング処理を施した上で保存します。これは個人情報保護法遵守の観点からも重要です。
コンテキスト維持の実務:メモリの正攻法
AIエージェントが人間のように自然な対話を行うためには、「文脈(コンテキスト)」の維持が不可欠です。しかし、LLMのコンテキストウィンドウには限りがあり、単純に過去の全履歴を送り続けると、コストが増大し、重要な情報が埋もれてしまいます。実務で効果的なメモリ管理戦略は以下の通りです。
- セッションIDの一貫性: 全ての対話リクエストに、クライアント側で生成・維持される
session_idを付与します。n8n側では、このIDをキーにデータベースから過去の履歴をロードします。 - 履歴の「圧縮」:
- 短期記憶: 直近の3?5ターン程度の会話は、原文のまま保持します。これにより、直前の文脈に対する応答性が保たれます。
- 長期記憶(要約): それより古い会話は、定期的にLLMを使って要約し、「これまでの会話の要点」として圧縮します。これにより、トークン数を節約しつつ、対話の全体像を維持します。
- 外部知識の優先順位付け: LLMに情報を与える際には、明確な優先順位を設けます。一般的には、
会話履歴(短期記憶)→RAGによる社内文書(高信頼性の外部知識)→Web検索結果(最新の外部知識)の順に情報を整理し、プロンプト内でその役割を明記します。 - メモリの寿命管理: セッションデータは無期限に保持するのではなく、一定期間(例:7日間)で自動的に破棄するポリシーを設定します。コンプライアンス要件などで永続化が必要な場合でも、保存するのは個人情報を除いた要約データのみに限定します。
デバッグ・テスト:JSON地獄から抜け出す手順
AIエージェント開発における最大の障害の一つが、デバッグの困難さです。特に、LLMの出力(思考プロセスや計画)が不安定で、後続の処理が次々と失敗する「JSON地獄」は多くの開発者を悩ませます。この地獄から抜け出すための体系的なアプローチは以下の通りです。
- 小さく始め、段階的に検証する:
- 最初から全ての機能を繋ぎ込むのではなく、各コンポーネントを個別にテストします。
プランナー単体→単一ツールの実行→複数ツールの連携→RAGの統合→ポリシー検証のように、少しずつ機能を拡張し、各段階で挙動を確認します。
- 強制JSONとスキーマ検証を徹底する:
- LLMには必ずJSONモード(対応モデルの場合)で出力させます。
Codeノードで、受け取ったJSONが事前に定義したスキーマに準拠しているかを厳密に検証します。検証に失敗した場合は、エラーを返すか、LLMに「フォーマットが不正です。修正してください」というフィードバックを与えて自己修正を促します。
- 固定テストデータセットを作成する:
- 想定される代表的な問い合わせパターンを20?50件程度リストアップし、これを「評価セット」として固定します。
- ワークフローを修正するたびにこの評価セットを実行し、成功率、回答の品質、コスト、レイテンシといった主要KPIが劣化していないか(リグレッション)を定点観測します。
- トレースの見える化:
- ワークフローの最後に、その実行における重要な中間生成物(RAGでヒットした文書のタイトル、プランナーが生成したJSON、各ツールの実行結果の要約など)を一つのJSONオブジェクトにまとめる「監査ログ」生成ノードを設けます。
- これにより、n8nの実行履歴画面で最終的なアウトプットを見るだけで、エージェントが「何を考えて」「どのように行動したか」が一目瞭然になります。
- 失敗を意図的に注入する:
- Mockサーバーなどを用意し、ツールが呼び出す外部APIが意図的にレート制限エラー(429 Too Many Requests)やサーバーエラー(5xx)を返す状況をシミュレートします。
- これにより、設定したリトライ処理やフォールバック(代替手段への切り替え)ロジックが正しく機能するかを本番環境投入前に検証できます。
スケーリングとコスト最適化:Queueモードと賢い節約術
プロトタイプが完成し、いざ本番展開という段階で直面するのが、スケーラビリティとコストの問題です。
- Queueモードによる水平スケール:
- 前述の通り、本番環境ではQueueモードが必須です。Redisをメッセージブローカーとして介在させることで、Webhookリクエストの受け付けと実際の重い処理を非同期化します。
- アクセスが集中した際も、リクエストは一旦キューに積まれ、Workerプロセスが自身の処理能力に応じて順次処理していくため、システム全体がダウンするのを防ぎます。負荷に応じてWorkerの数を増減させることで、柔軟な水平スケーリングが可能です。
- 同時実行数とRPS(Requests Per Second)制御:
- 外部APIのレート制限を超えないよう、n8nのWorkerの同時実行数を慎重に設定します。
- さらに、特定のAPIを呼び出すサブワークフローに、
Codeノードを使って簡易的なトークンバケットアルゴリズム(一定時間内に実行できる回数を制限する仕組み)を実装することで、瞬間的なアクセス集中を平滑化できます。
- 積極的なキャッシュ戦略:
- RAGで取得した文書や、Web検索の結果など、頻繁に参照されるが更新頻度が低いデータは、Redisなどのインメモリキャッシュに短時間(例:5分?1時間)保存します。
- これにより、高価なベクトル検索や外部APIコールの回数を削減し、応答速度の向上とコスト削減を両立できます。
- モデルの階層的利用:
- 全ての処理を最高性能のモデルで行うのは非効率です。タスクの難易度に応じてモデルを使い分けます。
- 例:内部的な思考や計画立案(プランニング)は高速・低コストなモデル(例:GPT-3.5-turbo, Claude 3 Haiku)で行い、ユーザーに提示する最終的な文章の生成のみ、高品質なモデル(例:GPT-4, Claude 3 Opus)を使用します。
- 実行ごとのトークン予算管理:
- 無限ループや予期せぬ長文生成によるコストの青天井化を防ぐため、1回の実行あたりのトークン消費量やコストに上限(予算)を設けます。
Codeノードでトークン消費量を概算し、予算を超えそうになった場合は処理を途中で打ち切り、その時点での要約を返すなどのフォールバック処理を行います。
FAQ(よくある質問)
Q1. n8nで本当に安定したAIエージェントを稼働させられますか?
A. はい、可能です。成功の鍵は「自由度を段階的に開放する」アプローチにあります。最初から完璧な自律エージェントを目指すのではなく、まずRAGを組み込んだ信頼性の高い「AIワークフロー」として構築します。その上で、プランナー(オーケストレーター)を導入し、徐々に自律性を高めていきます。キューモード、堅牢なロギング、スキーマ検証といった運用基盤を先に整備することで、安定稼働と将来のスケールが見通せます。
Q2. 会話履歴などのメモリはどこに保存するのがベストですか?
A. ユースケースによりますが、一般的な構成としては、揮発性の高いセッション履歴はPostgreSQLなどのリレーショナルデータベースに保存するのが管理しやすく十分です。RAGの知識源となるベクトルデータは、専用のベクターストアまたはpgvectorのようなDB拡張機能に格納します。ワークフロー内では、DBから直近K件の履歴と要約スナップショットを読み込んで利用する構成が、パフォーマンスとコストのバランスに優れています。
Q3. どのLLMモデルを選ぶべきですか?
A. 一概に「これがベスト」というモデルはありません。思考や計画立案など、内部処理にはコスト効率の良いモデルを、ユーザー向けの最終的な文章生成には品質重視のモデルを、というように階層的に使い分けるのが基本戦略です。特に日本語の厳密性が求められる法務・金融などの領域では、高品質モデルの利用を推奨しますが、その場合でもプロンプトで出力スタイルや根拠提示のルールを厳密に指定することが重要です。
Q4. n8nでPythonのコードは使えますか?
A. n8nの標準的なコード実行環境はJavaScript(Node.js)ですが、Pythonの利用も可能です。コミュニティで開発されているPython実行ノードを利用したり、Execute CommandノードでローカルのPythonスクリプトを呼び出したりする方法があります。データ分析ライブラリ(Pandas, NumPy)や特定の機械学習モデルの前処理など、Pythonエコシステムを活用したい場合に有効です。
Q5. デバッグの一番のコツは何ですか?
A. 「LLMの出力を信用しない」という前提に立ち、厳密な検証を行う仕組みを組み込むことです。具体的には、強制JSONモード + スキーマ検証、監査ログの一元化、固定テストデータセットによる定点観測、そして相関IDによる処理の追跡の4点セットが極めて効果的です。また、意図的にエラーを発生させるテストを行うことで、システムの回復力を高めることができます。
おわりに:理想と現実をつなぐのは「設計の地力」
AIエージェントという言葉が持つ未来的な響きは、私たち技術者を魅了します。しかし、その理想を現実のビジネス価値に変える道のりには、「コンテキストが維持できない」「デバッグが困難すぎる」「スケールしない」「コストが予測できない」といった、非常に泥臭い壁がいくつも立ちはだかります。
n8nは、そのセルフホストの自由度とコードによる拡張性によって、これらの壁を乗り越えるための強力な土台を提供してくれます。しかし、ツールはあくまで土台です。その上に堅牢な城を築けるかどうかは、私たちの「設計の地力」にかかっています。
結論として、成功への道筋は以下の3つの原則に集約されます。
- 役割の分離を徹底する: 思考役の「オーケストレーター」と実行役の「ツール」を厳密に分離し、知識源としての「RAG」と安全装置としての「人手介入」をアーキテクチャに標準で組み込むこと。
- 運用の基盤を最初に固める:
JSON契約とスキーマ検証、相関ID付きの監査ログ、Queueモードによるスケーラビリティという、本番運用に不可欠な要素を開発の初期段階から導入すること。 - アジャイルに進化させる: 最初から完璧を目指さず、まずは価値実証が容易なAIワークフローから始め、KPIを観測しながら段階的にエージェントへと進化させていく。品質、コスト、信頼性を継続的に改善するプロセスを確立すること。
この記事が、あなたの現場に最適化された、真に価値を生み出すオーケストレーターAIエージェントをn8nで構築するための一助となれば幸いです。さあ、まずは身近な業務の自動化から、その第一歩を踏み出してみましょう。

