- 1 n8nで作るRAG実装ガイド:Postgres PGVector Storeで実現する実運用レベルの社内AI
- 2 はじめに:その社内文書、AIで「使える資産」に変えませんか?
- 3 基礎理解:なぜ「n8n × pgvector」でRAGを構築するのか?
- 4 アーキテクチャ全体像:2つのワークフローで実現するRAG
- 5 Step 1: 前提条件と環境準備
- 6 Step 2: PostgreSQL/pgvectorのスキーマ設計(実運用向け)
- 7 Step 3: n8nで構築する「取り込み(ETL)」ワークフロー
- 8 Step 4: n8nで構築する「問い合わせ」ワークフロー
- 9 実運用で差がつくポイントとベストプラクティス
- 10 FAQ(よくある質問)
- 11 まとめ:RAGは「作る」から「育てていく」時代へ
n8nで作るRAG実装ガイド:Postgres PGVector Storeで実現する実運用レベルの社内AI
はじめに:その社内文書、AIで「使える資産」に変えませんか?
「社内の膨大なドキュメントから、必要な情報を根拠付きで即座に引き出せるAIが欲しい」
「でも、開発には専門知識と時間、そして高額なコストがかかるのでは?」
多くの開発チームやDX推進担当者が、このような課題と期待の間で揺れ動いています。生成AIの可能性は感じつつも、その実装、特に社内データという機密情報を扱うとなると、ハードルは一気に上がります。
本記事では、その課題に対する一つの答えとして、ノーコード・ローコード自動化ツールn8nと、広く使われているデータベースPostgreSQLのベクトル検索拡張pgvectorを組み合わせた、最新のRAG(Retrieval-Augmented Generation)システム構築の全手順を、ステップ・バイ・ステップで徹底解説します。
この記事を最後まで読めば、あなたは以下の技術を組み合わせ、実運用に耐えうるRAGパイプラインを構築するための知識と具体的な手順を完全に理解できます。
※ n8n 1.110.1 以降(2025年8月頃のリリース)にて対応しています。
- Postgres PGVector Store ノード: 使い慣れたPostgreSQLを高性能なベクトルデータベースとして活用します。
- Enhanced Default Data Loader ノード: Google Drive、Slack、Webサイトなど、多様なデータソースから情報を自動で取り込みます。
- Embeddings OpenAI ノード: 世界最高水準のOpenAIモデルで、テキストを効率的にベクトル化(埋め込み)します。
- Recursive Character Text Splitter ノード: RAGの精度を左右する「チャンク分割」を、日本語の特性に合わせて最適化します。
この記事が目指すゴールは、単なる技術紹介ではありません。 PoC(概念実証)なら半日、本格的な導入でも1~2週間で立ち上げ可能な、実践的かつ具体的な設計図を提供することです。Google Driveやファイルサーバーに眠るドキュメントが、社員の質問に根拠を添えて回答する強力なアシスタントへと生まれ変わる。その実現への最短ルートを、この記事で示します。
この記事で得られること(先に結論)
- 最小構成の理解:
Data Loader→Splitter→Embeddings→PGVector StoreというシンプルなETLパイプラインと、問い合わせAPIの基本形を理解できます。 - 日本語特化のノウハウ: 日本語文書のRAGで最も重要な「チャンク分割」の最適設定(
chunk_size800~1,200文字、overlap120~200文字)とその理由がわかります。 - コストと性能の最適解: OpenAIの埋め込みモデル
text-embedding-3-smallを標準とし、pgvectorのインデックスはHNSWを推奨するなど、現実的な選択基準を学べます。 - 実運用の勘所: 重複排除、データ更新の冪等性(べきとうせい)、バージョニングといった、PoCで終わらないための必須設計を習得できます。
- セキュリティの要点: n8nの資格情報管理、データベースのアクセス制御、PII(個人を特定できる情報)対策など、安全な運用に不可欠な3つのポイントを押さえられます。
さあ、n8nとPostgreSQLで、あなたの組織だけのインテリジェントな知識ベースを構築する旅を始めましょう。
基礎理解:なぜ「n8n × pgvector」でRAGを構築するのか?
本題に入る前に、なぜこの技術スタックが現在のRAG構築において強力な選択肢となるのか、その理由を整理しておきましょう。
RAG(Retrieval-Augmented Generation)とは?
RAGは、生成AI(LLM)が持つ一般的な知識に、外部の専門的な知識ベースを組み合わせて回答を生成する技術です。LLMが時々もっともらしい嘘をつく「ハルシネーション」を抑制し、回答に「根拠」を持たせることができます。
RAGの仕組み(簡易版)
- 検索(Retrieval): ユーザーの質問をベクトル化し、事前にベクトル化して保存しておいた社内ドキュメント群から、関連性の高い部分(チャンク)を検索します。
- 補強(Augmented): 見つけ出した関連チャンクを、元の質問と一緒にLLMへのプロンプト(指示文)に含めます。
- 生成(Generation): LLMは、提供されたコンテキスト(関連チャンク)を最優先の根拠として、質問に対する回答を生成します。
ファインチューニング(LLMの再学習)に比べて、RAGは「情報の更新が容易」「コストが低い」「どの情報源を基に回答したか追跡可能」という点で、特に企業内ナレッジベースとの相性が抜群です。
n8nを選択する強み
n8nは、GUI(グラフィカル・ユーザー・インターフェース)上でノードを繋ぎ合わせることで、複雑なワークフローを構築できるツールです。RAG構築において、n8nは以下のような強力なメリットを提供します。
- 高速なプロトタイピング: API連携、データ変換、DB操作といった処理をコーディングなしで実現できるため、試行錯誤のサイクルを劇的に短縮できます。
- 可視性とメンテナンス性: ワークフロー全体が視覚的に表現されるため、データの流れが直感的に理解でき、専門の開発者でなくてもメンテナンスが可能です。
- 豊富な連携先: データベース、クラウドストレージ、SaaSアプリケーションなど、数百ものサービスと標準で連携できます。これにより、様々な場所にある社内ドキュメントを簡単に集約できます。
- スケーラビリティ: 自己ホスト(セルフホスト)版では、Queueモードと複数のWorkerを組み合わせることで、大量のデータ処理にも対応可能なスケーラブルな構成を組むことができます。
pgvectorを選択する強み
pgvectorは、世界で最も普及しているオープンソースデータベースの一つであるPostgreSQLに、ベクトル類似度検索機能を追加する拡張機能です。
- 運用の一元化: 構造化データ(ユーザー情報など)と非構造化データ(ドキュメントのベクトル)を同じPostgreSQLデータベース内で管理できます。これにより、インフラがシンプルになり、バックアップや権限管理、監視といった既存の運用ノウハウをそのまま活かせます。
- 成熟したエコシステム: PostgreSQLが長年培ってきたトランザクション、堅牢なデータ保護、豊富な管理ツールといった恩恵をすべて受けることができます。
- コスト効率: ベクトル検索専用のデータベースを別途契約・運用する必要がなく、既存のPostgreSQL環境を拡張するだけで済むため、多くの場合コストを抑えられます。
n8nの柔軟な連携能力と、pgvectorの堅牢な運用基盤を組み合わせることで、迅速に構築でき、かつ長期的に安定運用できるRAGシステムが実現するのです。
アーキテクチャ全体像:2つのワークフローで実現するRAG
私たちが構築するRAGシステムは、大きく分けて2つの独立したn8nワークフローで構成されます。
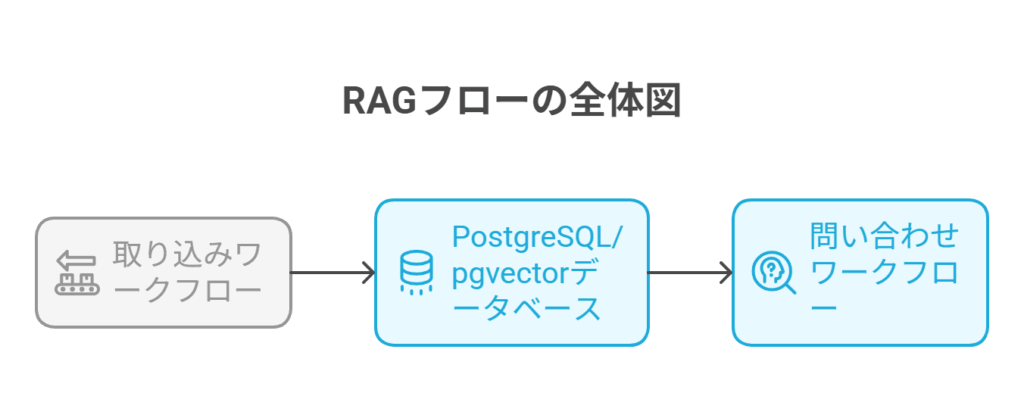
1. 取り込みワークフロー(ETL:Extract, Transform, Load)
このワークフローは、定期的に実行され、社内ドキュメントを検索可能な状態にしてデータベースに格納する役割を担います。
- データローダー (Enhanced Default Data Loader): Google DriveやSlack、S3、Webサイトなどからドキュメント(PDF, DOCX, etc.)を取得します。
- チャンク分割 (Recursive Character Text Splitter): 長いドキュメントを、LLMが扱いやすい適切な長さの塊(チャンク)に分割します。
- ベクトル化 (Embeddings OpenAI): 各チャンクを、意味的な特徴を捉えた数値の配列(ベクトル)に変換します。
- 格納 (Postgres PGVector Store): 生成されたベクトルを、元のテキストや出典情報などのメタデータと共にPostgreSQLのテーブルに書き込みます(Upsert)。
2. 問い合わせワークフロー(検索と生成)
このワークフローは、ユーザーからの質問をトリガーに実行され、リアルタイムで回答を生成するAPIとして機能します。
- トリガー (Webhook/HTTP Trigger): ユーザーがチャットUIやアプリケーションから送信した質問を受け付けます。
- クエリベクトル化 (Embeddings OpenAI): 受け取った質問文を、ドキュメントと同じモデルでベクトルに変換します。
- 類似検索 (Postgres PGVector Store): 質問ベクトルと最も類似度の高いドキュメントチャンクを、データベースから複数件(top-k)検索します。
- 回答生成 (LLM Node): 質問文と、検索で見つかったチャンク(根拠)を組み合わせたプロンプトを作成し、LLMに回答を生成させます。
- レスポンス: 生成された回答と、根拠となったドキュメントの出典情報をユーザーに返します。
この2つのワークフローを構築することが、本記事の具体的なゴールとなります。
Step 1: 前提条件と環境準備
実装を始める前に、必要なツールと環境を整えましょう。
必要な要素
- n8nインスタンス: セルフホスト、またはn8n Cloud。セルフホストの場合、後述の環境変数を設定してください。
- PostgreSQLサーバー: バージョン11以上を推奨。pgvector拡張がインストール可能、または既に有効化されている環境が必要です。クラウドDB(AWS RDS, Google Cloud SQLなど)でも構いません。
- OpenAI APIキー: Embeddingsモデルを利用するために必要です。OpenAIのプラットフォームで取得し、課金設定を有効にしておきましょう。
- 取り込み元データソースへの認証情報: Google Driveからデータを取得する場合はGoogleの認証情報、Slackの場合はSlackの認証情報が必要です。これらは後ほどn8nのCredentials機能で安全に設定します。
n8nの環境変数(セルフホストの場合)
Docker Composeなどでn8nをセルフホストしている場合、以下の環境変数が重要になります。特にN8N_ENCRYPTION_KEYは、Credentials情報を暗号化するための非常に重要なキーなので、必ずユニークで強固な文字列を設定してください。
# .env ファイルの例
N8N_ENCRYPTION_KEY='your-very-secret-and-long-encryption-key'
N8N_HOST='your-n8n-domain.com'
N8N_PORT=5678
N8N_PROTOCOL='https'
N8N_EDITOR_BASE_URL='https://your-n8n-domain.com/'
N8N_PUBLIC_URL='https://your-n8n-domain.com/'データベース接続情報
PostgreSQLサーバーの接続情報を手元に準備しておきます。
- ホスト名(またはIPアドレス)
- ポート番号(通常は5432)
- データベース名
- ユーザー名
- パスワード
- SSL/TLS接続の要否
準備が整ったら、次はいよいよデータベースの設計に進みます。
Step 2: PostgreSQL/pgvectorのスキーマ設計(実運用向け)
堅牢なRAGシステムの土台となる、データベースのテーブル設計を行います。ここでは、実運用で求められる拡張性やメンテナンス性を見据えたスキーマを定義します。
1. 拡張機能の有効化とスキーマの作成
まず、データベースに接続し、vector拡張を有効化します。関連するテーブルをまとめるために、専用のスキーマ(ここではrag)を作成することをお勧めします。
-- vector拡張が存在しない場合にのみ作成
CREATE EXTENSION IF NOT EXISTS vector;
-- RAG関連のオブジェクトを格納するスキーマを作成
CREATE SCHEMA IF NOT EXISTS rag;2. テーブル設計:メタデータと冪等性が鍵
⚠️ 最新版での注意点
- 最新版では、初回実行時に
ai_vectorsテーブルとコレクション用インデックスが自動生成されるようで、そちらを使用する方法もあります。最新版のドキュメントをご確認ください。
この場合、モデル変更時はコレクションを新規作成するか、既存テーブルを削除してください。
なお、当社でも確認が取れ次第、記事を改定する予定です。
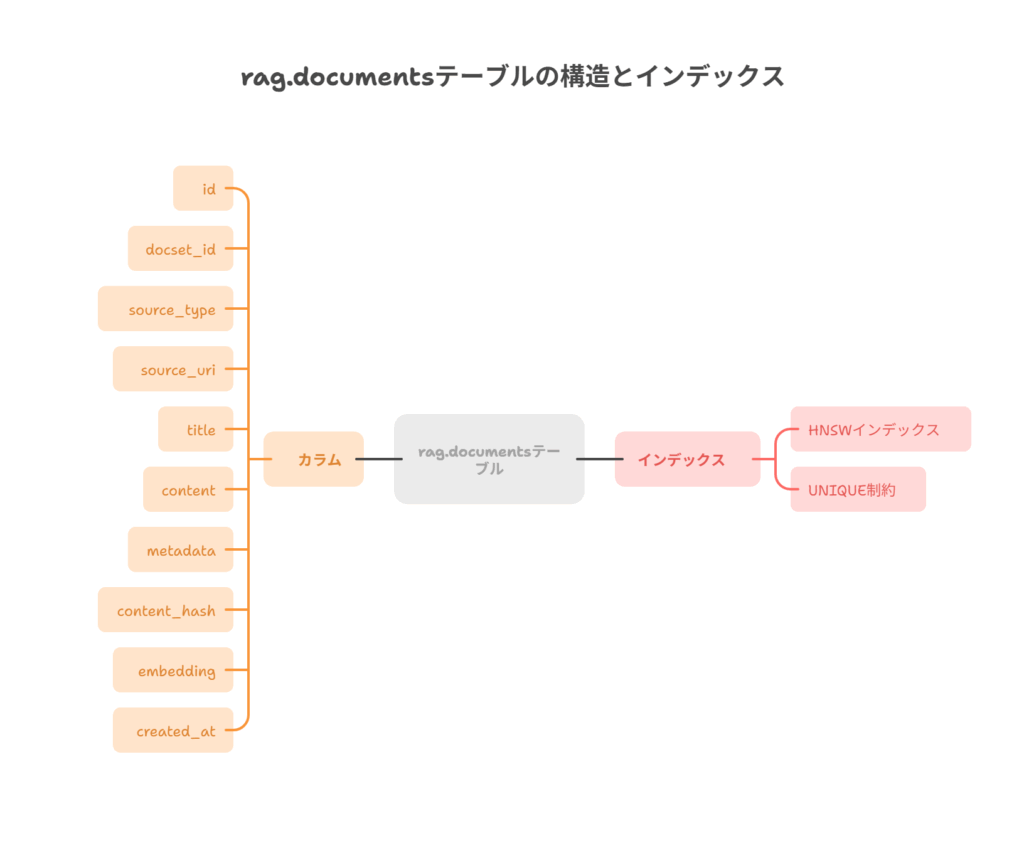
次に、ドキュメントチャンクを格納するメインテーブルrag.documentsを作成します。
設計のポイント:
- 次元数の指定:
vector列の次元数は、使用するOpenAIの埋め込みモデルと厳密に一致させる必要があります。text-embedding-3-small:vector(1536)text-embedding-3-large:vector(3072)
- ドキュメントセットの分離:
docset_id列を設けることで、「社内規定」「技術ブログ」「議事録」など、異なるドキュメント群を一つのテーブルで管理でき、検索対象を絞り込めます。 - 冪等性の確保:
content_hash列(チャンク内容のハッシュ値)とUNIQUE制約により、同じ内容のチャンクが重複して登録されるのを防ぎ、データ取り込み処理を何度実行しても結果が同じになる「冪等性」を担保します。
以下はtext-embedding-3-smallを想定したテーブル定義SQLです。
CREATE TABLE IF NOT EXISTS rag.documents (
id bigserial PRIMARY KEY,
docset_id text NOT NULL, -- ドキュメントセットの識別子 (例: \"handbook\", \"faq\")
source_type text NOT NULL, -- データソースの種類 (例: \"gdrive\", \"slack\", \"web\")
source_uri text NOT NULL, -- 元ファイルのIDやURL
title text, -- 元ドキュメントのタイトル
content text NOT NULL, -- 分割されたチャンクのテキスト本体
metadata jsonb DEFAULT '{}'::jsonb, -- ページ番号やセクション等の追加情報
content_hash text NOT NULL, -- contentのMD5ハッシュ (重複排除用)
embedding vector(1536) NOT NULL, -- テキストのベクトル表現 (smallモデルの場合)
created_at timestamptz DEFAULT now(),
updated_at timestamptz DEFAULT now(),
version int DEFAULT 1, -- ドキュメントのバージョン管理用
-- この組み合わせでチャンクが一意に定まるようにする
UNIQUE (docset_id, source_uri, content_hash)
);3. インデックス作成:検索速度の心臓部
ベクトル検索のパフォーマンスはインデックスによって決まります。pgvectorでは主にHNSWとIVFFLATという2種類のインデックスが利用できます。
- HNSW (Hierarchical Navigable Small World): 高い検索精度と安定したパフォーマンスを提供します。新規に構築するなら、こちらを第一候補としてください。(pgvector 0.5.0以降で利用可能)
- IVFFLAT: HNSWが利用できない環境での代替案。HNSWに比べると精度と速度のバランス調整が必要になります。
ここではHNSWインデックスをcosine類似度で作成します。OpenAIの埋め込みベクトルはcosine類似度で評価するのが一般的です。
-- HNSWインデックスを作成 (cosine類似度での検索を高速化)
CREATE INDEX IF NOT EXISTS documents_embedding_hnsw
ON rag.documents
USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 200);注意: IVFFLATインデックスを作成する場合は、事前にANALYZE rag.documents;を実行してテーブルの統計情報を更新しておくと、インデックスの品質が向上します。
これで、データを受け入れる準備が整いました。次はn8nでデータを取り込むワークフローを構築します。
Step 3: n8nで構築する「取り込み(ETL)」ワークフロー
ここからはn8nのキャンバス上で、ドキュメントを自動で取り込み、ベクトル化してDBに格納するパイプラインを組んでいきます。
推奨ノード構成:Trigger (手動 or Cron) → Enhanced Default Data Loader → Code (正規化&ハッシュ) → Recursive Character Text Splitter → Embeddings OpenAI → Postgres PGVector Store
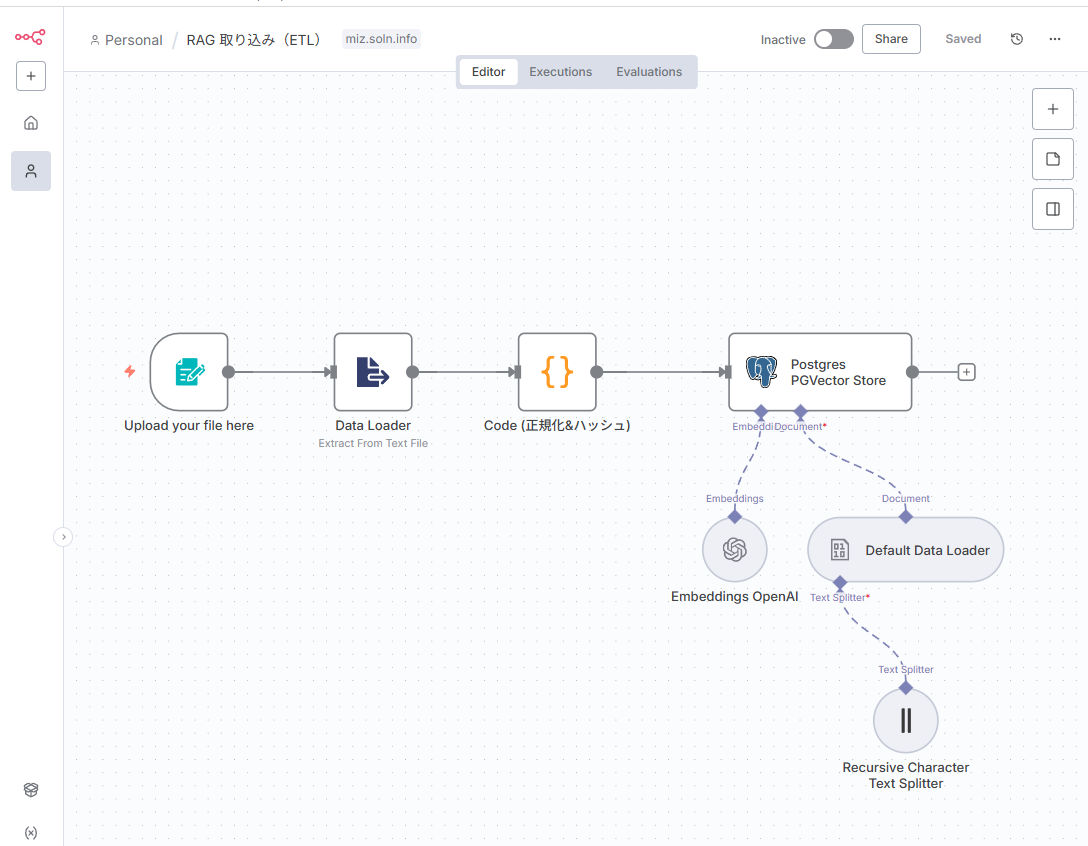
1. Enhanced Default Data Loader:多様なソースからデータを集める
ワークフローの入り口です。このノード一つで、様々な場所からドキュメントを読み込めます。
- Source:
Google DriveSlackS3Website/URLなど、データソースを選択します。 - Authentication:
Credentialsを設定します。n8nの指示に従い、各サービスのアカウントを連携させます。この認証情報はN8N_ENCRYPTION_KEYによって暗号化され、安全に保管されます。 - Options:
- Google Drive:
Folder IDを指定し、特定のフォルダ配下を対象にします。File Name Filterで拡張子(例:pdf,docx,md)を絞り込むと効率的です。 - Mode:
Read file contentを選択し、ファイルの中身をテキストとして読み込みます。
- Google Drive:
- ベストプラクティス:
- 巨大すぎるファイル(例: 10MB以上)は、タイムアウトやメモリ不足の原因になるため、
Filterで除外するか、別のバッチ処理で扱うことを検討します。 - 出力される
metadataには、後でどのファイルから来たチャンクか追跡できるように、source_uri(ファイルIDやURL)、titleなどが含まれていることを確認します。ここに、手動でdocset_idなどの固定情報を追加することも有効です。
- 巨大すぎるファイル(例: 10MB以上)は、タイムアウトやメモリ不足の原因になるため、
2. Code ノード(オプション):テキスト正規化とハッシュ計算
この一手間が、データの品質と運用安定性を大きく向上させます。
- 目的: チャンク分割の前にテキストを整え、重複排除のための
content_hashを計算します。 - コード例 (JavaScript):
// Codeノードに記述するコード
const items = $input.all();
const crypto = require('crypto');
for (const item of items) {
// item.data.content にローダーが読み込んだテキストが入っている想定
if (item.data.content) {
// 1. テキストの正規化
// - 連続する空白や改行をまとめる
// - 全角スペースを半角に統一
const normalizedContent = item.data.content
.replace(/\\s+/g, ' ')
.replace(/ /g, ' ')
.trim();
// 2. 正規化後のコンテンツでハッシュを計算
const hash = crypto.createHash('md5').update(normalizedContent).digest('hex');
// 3. 後続のノードで使えるようにプロパティを追加
item.data.normalized_content = normalizedContent;
item.data.content_hash = hash;
}
}
return items;3. Recursive Character Text Splitter:日本語に最適化したチャンク分割
RAGの精度を最も左右すると言っても過言ではない、重要なプロセスです。
- Text To Split: 分割したいテキストのプロパティを指定します。Functionノードで正規化した場合は
{{ $json.normalized_content }}を指定します。 - Chunk Size: 1チャンクあたりの最大文字数。日本語の場合、まずは1000文字前後を基準にします。英語に比べてトークン数が多くなる傾向があるため、少し大きめから始めるのがセオリーです。
- Chunk Overlap: チャンク間で重複させる文字数。120?200文字程度が推奨されます。これにより、文の途中でチャンクが分断されても、前後の文脈が次のチャンクに引き継がれ、意味が失われにくくなります。
- Separators: テキストを分割する際の区切り文字の優先順位をリストで指定します。日本語では「改行」や「句点(。)」を優先するのが効果的です。
日本語向けの推奨セパレーター設定:
[
\"\
\
\",
\"。\
\",
\"。\",
\"\
\",
\"、\",
\" \",
\"\"
]この設定により、まず段落(二重改行)で分割を試み、次に句点、改行、読点…という順で、できるだけ文意が途切れないように分割しようとします。
4. Embeddings OpenAI:テキストをベクトルに変換
分割されたチャンクを、AIが理解できる数値の配列(ベクトル)に変換します。
- Authentication: OpenAIのAPIキーをCredentialsとして設定します。
- Model:
text-embedding-3-smallを選択します。コストパフォーマンスが非常に高く、ほとんどのユースケースで十分な精度を発揮します。より高い精度が求められる特定のドメインでのみlargeを検討します。 - Text: 埋め込み対象のテキストとして、Splitterノードが出力したチャンクテキスト(
{{ $json.pageContent }}など)を指定します。 - Options (Batching): n8nは自動でバッチ処理を行いますが、APIのレートリミットに頻繁に引っかかる場合は、
Batch Sizeを調整(例: 500)することもできます。
5. Postgres PGVector Store:データベースへの書き込み
最後のステップです。生成されたベクトルとメタデータをDBに格納します。
- Authentication: PostgreSQLの接続情報をCredentialsとして設定します。SSL接続を有効にすることを強く推奨します。
- Operation:
Upsertを選択します。これにより、データがなければINSERT、あればUPDATEが実行され、冪等性が保たれます。 - Schema:
rag - Table:
documents - Content Column: チャンクテキストの列名(
content)を指定します。 - Embedding Column: ベクトルを格納する列名(
embedding)を指定します。 - Columns to Upsert On: Upsertのキーとなる列を指定します。ここでは
docset_id, source_uri, content_hashを指定し、この3つの組み合わせが一致する場合に更新(または何もしない)ようにします。 - Metadata Mapping: n8nの入力データとテーブルのカラムをマッピングします。
docset_id:\"handbook\"のような固定値や、{{ $json.metadata.docset_id }}のように前のノードから引き継いだ値を指定します。source_uri:{{ $json.metadata.source }}content_hash:{{ $json.content_hash }}embedding:{{ $json.embedding }}
これで、取り込みワークフローは完成です。手動で実行してデータがDBに格納されることを確認し、問題なければCronトリガーを設定して定期的に自動実行するようにしましょう。
Step 4: n8nで構築する「問い合わせ」ワークフロー
ユーザーからの質問にリアルタイムで答えるためのAPIを構築します。
推奨ノード構成:Webhook → Embeddings OpenAI (Query) → Postgres PGVector Store (Search) → Chat Model (LLM) → Respond to Webhook
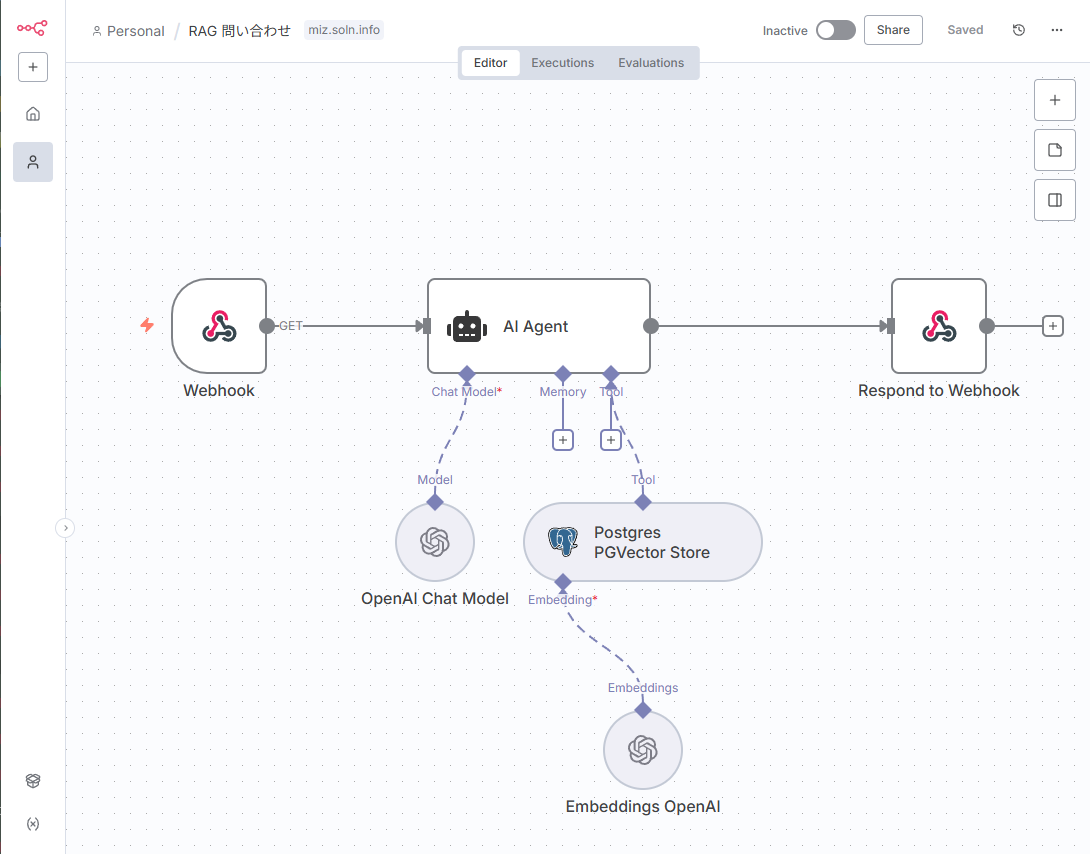
1. Webhook:質問の受け口
このノードは、ユニークなURLを生成し、HTTPリクエストを受け付けるトリガーとなります。
- HTTP Method:
POSTを選択するのが一般的です。 - Authentication:
Header Authなどを設定し、APIキーで認証をかけることで、不正なアクセスを防ぎます。 - Test URL: 開発中はテストURLを使い、本番運用に移行する際にプロダクションURLに切り替えます。
受け取るJSONボディの例:
{
\"query\": \"n8nのキューモードについて教えてください\",
\"docset_id\": \"handbook\",
\"top_k\": 5,
\"min_score\": 0.75
}2. Embeddings OpenAI:質問をベクトル化
取り込み時と同じモデルを使い、ユーザーからの質問文をベクトルに変換します。
- Model: 必ず取り込み時と同じモデル(例:
text-embedding-3-small)を選択します。 - Text: Webhookで受け取った質問文
{{ $json.body.query }}を指定します。
3. Postgres PGVector Store:類似チャンクの検索
質問ベクトルを使って、DBから関連性の高いドキュメントチャンクを検索します。
- Operation:
Similarity Searchを選択します。 - Schema / Table:
rag/documentsを指定します。 - Embedding Column:
embedding - Query Embedding: 前のEmbeddingsノードが出力したベクトル
{{ $node[\"Embeddings OpenAI\"].json.embedding }}を指定します。 - Limit (k): 取得するチャンク数。Webhookで受け取った
top_k({{ $json.body.top_k }})を指定します。デフォルトは5件程度が適切です。 - Filters: 特定のドキュメントセットのみを検索対象とするためにフィルターを設定します。
- Field:
docset_id - Operator:
Equal - Value:
{{ $json.body.docset_id }}
- Field:
このノードは、類似度スコア(score)と共に、一致したチャンクのcontentやmetadataを配列として出力します。
4. Chat Model / LLM ノード:根拠に基づく回答の生成
検索結果を元に、LLMに最終的な回答文を作成させます。ここではプロンプトエンジニアリングが非常に重要です。
- Model:
OpenAI Chat Modelなどを選択します。 - Prompt:
SystemメッセージとUserメッセージを組み合わせます。
プロンプトの基本テンプレート:
- System Message:
“`
あなたは、提供されたコンテキスト情報のみを厳密な根拠として、ユーザーの質問に日本語で回答する誠実なアシスタントです。- コンテキストに記載されていない情報は、絶対に回答に含めないでください。
- 根拠となる情報がコンテキストに不足している場合や、自信がない場合は、推測で回答せず、「提供された情報からは回答できません」と明確に述べてください。
- 回答の最後には、必ず参考にした出典情報を以下の形式でリストアップしてください。
【出典】 - タイトル
“`
- User Message:
以下のコンテキスト情報を参考に、私の質問に回答してください。 # 質問 {{ $json.body.query }} # コンテキスト {{ $node[\"Postgres PGVector Store\"].json.map(doc => `- ${doc.content} (出典: ${doc.metadata.title || doc.metadata.source})`).join('\ ') }}
このプロンプトにより、LLMは提供されたチャンクの範囲内で回答を生成しようとし、ハルシネーションを大幅に抑制できます。
5. Respond to Webhook:整形したレスポンスを返す
最後に、生成された回答と出典情報をJSON形式などでクライアントに返します。
レスポンスJSONの例:
{
\"answer\": \"{{ $node['OpenAI Chat Model'].json.choices[0].message.content }}\",
\"citations\": \"{{ $node['Postgres PGVector Store'].json.map(doc => ({ title: doc.metadata.title, source: doc.metadata.source, score: doc.score })) }}\"
}これで、質問応答APIも完成です。Postmanなどのツールでテストし、期待通りの回答が返ってくることを確認しましょう。
実運用で差がつくポイントとベストプラクティス
基本的なワークフローは完成しましたが、ここからは実運用でシステムの品質、コスト、安定性を左右する重要なポイントを解説します。
日本語に効くチャンク設計の実務ポイント
前述の通り、チャンク分割はRAGの精度を左右します。以下の点を考慮して、あなたのドキュメントに合わせて調整してください。
[表:日本語向けの推奨チャンク設定と効果比較]| パラメータ | 推奨値 | 調整の方向性 |
|---|---|---|
| Chunk Size | 800~1,200文字 | 回答の文脈が不足する場合: 大きくする (1600へ) 無関係な情報が混ざる場合: 小さくする (800へ) |
| Chunk Overlap | 120~200文字 | チャンクサイズの10-15%を目安に設定。文の途切れによる意味の損失を防ぐ。 |
| Separators | `[\”\ | |
| \ | ||
| \”, \”。\ | ||
\”, \”。\”, …]| ドキュメントの構造(Markdownの見出しなど)に合わせて、###`などを追加するのも有効。 |
品質テストとして、代表的な質問を10~20個用意し、検索結果(どのチャンクがヒットしたか)を目視で確認する作業が非常に有効です。top_kやmin_scoreの閾値を調整し、最も適切なチャンクが上位に来るようにパラメータを最適化していきましょう。
コストとレイテンシの最適化
RAGシステムの運用コストと応答速度は、ユーザー体験に直結します。
[表:コストチューニングのレバー]| 対象 | 最適化手法 |
|---|---|
| 埋め込みコスト | – 差分更新: content_hashを活用し、変更があったドキュメントのみ再埋め込みする。– モデル選択: text-embedding-3-smallを標準とする。料金は$0.02 / 1M tokens (2024年時点)と非常に安価。 |
| 検索レイテンシ | – インデックス: 必ずHNSWまたはIVFFLATインデックスを使用する。– 絞り込み: docset_idで検索対象を絞る。– Limit: top_kを必要最小限(3~8件)に抑える。 |
| 生成レイテンシ | – プロンプト: コンテキストに含めるチャンク数を適切に保つ。 – モデル選択: GPT-3.5 Turboなど、速度と精度のバランスが良いモデルを選ぶ。 – ストリーミング応答: 可能であれば、LLMからの応答をストリーミングで返すことで、体感速度を向上させる。 |
セキュリティとガバナンス
社内情報を扱う以上、セキュリティは最優先事項です。
- n8n:
- Credentialsはn8nの暗号化機能に任せる。
N8N_ENCRYPTION_KEYは厳重に管理。 - WebhookにはAPIキー認証やIP制限をかけ、意図しないアクセスを防ぐ。
- ユーザーごとにロール(編集者/閲覧者)を分離する。
- Credentialsはn8nの暗号化機能に任せる。
- データベース:
- n8nからの接続には、必要最小限の権限(
ragスキーマへのINSERT,SELECT,UPDATEのみ)を持つ専用ユーザーを使用する。 - 必ずSSL/TLSで接続を暗号化する。
- 可能であれば、n8nサーバーのIPアドレスからのみ接続を許可する。
- n8nからの接続には、必要最小限の権限(
- データ:
- 個人情報(PII)などの機密情報がドキュメントに含まれる場合、取り込み前にマスキングや匿名化処理を行う専用のステップをワークフローに加えることを検討します。
落とし穴と対策(現場の「あるある」)
- 次元数不一致エラー: DBの
vector(1536)とtext-embedding-3-large(3072次元)のように、モデルとテーブル定義の次元数が違うとINSERT時にエラーになります。常に一致を確認してください。 - 重複データだらけになる:
content_hashとUNIQUE制約、そしてUpsert操作は、重複を防ぐための三種の神器です。必ず設定しましょう。 - 取り込みエラーの放置: ファイルが破損していたり、API制限に達したりして、一部の取り込みが失敗することは日常茶飯事です。n8nの
Error Triggerノードを使い、失敗時には必ずSlackやメールで通知が飛ぶように設定しましょう。 - 日本語PDFのテキスト抽出品質が低い: PDFによっては、テキスト抽出がうまくいかない(文字化け、不要な改行など)場合があります。これはRAGの精度に致命的な影響を与えます。
Enhanced Default Data Loaderで品質が低い場合は、専用のPDF処理ライブラリを呼び出すCodeノードを挟むなどの対策が必要です。
FAQ(よくある質問)
Q1. pgvectorのインデックスはHNSWとIVFFLAT、どちらが良いですか?
A. HNSWを強く推奨します。 一般的にIVFFLATよりも高い検索精度と安定したレイテンシを提供します。利用しているPostgreSQL環境がHNSWをサポートしているなら、迷わずHNSWを選びましょう。
Q2. OpenAI以外の埋め込みモデルやLLMは使えますか?
A. はい、使えます。n8nにはHugging FaceやCohere、各種オープンソースLLM(Ollama経由など)を呼び出すノードも存在します。ただし、埋め込みモデルを変更した場合は、必ずDBのベクトル次元数を合わせ、既存のデータもすべて新しいモデルで再埋め込みする必要があります。
Q3. 埋め込みモデルはsmallとlarge、どちらを使うべきですか?
A. まずはtext-embedding-3-small(1536次元)から始めてください。 非常にコスト効率が良く、ほとんどのタスクで十分な性能を発揮します。smallで精度に課題が残る場合にのみ、largeへのアップグレードを検討しましょう。
Q4. メタデータには何を入れるべきですか?
A. 最低限、docset_id, source_uri, titleは必須です。 これらは検索対象の絞り込みや出典表示に不可欠です。加えて、page_number(ページ番号)、section_title(章タイトル)、version(ドキュメント改訂版)など、後でフィルタリングや分析に使えそうな情報を入れておくと、システムの拡張性が高まります。
Q5. LLMが間違ったことを自信満々に答えてしまいます(ハルシネーション)。
A. 以下の対策を試してください。
1. プロンプトの強化: 「コンテキストにないことは『不明』と答える」という指示をより強く、明確にします。
2. スコア閾値の導入: 類似度検索の結果、スコアが一定値(例: 0.7)以下のチャンクはコンテキストに含めないようにします。
3. top_kの調整: 検索結果の件数を増やして(例: 3件→5件)、より多くの根拠をLLMに与えてみる、または逆に減らしてノイズを減らす、といった調整が有効な場合があります。
まとめ:RAGは「作る」から「育てていく」時代へ
本記事では、n8nとPostgreSQL/pgvectorを使い、実運用に耐えうる最新のRAGシステムを構築するための設計思想と具体的な手順を網羅的に解説しました。
- データ取り込みでは、
Enhanced Default Data Loaderで多様なソースに対応し、日本語の特性を考慮したRecursive Character Text Splitterでチャンク化。 - ベクトル化と格納では、コスト効率の良い
Embeddings OpenAIモデルと、運用性に優れたPostgres PGVector Storeを組み合わせ、冪等性を確保したパイプラインを構築しました。 - 問い合わせ応答では、
Webhookでリクエストを受け、同様のプロセスで検索し、ハルシネーションを抑制するプロンプトでLLMに回答を生成させました。
n8nという強力な自動化プラットフォームを活用することで、かつては専門チームが数ヶ月かけて構築していたようなRAGシステムが、驚くほど短期間で、かつメンテナンスしやすい形で実現できます。
重要なのは、一度作って終わりではないということです。RAGシステムは、新しいドキュメントを取り込み、ユーザーからのフィードバックを元にチャンク分割の方法やプロンプトを改善し、継続的に「育てていく」ことで、その価値を最大化できます。
次のステップへ
この記事を読み終えたあなたが次に取り組むべきアクションは明確です。
- 小さなドキュメントセットでPoCを構築する: まずは社内マニュアルなど、対象を絞って本記事の手順通りにワークフローを組んでみましょう。
- 評価セットでチューニングする: 代表的な質問と期待される回答のセットを作り、チャンクサイズやスコア閾値を調整して精度を評価します。
- 運用に乗せる: Cronによる定期同期、エラー監視、セキュリティ設定を固め、まずは社内の特定チーム向けにパイロット運用を開始しましょう。
このガイドが、あなたの組織に眠る知識という名の資産を解き放ち、業務効率を飛躍させる一助となることを願っています。n8nの柔軟性を武器に、データソースの追加やハイブリッド検索などの高度な機能拡張にもぜひ挑戦してください。技術的負債を最小限に抑えながら、反復的な改善で「本当に使われるRAG」を目指しましょう。

