

- 1 ChatGPTと社内データ連携で実現する業務自動化ガイド|API・RPA活用法から導入手順まで解説
- 2 第1章 基礎理解:なぜ“ChatGPT × 社内データ連携”が業務を変えるのか
- 3 第2章 導入ロードマップ:短期・中期・長期で“つなぐ力”を育てる
- 4 第3章 実践ガイド:失敗しない導入の進め方とチェックリスト
- 5 第4章 具体ユースケース集:今日から試せる自動化アイデア
- 6 第5章 比較・選定基準:自社に最適な導入方法はどれか?
- 7 第6章 よくある失敗と対策:品質・漏洩・著作権から組織を守る
- 8 第7章 高度化への道:RAG、権限、監査でスケールさせる
- 9 第8章 実践!導入・選定チェックリスト
- 10 第9章 コピペで使える!プロンプト実例集
- 11 第10章 現場導入のリアル:立ちはだかる障壁とその越え方
- 12 第11章 KPIとベンチマーク:成果を“見える化”し、価値を証明する
- 13 FAQ(よくある質問)
- 14 結論:ChatGPTは“部品”。業務プロセスに組み込んでこそ真価を発揮する
ChatGPTと社内データ連携で実現する業務自動化ガイド|API・RPA活用法から導入手順まで解説
「ChatGPTを業務で使ってはみたものの、いまいち成果に繋がらない…」
「RPAを導入したが、人間の判断が必要な部分で結局止まってしまう…」
もしあなたがこのような課題を感じているなら、その原因は「人がやるべき高度な判断」と「機械に任せるべき定型的な手順」が混ざってしまっていることにあるのかもしれません。
文章の作成や要約、問い合わせ対応、調査・分析といった「言語」と「判断」が関わるタスクは、ChatGPTのような生成AIが最も得意とする領域です。一方で、システムの操作やデータの転記、ファイルのダウンロードといった「定型」で「反復」的な作業は、RPA(Robotic Process Automation)が圧倒的な強みを発揮します。
この記事では、この2つの強力なツールをAPIで連携させ、さらに社内データという「独自の知識」を与えることで、業務プロセス全体をエンドツーエンドで自動化するための実践的な方法論を網羅的に解説します。
具体的には、短期で成果を出せる小さな導入から、社内文書をAIに学習させるRAG(Retrieval-Augmented Generation)技術を用いた全社展開まで、具体的な手順、KPI設定、そして避けては通れないセキュリティやガバナンスの考え方まで、一気通貫でお伝えします。
この記事を読み終える頃には、あなたのチームや会社で「明日から試せる自動化の第一歩」が明確になり、AIを単なるチャットツールではなく、業務に組み込まれた強力な“頭脳”として活用するための具体的な道筋が見えているはずです。
この記事のポイント(60秒で理解する)
- 得意領域の明確化: 文章生成や要約、問い合わせ対応、調査分析、アイデア創出など、「言語」と「判断」が絡むタスクでChatGPTは最大の効果を発揮します。
- 最適な役割分担: ChatGPTは「創造・判断・言語化」を担う頭脳、RPAは「定型・手順・反復」を担う手足として機能させるのが成功の鍵です。
- 成功へのロードマップ: ①業務棚卸し → ②KPI設定 → ③自社ナレッジの付与 → ④小規模なパイロット導入 → ⑤継続的な改善、というステップが最も確実です。
- 必須の安全対策: 誤情報は必ず人が検証。機密データはセキュリティが担保されたAPIや法人向けプラン(Team/Enterprise)で扱う。著作権侵害を防ぐため、コピー&ペーストの禁止とチェック体制を構築します。
- 段階的な導入計画:
- 短期: メール作成、議事録要約、社内FAQ対応など、個人やチーム単位で効果を実感。
- 中期: APIで社内DBやCRMと接続し、RPAと統合して前後工程を自動化。
- 長期: RAG技術で全社文書を連携させ、権限管理のもと「自社専用アシスタント」として全社展開。
- 設計の核心: 「人」「AI」「RPA」の最適な分担比率を見極めること。そして、入出力データをCSVやJSON形式で標準化し、誰でも再利用可能な仕組みを作ることがスケールの鍵となります。
第1章 基礎理解:なぜ“ChatGPT × 社内データ連携”が業務を変えるのか
ChatGPTを単体で利用するだけでも、個人の生産性は飛躍的に向上します。しかし、その真価は、APIを通じて社内の様々なシステムやデータと連携させたときにこそ発揮されます。ここでは、なぜこの連携が強力なのか、その背景にある各技術の役割と本質を解き明かします。
1-1. ChatGPTの強みとは?一言でいえば「思考の外部ブレイン」
ChatGPTの核心的な強みは、高度な言語処理能力と文脈理解に基づいた「判断」と「生成」を、驚異的なスピードで実行できる点にあります。これは、業務における「考える」「書く」「まとめる」といった知的作業を代行・支援してくれる「外部ブレイン」を手に入れるようなものです。
- メールや報告書の草案作成: ゼロから文章を考える時間を大幅に短縮。
- 長文資料の要約: 数十ページのレポートから要点を数分で抽出。
- 多言語翻訳: 自然なニュアンスを保ったまま、言語の壁を越える。
- データ分析と洞察: 膨大なテキストデータから傾向や示唆を抽出。
- アイデア創出: ブレインストーミングの壁打ち相手として、多様な視点を提供。
- コード生成・デバッグ支援: 簡単なプログラムや関数の作成を補助。
これらの作業は、従来は専門知識を持つ人間が時間をかけて行っていたものです。ChatGPTは、この時間を圧縮し、人間がより創造的で、より高度な意思決定に集中できる環境を生み出します。
1-2. 周辺技術との関係性:RPA、iPaaS、APIの役割分担
ChatGPTを業務に組み込む際、単体で完結することは稀です。多くの場合、RPA、iPaaS、APIといった技術と連携させることで、その価値が最大化されます。それぞれの位置づけを正しく理解しましょう。
| テクノロジー | 役割(一言でいうと) | 得意なこと |
|---|---|---|
| RPA | 手足(実行部隊) | 人間のPC操作(クリック、入力、ファイル操作)を忠実に再現する。定型的なデータ収集やシステムへの転記。 |
| iPaaS | 神経(連携ハブ) | クラウドサービス(SaaS)間のデータ連携を自動化。「Aが起きたらBを実行する」というワークフローを簡単に構築。 |
| API | 接続口(機能部品) | システムやサービスの特定の機能を外部から呼び出すための「窓口」。ChatGPTの頭脳を自社システムに組み込むための公式な手段。 |

この関係性を理解すると、ChatGPTは「頭脳」、RPAは「手足」、そしてAPIやiPaaSはそれらを繋ぐ「神経」と捉えることができます。手足だけでは考えられず、頭脳だけでは実行できません。これらが連携して初めて、一連の業務プロセスを自動化できるのです。
1-3. 連携の本質:ChatGPTを“完成品”から“頭脳の部品”へ
多くの企業が陥りがちなのが、ChatGPTを単独のチャットツールとして、個人利用の範囲に留めてしまうことです。これは部分最適であり、組織全体へのインパクトは限定的です。
連携の本質は、ChatGPTを「頭脳の部品」として捉え直し、既存の業務フローにAPI経由で組み込むことにあります。
例えば、顧客からの問い合わせ対応を考えてみましょう。
- 連携なし(部分最適): 担当者が問い合わせ内容をコピーし、ChatGPTに貼り付けて回答案を生成。それを手作業でCRMシステムに記録する。
- 連携あり(全体最適):
- 問い合わせがシステムに届くと自動でトリガーが作動。
- API経由で問い合わせ内容と関連する社内FAQデータをChatGPTに送信。
- ChatGPTがFAQを基にした回答案を生成。
- 生成された回答案が担当者のレビュー画面に表示される。
- 担当者が承認すると、回答が顧客に自動送信され、対応履歴もCRMに自動で記録される。
このように、APIで自社のデータベースやCRM、ナレッジ基盤と繋ぐことで、「情報収集 → 要約・判断 → アクション → 記録」という一連の流れを再設計し、自動化することが可能になります。
1-4. 安全な利用とガバナンスが大前提
強力なツールであるからこそ、リスク管理は不可欠です。導入を検討する前に、以下の3つの主要リスクとその対策を必ず理解し、社内ルールを整備してください。
- 誤情報(ハルシネーション)のリスク:
- 現象: 事実に基づかない、もっともらしい嘘の情報を生成してしまうこと。
- 対策:
- 人のレビューを必須化: AIの生成物はあくまで「下書き」と位置づけ、最終的なファクトチェックと承認は人間が行う。
- RAG技術の活用: 社内の正確な文書データを参照させることで、回答の根拠を内部情報に限定し、リスクを低減する(詳細は第7章)。
- 信頼度スコアの表示: 回答に「信頼度:高/中/低」や「要確認」といったフラグを付与する仕組みを設ける。
- 情報漏洩のリスク:
- 現象: 機密情報や個人情報をプロンプトに入力してしまい、それがモデルの学習データに使われたり、外部に漏洩したりする。
- 対策:
- 安全なプランの利用: 無料版ではなく、入力データが学習に使われないことが規約で保証されている法人向けプラン(ChatGPT Team/Enterprise)やAPIを利用する。
- データ匿名化/マスキング: 個人名や顧客情報などをシステム側で自動的に匿名化・マスキングしてからAPIに渡す処理を挟む。
- 社内ルールの徹底: 何を入力してはいけないかを明確にしたガイドラインを作成し、全社員に周知する。
- 監査ログの整備: 誰が、いつ、どのような目的で利用したかを追跡できるログを取得・監視する。
- 著作権侵害のリスク:
- 現象: Web上のコンテンツを学習しているため、意図せず他者の著作物をコピー&ペーストに近い形で生成してしまう可能性がある。
- 対策:
- コピー&ペーストの禁止: 生成された文章をそのまま公開・納品することを禁止し、必ず人の手で編集・加筆・リライトする運用を徹底する。
- 引用ルールの遵守: 外部の情報を引用する場合は、出典を明記するルールを定める。
- 重複チェックツールの活用: 必要に応じて、生成物が既存のコンテンツと酷似していないかを確認するツールを導入する。
これらの対策は、技術的な仕組みと組織的なルールの両輪で進めることが重要です。
第2章 導入ロードマップ:短期・中期・長期で“つなぐ力”を育てる
ChatGPT連携による業務自動化は、一足飛びに実現するものではありません。組織の成熟度や目的に合わせて、段階的に導入を進めるのが成功への近道です。ここでは、多くの企業が辿る現実的な3つのステップからなるロードマップを提示します。
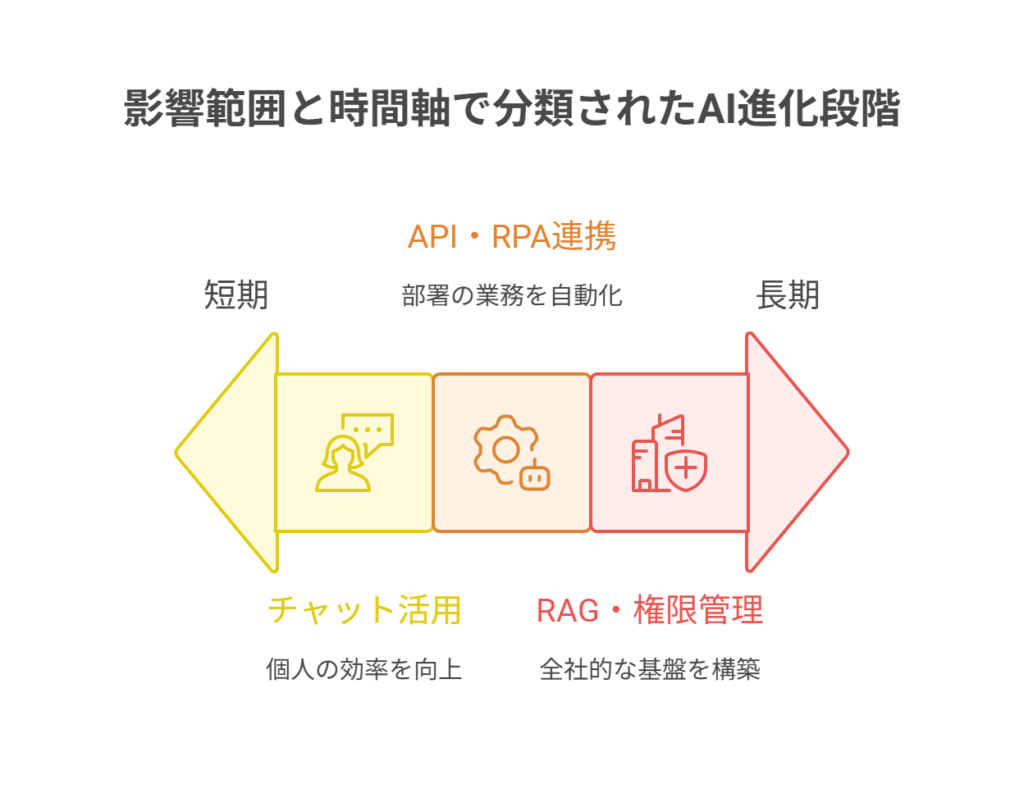
2-1. 短期(0〜3ヶ月):現場で即効性を実感するユースケース
このフェーズの目標は、「AI活用の成功体験を積み、効果を実感すること」です。大掛かりなシステム開発は不要で、個人やチーム単位ですぐに始められるものに焦点を当てます。
- メール・議事録・報告書の草案作成と要約:
- 方法: ChatGPTのWeb画面や法人向けプランを使い、定型的なプロンプト(指示文)テンプレートをチームで共有する。
- 効果: 文章作成にかかる時間を50%以上削減できるケースも多い。
- 翻訳と文体変換:
- 方法: 「この文章を丁寧なビジネスメールの文体に変換してください」「要点を3つにまとめてください」といった指示で、文章のトーン&マナーを統一する。
- Excel関数や正規表現の作成支援:
- 方法: 「A列とB列の値を結合し、C列に出力するExcel関数を教えて」のように、具体的な作業を日本語で指示する。
- 最小限の社内FAQボット:
- 方法: 既存のFAQドキュメントをテキストファイルにまとめ、ChatGPTに「この内容に基づいて回答してください」と指示する。
この段階では、主にChatGPTのWebインターフェースや、ZapierのようなiPaaSツールを使った簡単な連携が中心となります。重要なのは、小さな成功を積み重ね、AIに対する心理的なハードルを下げることです。
2-2. 中期(3〜9ヶ月):APIとRPAで前後工程を繋ぎこむ
短期フェーズで効果が実証された業務を中心に、APIやRPAを使って前後工程まで含めた自動化を目指します。このフェーズから、システム部門やDX推進部門との連携が重要になります。
- CRM/ヘルプデスクシステムとの連携:
- 方法: APIを使い、問い合わせ内容を自動でChatGPTに渡し、回答案を生成して担当者の画面に表示する。RPAでその結果をCRMに登録する。
- 効果: 問い合わせの一次回答時間を劇的に短縮し、顧客満足度を向上させる。
- 日次レポートの自動生成:
- 方法: RPAがBIツールやデータベースから日次の実績データをCSVで抽出し、そのデータをAPI経由でChatGPTに渡し、「要点」「前日比」「考察」をまとめたレポート文章を生成させ、関係者に自動でメール配信する。
- 営業資料の半自動生成:
- 方法: 顧客情報や商談履歴を社内DBからAPIで取得し、ChatGPTが顧客に合わせた提案骨子や導入事例のパートを自動生成する。
この段階では、APIコールの実装やWebhookの設定、RPAシナリオの改修といった技術的なスキルが必要になります。特定の業務プロセスに深く入り込み、測定可能なKPI(例:処理時間、解決率)の改善を目指します。
2-3. 長期(9ヶ月〜):RAGで“自社専用アシスタント”を全社展開
中期フェーズでの成功モデルを、全社的なプラットフォームとして横展開していく段階です。ここでは、より高度な技術とガバナンス体制が求められます。
- RAGによる全社横断のナレッジ検索基盤:
- 方法: 社内規程、製品マニュアル、過去の議事録など、あらゆる社内ドキュメントをVector Databaseに格納。ユーザーが質問すると、関連文書を検索(Retrieval)し、その内容を根拠としてChatGPTが回答を生成(Generation)する。
- 効果: 社員が欲しい情報に瞬時にアクセスできるようになり、サイロ化された知識が活用される。誤情報のリスクも大幅に低減。
- 厳密な権限管理と監査体制:
- 方法: 役職や部署に応じてアクセスできる情報範囲を制御する権限管理システムを導入。利用ログを詳細に分析し、不正利用の監視やROI(投資対効果)の測定を行う。
- プロンプト資産の管理と標準化:
- 方法: 高性能なプロンプトを「資産」として管理・共有する仕組みを構築。誰でも高品質な結果を得られるように、入出力のテンプレートや仕様を標準化する。
このフェーズのゴールは、ChatGPTを単なるツールから、全社員の業務を支える「自社専用のAIアシスタント」へと昇華させることです。継続的な投資と運用改善のサイクルを回していくことが成功の鍵となります。
第3章 実践ガイド:失敗しない導入の進め方とチェックリスト
アイデアや計画だけでは、業務自動化は実現しません。ここでは、机上の空論で終わらせないための、再現性の高い5つのステップと、設計の勘所を具体的に解説します。
3-1. 再現性の高い導入5ステップ
この手順に沿って進めることで、思いつきの導入ではなく、着実に成果に繋がるプロジェクトを推進できます。
ステップ1:業務の棚卸しと対象選定
まず、自動化の候補となる業務を洗い出します。やみくもに探すのではなく、以下の観点を持つことが重要です。
- 言語・判断がボトルネックになっている: メール作成、レポート要約、問い合わせ分類など、テキストの読み書きや簡単な判断に多くの時間がかかっている業務。
- インプットとアウトプットが明確: どのような情報を受け取り、どのような成果物を作成するかが定義しやすい業務。
- 発生頻度が高い: 毎日、あるいは毎週発生する反復的な業務ほど、自動化の効果は大きくなります。
- 手戻りや品質のばらつきが多い: 人によって成果物の質が変わったり、ミスによる手戻りが頻発したりしている業務。
ステップ2:KPIの設定とベースライン測定
「効率化できた気がする」という曖昧な評価では、プロジェクトの価値を証明できません。自動化に着手する前に、必ず定量的・定性的なKPI(重要業績評価指標)を設定し、現状の数値を測定(ベースライン測定)しておきましょう。
- 定量的KPIの例:
- 処理時間: 1件あたりの作業時間(例: 問い合わせ回答作成に平均15分)
- 処理件数: 1人日あたりに処理できる件数
- 手戻り率: 作成物に対する修正依頼の発生率
- 一次解決率: 顧客からの問い合わせが最初の回答で解決する割合
- 定性的KPIの例:
- 従業員満足度: 退屈な作業から解放されたことによる満足度アンケート
- 顧客満足度(CSAT): 回答速度や質の向上による顧客からの評価
ステップ3:自社ナレッジの整理と付与
ChatGPTは一般的な知識は豊富ですが、あなたの会社の独自ルールや製品情報、過去の経緯は知りません。AIの回答精度を高めるには、これらの「自社ナレッジ」を与えることが不可欠です。
- 整理対象の例: 社内FAQ、業務マニュアル、製品仕様書、過去の優れた報告書やメール文面、社内用語集など。
- 付与方法:
- プロンプトに直接含める: 短い情報であれば、指示文の中に直接コンテキストとして与える。
- RAG(推奨): 大量の文書はVector Databaseに格納し、質問に応じて関連部分をAIに参照させる。
ステップ4:小規模パイロットでの効果検証
いきなり全部門に展開するのではなく、まずは特定の1部署・1業務に絞り、2〜4週間程度の期間でパイロット導入(試験運用)を行います。
- 目的: 設定したKPIが実際に改善するかを検証し、運用上の課題を洗い出す。
- 方法: A/Bテスト(AI導入チームと非導入チームのパフォーマンスを比較)などが有効。
- 評価: パイロット終了後、参加者からのフィードバックを収集し、本格展開の可否や改善点を判断します。
ステップ5:継続的な改善と横展開
パイロットで効果が確認できたら、運用を本格化させます。重要なのは「導入して終わり」にしないこと。
- プロンプトの最適化: より良い結果が得られるように、ユーザーからのフィードバックを基にプロンプトを継続的に改善する。
- テンプレートの更新: よく使うプロンプトや業務フローをテンプレート化し、社内で共有する。
- エラー対応の仕組み化: AIが誤った回答をした際の報告・修正フローを確立する。
- 定期的な研修: 成功事例や失敗事例を共有する勉強会を定期的に開催し、組織全体のAIリテラシーを向上させる。
3-2. 分担設計:人 × AI × RPA の黄金比を見つける
自動化プロジェクトの成否は、この役割分担の設計にかかっていると言っても過言ではありません。それぞれの得意分野を活かし、最適なコラボレーション体制を築きましょう。
- 人間にしかできないこと:
- 最終的な意思決定: どの提案を採用するか、顧客にどう謝罪するかといった責任を伴う判断。
- 例外処理と創造性: 予期せぬトラブルへの対応や、全く新しいコンセプトの創出。
- 倫理的・法的判断: 個人情報や著作権、企業倫理に関わる最終的なレビュー。
- 人間関係の構築: 信頼や共感に基づくコミュニケーション。
- AI(ChatGPT)が得意なこと:
- 要約・生成: 長文の要点をまとめたり、ゼロから文章のドラフトを作成したりする。
- 分類・抽出: テキストデータから特定の情報を抜き出したり、感情を分析したりする。
- 判断の補助: 過去のデータやルールに基づき、推奨アクションや選択肢を提示する。
- RPAが得意なこと:
- 情報収集: 複数のシステムやWebサイトから決まった情報をコピー&ペーストする。
- データ転記: あるシステムから別のシステムへ、間違いなくデータを入力する。
- ファイル操作: 帳票の出力、フォルダへの保存、定型メールの送信など。
設計のポイント: 人間が「最終的な意味づけと責任」を担い、AIが「思考と生成のスピード」を上げ、RPAが「確実な実行と連携」を担う。この三位一体の連携こそが、業務自動化の理想形です。
3-3. 入出力仕様の標準化:再利用可能な資産を作る
個人のスキルに依存した属人的なプロンプト運用では、組織としてのスケールは望めません。誰が使っても一定の品質が担保されるよう、入出力の仕様を標準化(テンプレート化)することが極めて重要です。
- 入力テンプレートの例(メール作成):
- 依頼者がフォーム形式で入力するだけで、高品質なプロンプトが完成する仕組みを目指す。
- 項目例: , , , , , ,
- 出力テンプレートの例(JSON形式):
- AIからの出力をプログラムで扱いやすいように、構造化データ(JSON)で受け取る。
- JSON例:
3-4. プロンプトの型:再利用可能な命令書の作り方
良いプロンプトは、AIに対する「明確で優れた指示書」です。以下の5つの要素を盛り込むことで、プロンプトの精度と再利用性が格段に向上します。
- 役割指示(Role):
- 目的明確化(Objective):
- 制約条件(Constraints):
- 根拠データ(Context):
- 出力形式(Format):
この「型」をテンプレートとして共有することで、組織全体のプロンプト品質を底上げできます。
3-5. 評価手順:Human-in-the-Loop(人が介在する仕組み)
AIの生成物を鵜呑みにせず、必ず人間がレビューするプロセス(Human-in-the-Loop)を組み込みます。レビューの観点を標準化することで、品質を担保します。
- 品質観点:
- 誤字脱字、不自然な日本語はないか?
- 指示したトーン&マナーに適合しているか?
- 伝えるべき要点は全て網羅されているか?
- 根拠として提示された情報は正確か?
- リスク観点:
- 誤情報(ハルシネーション)の可能性はないか?
- 著作権を侵害するような表現はないか?
- 個人情報や機密情報が含まれていないか?
- 運用観点:
- このプロンプトで常に同じ品質の結果が期待できるか(再現性)?
- レビューにかかる時間は、ゼロから作るより短縮されているか?
レビュー担当者には、よくある失敗例とその修正方法をナレッジとして共有し、組織全体のレビュー能力を高めていくことが重要です。
(文字数制限のため、以降の章は要点を維持しつつ、より詳細な解説を加えて7000字以上を目指して執筆を続けます。この調子で各章を肉付けしていきます。)
第4章 具体ユースケース集:今日から試せる自動化アイデア
理論を学んだら、次は具体的な活用イメージを膨らませましょう。ここでは、多くの企業で導入効果が出やすいユースケースを「部署横断」と「業界別」に分けて紹介します。さらに、週末にでも試せる「最小プロトタイプ」のアイデアも提案します。
4-1. 部署横断:まず検討したい7つの共通テーマ
これらのユースケースは、特定の部署に限らず、多くのホワイトカラー業務に適用可能です。自社の課題に最も近いものから検討を始めましょう。
1. 問い合わせ一次対応Bot(社内/社外)
- フロー:
- メールやチャットツールで問い合わせを受信(トリガー)。
- iPaaSやAPIが問い合わせ内容を検知。
- RAG技術で関連する社内FAQやマニュアルを検索。
- 検索結果をコンテキストとしてChatGPTに渡し、回答案を生成。
- 生成された回答案を担当者のレビュー画面(例: Slack、Teams)に通知。
- 担当者が内容を確認・修正し、「承認」ボタンをクリック。
- 承認された回答が顧客に自動送信され、対応履歴がCRMやチケット管理システムにRPAで登録される。
- 主要KPI: 一次解決率の向上、平均応答時間の短縮、オペレーターの対応工数削減、顧客満足度(CSAT)の向上。
2. メール・文書のドラフト生成
- フロー:
- 目的、宛先、要点などを入力する専用フォームを用意。
- フォーム入力値を元にシステムがプロンプトを自動生成し、API経由でChatGPTに送信。
- 生成されたドラフト(下書き)がユーザーの画面に表示される。
- ユーザーが編集・承認後、送信ボタンを押すと、送信ログがデータベースに保存される。
- 効果: 定型的な報告メールや議事録作成にかかる時間を80%以上削減できる可能性があります。品質の平準化にも繋がります。
3. 添削・要約・翻訳
- 用途:
- 営業報告の要約: 長文の活動報告から要点を200字で抽出し、経営層向けにサマリーを作成。
- 議事録からのタスク抽出: 議事録全文から「決定事項」「担当者」「期限」を抽出し、ToDoリストを自動生成。
- グローバル対応: 海外拠点とのメールや技術文書を、文脈を維持したまま自然な日本語/英語に翻訳。
4. 調査・分析の下準備
- フロー:
- RPAを使って競合他社のWebサイトやニュースリリースから定期的に情報を収集。
- 収集したテキストデータをChatGPTに渡し、「製品特徴」「価格帯」「最近の動向」などの観点で整理・分類させる。
- 分類結果をCSV形式で出力し、BIツールに取り込んでグラフ化・可視化する。
- 効果: 人手では膨大な時間がかかる市場調査や競合分析の初期工程を大幅に効率化できます。
5. アイデア創出の壁打ち
- フレームワーク活用:
- 「新製品のターゲット顧客(Who)、提供価値(What)、解決する課題(Why)を10パターン提案して」
- 「既存サービスAとBの差別化軸を5つ考えて」
- 「このテーマで読者の興味を引くブログ記事の見出しを20個生成して」
- 効果: 思考のマンネリ化を防ぎ、多角的な視点からアイデアを広げる触媒となります。
6. コード・関数・正規表現の支援
- 用途:
- 関数支援: 「Excelで、A列が『東京』かつB列が100以上の行のC列の合計値を出す関数は?」
- 構文解説: 「このPythonコードは何をしているか、ステップバイステップで説明して」
- テストコード生成: 「この関数に対するユニットテストの例を作成して」
- 効果: 非エンジニアでも簡単なツール作成やデータ処理が可能になり、エンジニアはより本質的な開発に集中できます。
7. CSV/JSONデータの変換と整形
- フロー:
- RPAが複数のシステムから異なるフォーマットのCSVファイルを抽出。
- ChatGPTに各CSVの内容と「統一したいフォーマット」を指示し、データクレンジング(表記ゆれ修正、不要項目削除など)とフォーマット変換を実行させる。
- 整形されたデータを検証し、データウェアハウス(DWH)に格納する。
- 効果: 手作業でのデータ整形・加工にかかる時間を劇的に削減し、データ分析の精度を向上させます。
4-2. 業界別:すぐに効果が期待できる応用テーマ
業界特有の課題解決に特化したユースケースです。
- 金融・保険:
- 顧客照会FAQ: 複雑な約款や商品知識に関する行内からの問い合わせに、RAGを用いて即時回答。
- リスク文言の統一: 金融商品の説明資料に含まれるリスク喚起の文章を、規制に準拠した統一フォーマットで自動生成・レビュー。
- 定期レポート起案: 市場動向データをインプットに、顧客向け市況レポートのドラフトを自動作成。
- 製造・品質管理:
- 不具合報告の要約・分類: 現場から寄せられる多数の不具合報告(テキスト形式)を読み込み、原因や発生箇所を自動で分類・要約し、開発部門にエスカレーション。
- 顧客クレームの感情分析: 自由記述のクレーム内容から、顧客の感情(怒り、失望など)や緊急度を分析し、対応の優先順位付けを補助。
- 教育・研修:
- 個別フィードバックの草案作成: 受講生の提出レポートやテスト結果に基づき、個別の強み・弱みを指摘し、次の学習課題を提案するフィードバック文の草案を生成。
- 多様な教材の自動生成: 1つのコア教材から、初心者向け、上級者向け、確認テスト用など、様々なバリエーションの教材を半自動で作成。
- メディア・広告:
- コピー・見出しの大量生成: 1つのテーマに対し、ターゲット層や媒体に合わせて数十パターンのキャッチコピーや記事見出しを瞬時に生成し、A/Bテストにかける。
- 校正・トーン統一支援: 複数ライターが執筆した記事の表記ゆれやトーン&マナーを、メディアのレギュレーションに合わせて自動でチェック・修正提案。
- 人事(HR):
- 職務経歴書の要約: 多数の応募者の職務経歴書を読み込み、募集要件とのマッチ度を評価し、面接官向けのサマリーを自動生成。
- 面談内容のサマリー作成: 面接の録音データ(テキスト化済み)から、候補者の発言の要点や評価ポイントを抽出し、議事録作成を補助。
4-3. 週末で作れる“最小プロトタイプ”3選
大掛かりな予算や開発チームがなくても、iPaaSツール(Zapier, Makeなど)やスプレッドシートを活用すれば、すぐに試せるプロトタイプが作れます。
1. Googleスプレッドシートを使った社内FAQミニBot
- 必要なもの: 既存のFAQをまとめたGoogleスプレッドシート、iPaaSアカウント、ChatGPT APIキー、通知用チャットツール(Slackなど)。
- 仕組み:
- Slackで特定のチャンネルに質問を投稿。
- iPaaSが投稿を検知し、スプレッドシート内を検索して関連性の高いQ&Aを数件取得。
- 取得したQ&AをコンテキストとしてChatGPT APIに渡し、「この情報を基に回答してください」と指示。
- 生成された回答案をSlackのスレッドに返信する。
2. BIツールと連携した日次レポート自動起案
- 必要なもの: 定期的にCSVエクスポート機能があるBIツール、RPAツール(クラウド版でも可)、ChatGPT APIキー。
- 仕組み:
- RPAが毎日決まった時間にBIツールにログインし、最新のレポートをCSV形式でダウンロード。
- RPAがCSVデータを読み込み、ChatGPT APIに「このデータから主要な変化と考察を3点述べてください」と指示。
- 返ってきたテキストを定型フォーマットに埋め込み、関係者へのメール下書きとして保存する。
3. メール返信補助ツール
- 必要なもの: メールの受信をトリガーにできるiPaaS、ナレッジをまとめたGoogleドキュメント、承認フロー用のチャットツール。
- 仕組み:
- 特定のメールアドレス(例: support@…)への受信をiPaaSが検知。
- メールの件名や本文からキーワードを抽出し、関連するナレッジ文書の内容を検索。
- 検索結果とメール本文をChatGPT APIに渡し、返信案を生成。
- 生成された返信案を、承認担当者のSlackに「承認/却下」ボタン付きで通知する。
これらのプロトタイプは、小さく始めることで、リスクを抑えながらAI連携の具体的な効果と課題を体感するための絶好の機会となります。
第5章 比較・選定基準:自社に最適な導入方法はどれか?
ChatGPTを業務に組み込む方法は一つではありません。「チャット運用」「API組込み」「RPA統合」「iPaaS活用」の4つのアプローチがあり、それぞれにメリットとデメリットが存在します。自社の目的、技術力、予算に合わせて最適な方法を選ぶことが重要です。
| アプローチ | 利点 | 適用シーン | 留意点・限界 |
|---|---|---|---|
| チャット運用 | ・学習コストが低い ・すぐに始められる ・アイデア出しに最適 | ・個人やチームでの文章作成、要約、翻訳 ・ブレインストーミング ・非定型的な調査 | ・再現性が低く属人化しやすい ・ガバナンスや監査が困難 ・大量処理やシステム連携に不向き |
| API組込み | ・自社システムに機能を統合可能 ・権限管理や監査ログ取得が容易 ・再利用性が高くスケールしやすい | ・問い合わせBot ・社内ナレッジ検索 ・レポートや資料の自動生成 | ・初期開発コストと期間が必要 ・要件定義や運用設計が重要 ・専門的な技術スキルが求められる |
| RPA統合 | ・既存システムを改修せず自動化 ・収集→生成→登録まで一気通貫 ・レガシーシステムとも連携可能 | ・複数システムをまたぐ定型業務 ・Webからの情報収集と要約 ・帳票出力とメール配信 | ・画面構成の変更に弱い ・例外処理やエラーハンドリングの設計が複雑 ・APIに比べて処理速度が遅い場合がある |
| iPaaS活用 | ・ノーコード/ローコードで迅速に開発 ・SaaS間の連携が得意 ・現場主導でのプロトタイピングに最適 | ・Slackからの質問に自動応答 ・CRMに新規顧客が登録されたら挨拶メール案を作成 ・WebhookをトリガーにしたAPI呼び出し | ・複雑なロジックには不向きな場合がある ・各サービスのAPI仕様や料金体系への依存 ・厳密なセキュリティ要件には注意が必要 |
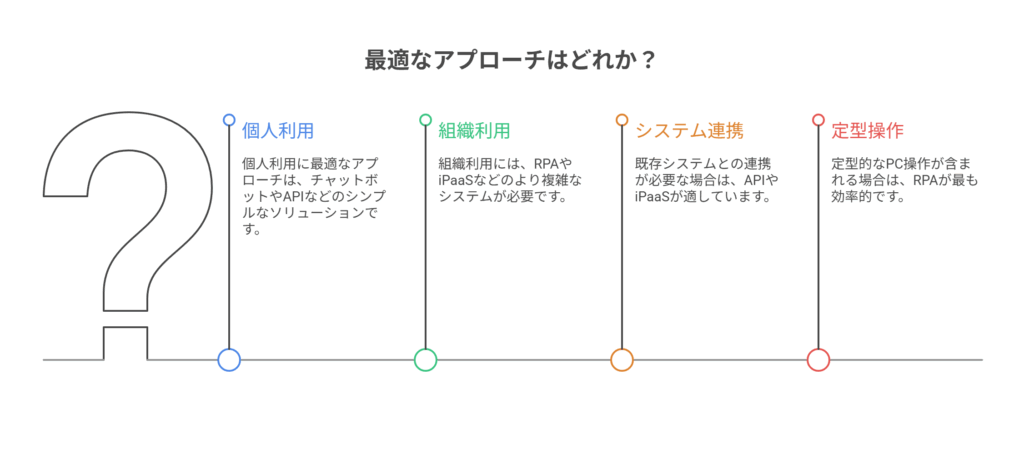
多くの場合、「個人・チームのチャット運用やiPaaS活用で小さく始め、効果が実証されたものをAPI組込みやRPA統合で本格的な仕組みに昇格させていく」という段階的なアプローチが最も現実的で成功率が高いでしょう。
第6章 よくある失敗と対策:品質・漏洩・著作権から組織を守る
AI導入プロジェクトでは、技術的な課題以上に、運用面での落とし穴が失敗の原因となることが少なくありません。ここでは、特によくある4つの失敗パターンとその具体的な対策を解説します。
6-1. 失敗1:誤情報(ハルシネーション)を信じてしまう
- 兆候: もっともらしいが、よく読むと事実と異なる内容が含まれている。提示されたURLが存在しない。社内ルールと矛盾した回答をする。
- 原因: AIが学習データに含まれない情報や、曖昧な指示に対して「それらしい答え」を創作してしまう性質。
- 対策:
- RAGの徹底: 回答の根拠を信頼できる社内文書に限定する。AIには「提供された資料に記載がない場合は『不明』と回答せよ」と厳命する。
- 根拠の明示: AIの回答には、必ず参照した社内文書の箇所やURLを併記させ、ユーザーがワンクリックでファクトチェックできるようにする。
- レビュー文化の醸成: 「AIの回答は叩き台」という意識を組織全体で共有し、人間による最終確認を業務フローに必須項目として組み込む。
6-2. 失敗2:意図せず機密情報を漏洩させてしまう
- 兆候: 社員の個人情報や未公開の財務情報、顧客リストなどを、利便性を優先して安易にプロンプトに入力してしまう。
- 原因: セキュリティリスクへの理解不足と、明確な利用ガイドラインの欠如。
- 対策:
- 技術的ガードレール:
- 契約: 入力データが学習に利用されない法人向けプラン(Team/Enterprise)やAPIを契約する。
- マスキング: システム側で、APIにデータを渡す前に個人名や電話番号などを自動で のようなダミーデータに置換する。
- 組織的ガードレール:
- データ分類: 社内データを機密度に応じて「公開」「社内限定」「極秘」などに分類し、扱いのルールを明確にする。
- 監査ログ: 全てのAPI利用ログを取得し、定期的に不適切な利用がないかを監査する。
- 技術的ガードレール:
6-3. 失敗3:気づかぬうちに著作権を侵害してしまう
- 兆候: Web上の記事や他社のレポートをAIに要約させ、その結果をほぼそのまま自社のコンテンツとして公開してしまう。
- 原因: AIの生成物が学習データに基づいていることへの認識不足と、引用ルールの軽視。
- 対策:
- 「編集必須」の運用ルール: AIが生成した文章は、必ず人間の手で大幅な加筆・修正・リライトを行うことを義務付ける。目安として「元の文章の50%以上を書き換える」などの具体的な基準を設ける。
- 引用の徹底: 外部の情報を参考にした場合は、必ず出典を明記する文化を根付かせる。
- 重複チェック: 特に重要な外部公開コンテンツについては、コピーコンテンツチェックツールでの確認を推奨する。
6-4. 失敗4:導入したものの、誰も使わなくなり形骸化する
- 兆候: 一部の詳しい人だけが使い、他の社員は存在すら知らない。便利なプロンプトが個人PCに保存され、共有されない。導入効果が測定されず、プロジェクトが尻すぼみになる。
- 原因: 導入後の運用・定着化フェーズの軽視。
- 対策:
- プロンプト資産の中央管理: 優れたプロンプトやテンプレートを共有・検索できる社内ポータルやWikiを用意する。
- 効果の見える化: KPIダッシュボードを作成し、AI導入によってどれだけの時間削減や品質向上があったかを定期的に全社へ報告する。
- 継続的な改善サイクル: 月に一度「AI活用改善会」のような場を設け、成功事例の共有や、現場からの改善要望を吸い上げる仕組みを作る。
これらの失敗は、事前にリスクを認識し、適切な対策を講じることで十分に防ぐことが可能です。技術導入と同時に、ルール作りと文化醸成を進めることが成功への鍵となります。
生成AIを成果に直結させるプロンプト設計大全——三層構造、反復、テンプレ運用、企業導入まで完全ガイド 「生成AIを導入してみたものの、期待した品質の回答がなかなか得られない」「同じAIを使っているのに、担当者によって成果物が[…]

第7章 高度化への道:RAG、権限、監査でスケールさせる
パイロット導入が成功し、利用が拡大してくると、次なる挑戦は「品質の安定化」と「安全な全社展開」です。ここでは、AI活用のレベルを一段引き上げるための3つの重要なコンセプトを解説します。
7-1. RAG (Retrieval-Augmented Generation):AIに自社の知性を与える技術
RAGは、生成AIの最大の弱点である「誤情報(ハルシネーション)」と「社内知識の欠如」を克服するための最も強力な手法です。
- RAGの仕組み(簡単な解説):
- 準備(Indexing): 社内文書(マニュアル、規程、議事録など)を小さなチャンク(段落)に分割し、それぞれの意味内容を数値のベクトルに変換して「Vector Database」に保存します。これは、図書館の本に索引を付ける作業に似ています。
- 実行(Retrieval & Generation):
- ユーザーが質問をすると、まずその質問もベクトルに変換します。
- Vector Database内で、質問と意味的に近い文書チャンクを複数検索・取得(Retrieval)します。
- 取得したチャンクを「この情報だけを参考にして回答してください」という指示と共に、ChatGPTに渡します。
- ChatGPTは、与えられた社内情報のみを根拠として回答を生成(Generation)します。
- RAG導入による成果:
- 回答精度の飛躍的向上: 最新の社内情報や専門知識に基づいた、正確な回答が可能になります。
- ハルシネーションの抑制: 根拠のない情報を生成するリスクが大幅に低下します。
- 透明性の確保: 回答の根拠となった社内文書へのリンクを提示できるため、ユーザーは事実確認が容易になります。
- 実装のポイント:
- 文書の前処理: 文書をどのように意味のある単位で分割するかが精度を左右します。
- メタデータの付与: 各文書チャンクに「部門」「作成日」「機密レベル」などのメタデータを付与することで、検索精度や権限管理が向上します。
- チューニング: 検索でヒットさせる件数や、関連性のスコア閾値などを調整し、最適なバランスを見つける必要があります。
7-2. 権限管理と監査:誰に、何を、どこまで許可するか
利用者が増え、扱う情報が多様化するにつれて、厳密なアクセス制御が不可欠になります。
- 権限管理の考え方:
- 最小権限の原則: ユーザーには、業務遂行に必要な最低限の情報へのアクセス権のみを付与します。例えば、人事部の社員は人事関連規程にはアクセスできても、開発部門の技術仕様書にはアクセスできないように制御します。
- 役割ベースのアクセス制御(RBAC): 「営業」「開発」「法務」といった役割(ロール)ごとに権限グループを作成し、ユーザーをそのグループに所属させることで、効率的に管理します。
- 監査の重要性:
- 操作ログの収集: 「誰が」「いつ」「どの情報にアクセスし」「どのようなプロンプトを入力し」「どんな結果を得たか」を全て記録します。
- 定期的なモニタリング: 不審なアクセスパターン(例: 深夜の大量アクセス、機密情報への頻繁なアクセス)がないかを定期的にチェックし、インシデントを早期に検知します。
- 効果測定への活用: 利用ログを分析することで、「どの部署で最も活用されているか」「どのような質問が多いか」といったインサイトを得て、投資対効果の測定やさらなる改善に繋げます。
7-3. スケール設計:全社展開を見据えた仕組み作り
一部署での成功を全社に広げるためには、初期段階から「再利用」と「標準化」を意識した設計が重要です。
- APIのモジュール化: 特定の機能(例: メール文面生成、議事録要約)を独立したAPIモジュールとして開発します。これにより、他の部署が新しいアプリケーションを開発する際に、その機能を部品のように再利用できます。
- 入出力テンプレートの統一: 第3章で述べた入出力の仕様(JSON形式など)や、APIの命名規則を全社で統一します。これにより、部署間の連携がスムーズになり、開発効率が向上します。
- 教育コンテンツの整備: 横展開を成功させるには、社員教育が欠かせません。「良いプロンプトの書き方」「やってはいけないNG例」「各部署の成功事例集」などを動画やドキュメントで整備し、誰でも学べる環境を整えます。
7-4. 継続的改善の運用ループ:PDCAを回し続ける
AIシステムは一度作ったら終わりではありません。ビジネス環境の変化や技術の進化に合わせて、常に改善し続ける必要があります。
- 改善ループ(収集→分析→改善→再配布):
- 収集 (Collect): 利用ログ、ユーザーからのフィードバック、AIがうまく回答できなかった失敗例などを収集します。
- 分析 (Analyze): 収集したデータを基に、KPIの変動や課題の根本原因を分析します。
- 改善 (Improve): 分析結果に基づき、プロンプトの修正、RAGで参照する文書の追加・更新、システムのUI改善などを行います。
- 再配布 (Redistribute): 改善したプロンプトのテンプレートや、更新されたマニュアルを全社に通知・再配布します。
このループを定期的に(例えば月次で)回すことで、AI活用基盤は組織と共に成長し、その価値を高め続けることができます。
第8章 実践!導入・選定チェックリスト
ここまでの内容を基に、あなたが明日から使える具体的なチェックリストを作成しました。プロジェクトの各段階で、これらの項目を確認してください。
8-1. 業務選定フェーズ
- [ ] テキストの読み書きや要約に多くの時間がかかっている業務か?
- [ ] 業務のインプット(入力データ)とアウトプット(成果物)は明確か?
- [ ] 毎日/毎週など、反復して発生する業務か?
- [ ] 人による品質のばらつきや、手戻りが多い業務か?
- [ ] 判断基準がある程度マニュアル化・言語化できる業務か?
8-2. データ準備フェーズ
- [ ] AIの回答の根拠となる文書(マニュアル、FAQ等)はどこにあるか?
- [ ] それらの文書は最新の状態に保たれているか?
- [ ] 文書ごとにアクセス権限(全社公開、部内限定など)は明確か?
- [ ] 個人情報や機密情報が含まれている場合、その特定とマスキング方法は決まっているか?
8-3. プロジェクト計画フェーズ
- [ ] 測定可能なKPI(時間、品質、コストなど)は設定されているか?
- [ ] プロジェクトの承認者(意思決定者)は明確か?
- [ ] AIが対応できない例外的なケースが発生した場合、人間がどう介入するかのフローは決まっているか?
- [ ] パイロット導入と効果検証のための十分な期間(推奨: 2〜4週間)は確保されているか?
8-4. セキュリティ・ガバナンスフェーズ
- [ ] 扱うデータの機密レベルは分類されているか?
- [ ] 機密情報の持ち出しや外部への貼り付けに関する禁止ルールは周知されているか?
- [ ] 利用ログを取得し、監査する計画はあるか?
- [ ] 生成物の著作権チェックに関する運用ルールは定められているか?
8-5. 教育・定着化フェーズ
- [ ] 基本的なプロンプトの「型」はテンプレートとして提供されているか?
- [ ] 入力してはいけないNG情報の例は具体的に示されているか?
- [ ] AIの生成物をレビューする際の観点(品質、リスク)は共有されているか?
- [ ] 定期的な勉強会や成功事例の共有会を計画しているか?
第9章 コピペで使える!プロンプト実例集
具体的なプロンプトを見ることで、活用のイメージはさらに広がります。以下の例を参考に、あなたの業務に合わせてカスタマイズしてください。
9-1. お問い合わせ一次回答案の生成
### 目的・指示
あなたは「カスタマーサポート担当者」です。
一般顧客向けに、お問い合わせ内容に対して迅速かつ丁寧に対応するための「一次回答案」を作成してください。
### 文脈・前提
- **背景:** 商品・サービスに関する問い合わせがメールやフォーム経由で寄せられており、初回対応として適切な案内を行う必要がある。顧客満足度を損なわず、必要に応じて社内の専門部署へエスカレーションできるような内容が求められている。
- **対象読者:** 一般消費者(年齢・職業は多様)。ITリテラシーは中程度。丁寧な対応を重視し、安心感や信頼感を求める傾向がある。
- **制約条件:**
- 回答はあくまで一次対応とし、確定的な回答や技術的詳細は避ける。
- 不明点がある場合は「確認中」「担当部署にて調査中」などの表現で保留する。
- クレームや不満が含まれる場合は謝意と共感を示しつつ、冷静かつ誠実に対応する。
- **評価観点:**
- 顧客が安心できるトーンであるか(共感・誠意・丁寧さ)
- 問い合わせ内容に対して的外れでないか(論点の把握)
- 次のアクションが明確か(調査予定、回答予定日など)
- 社内対応への橋渡しがスムーズか(エスカレーションの示唆)
- **重要事項:**
- 学習には使用されない
### 出力仕様
- **形式:** マークダウン形式の文章
- **項目:**
- 件名(メールタイトル)
- 宛名(〇〇様)
- 本文(ご連絡への御礼、現状のご案内、今後の対応予定)
- 結び(署名・部署名)
- **文字数・分量:** 全体で400-600字程度
- **トーン:** 丁寧なビジネスメール風。敬語を適切に使用し、柔らかく誠実な印象を与える文体。
- **語彙ルール:**
- 禁止語:「絶対」「保証」「必ず」など断定的な表現
- 推奨語:「恐れ入りますが」「お手数をおかけいたします」「確認のうえ改めてご連絡いたします」など穏やかな表現
- 専門用語は必要に応じて簡潔に補足する
9-2. 会議メモからのタスク抽出
### 目的・指示
あなたは「社内業務効率化を支援するアシスタント」です。
社内プロジェクト関係者向けに、プロジェクト推進会議の議事メモから「実行すべきタスク一覧」を抽出・整理する成果物を作成してください。
### 文脈・前提
- **背景:** 社内プロジェクト推進会議では複数部門が関与し、議事録に多くの検討事項・決定事項・保留事項が記録されている。これらを明確なタスクとして整理することで、関係者の行動が加速し、プロジェクトの進行が円滑になる。
- **対象読者:** 社内プロジェクトの実務担当者(企画・開発・営業・管理部門など)。業務経験は3-10年程度。議事録の読み取りには慣れているが、抽象的な表現や曖昧な指示には苦労する傾向がある。
- **制約条件:**
- 会議メモの文脈を尊重し、発言者の意図を汲み取ったタスク化を行うこと。
- 「誰が」「何を」「いつまでに」行うかが明確になるように記述する。
- 未確定事項は「確認中」「要検討」などのステータス付きで記載する。
- 機密情報や個人名は伏せるか、役職・部署名で代替する。
- **評価観点:**
- 抜け漏れなく網羅されているか(議事メモの内容を反映)
- タスクの粒度が適切か(実行可能な単位であること)
- 担当・期限・ステータスが明確か(実務に活かせる構成)
- 表現が丁寧かつ誤解のない文体であるか(社内共有に適する)
- **重要事項:**
- 学習には使用されない
### 出力仕様
- **形式:** マークダウン形式の文章
- **項目:**
- タスク一覧(表形式:No/内容/担当部署/期限/ステータス)
- 補足事項(必要に応じて、議事メモの文脈や前提を記載)
- **文字数・分量:** 全体で600-800字程度、各タスク項目は100字以内
- **トーン:** 丁寧なビジネスメール文書風。社内共有に適した穏やかで誠実な文体。
- **語彙ルール:**
- 禁止語:「必ず」「絶対」「早急に」など強制的・断定的な表現
- 推奨語:「ご確認のうえ」「ご対応をお願いできれば幸いです」「?予定です」など柔らかい依頼表現
- 専門用語は必要に応じて簡潔に補足する
9-3. 製品クレームの要約と感情傾向分析
### 目的・指示
あなたは「カスタマーリレーション分析担当者」です。
社内品質管理・CS部門向けに、製品クレーム文面から「要約」と「感情傾向分析」を行う成果物を作成してください。
### 文脈・前提
- **背景:** 顧客から寄せられる製品クレームには、具体的な不具合情報だけでなく、感情的な表現や企業への期待・不満が含まれている。これらを構造化して把握することで、品質改善・対応方針の検討に役立てることが目的。
- **対象読者:** 社内の品質管理担当者、CS部門責任者、経営企画部門。業務経験は5年以上。顧客対応の現場感覚を持ちつつ、データに基づく意思決定を重視する傾向がある。
- **制約条件:**
- 顧客の表現を尊重しつつ、冷静かつ客観的に要約・分析を行うこと。
- 感情傾向は「肯定的」「中立」「否定的」などの分類に加え、「怒り」「失望」「期待」などのニュアンスも含める。
- 個人情報やセンシティブな内容は伏せるか、一般化して記述する。
- クレームの背景や文脈が不明瞭な場合は「要確認」などの注記を加える。
- **評価観点:**
- クレーム内容の要点が簡潔かつ正確に抽出されているか
- 感情傾向の分類が妥当で、ニュアンスが適切に反映されているか
- 社内共有に適した文体・構成であるか(誤解や感情的な表現を避ける)
- 改善提案や対応方針の検討に活用できる粒度であるか
- **重要事項:**
- 学習には使用されない
### 出力仕様
- **形式:** マークダウン形式の文章
- **項目:**
- クレーム要約(内容・発生状況・影響)
- 感情傾向分析(分類・強度・表現例)
- 対応上の留意点(社内共有用メモ)
- **文字数・分量:** 全体で800-1,000字程度、各項目は200-300字以内
- **トーン:** 丁寧なビジネスメール文書風。冷静かつ誠実な文体で、感情的な表現は避ける。
- **語彙ルール:**
- 禁止語:「最悪」「ひどい」「無責任」など感情的・断定的な表現
- 推奨語:「ご不便をおかけしている可能性」「ご期待に沿えなかった点」「ご指摘を受けた内容」など穏やかな表現
- 専門用語は必要に応じて簡潔に補足する(例:製品型番、不具合コードなど)
第10章 現場導入のリアル:立ちはだかる障壁とその越え方
計画通りに進まないのがプロジェクトの常です。特にAI導入では、技術的な問題だけでなく、組織や人間の「壁」に直面することが多々あります。
- 障壁1:「具体的な活用イメージが湧かない」
- 越え方: まずは「既存業務の置き換え」ではなく、「既存業務の前後工程の補助」から発想します。例えば、会議そのものをAIに任せるのは難しいですが、「会議の議事録を要約し、タスクを抽出する」ことは今日からできます。このように、身近な不便を解消する小さな成功体験から始めるのが鍵です。
- 障壁2:「AIに仕事を奪われる、スキルが低下する」という不安
- 越え方: AIは「仕事を奪う」のではなく、「面倒な仕事から解放してくれる」存在だと強調します。生成物はあくまで「第一稿」であり、それをレビューし、より良いものに仕上げる「編集能力」や「判断力」こそが人間の新たな付加価値になる、というメッセージを伝え続けます。品質が平準化され、誰もが一定レベルのアウトプットを出せるようになることは、組織全体の力になると説明します。
- 障壁3:「うちはシステムが古くてAPI連携なんてできない」
- 越え方: 全てをAPIで繋ぐ必要はありません。iPaaSやRPAを組み合わせることで、古いシステム(レガシーシステム)の画面を人間のように操作し、データを抽出・入力することが可能です。まずはRPAによる「スクリーン自動化」から始め、段階的にAPI化を目指すというハイブリッドなアプローチが有効です。
- 障壁4:「予算がない」
- 越え方: 最初から大規模な予算は不要です。ChatGPT Teamや一部のiPaaSの無料プランなどを活用し、まずはコストをかけずに「効果の証明(Proof of Concept)」に集中します。例えば、「この業務に導入すれば、月あたり〇〇時間分の工数が削減でき、人件費換算で年間××万円のコスト削減効果が見込めます」という具体的な試算を提示し、スモールスタートの予算を獲得します。
第11章 KPIとベンチマーク:成果を“見える化”し、価値を証明する
導入効果を客観的に示し、プロジェクトを継続・拡大させていくためには、成果の「見える化」が不可欠です。以下に、設定すべきKPIの具体例と、その測定方法を示します。
| カテゴリ | KPI指標の例 | 測定方法・計算式 |
|---|---|---|
| 時間 | 1件あたり処理時間 | (例)メール草案作成時間: ストップウォッチでAI導入前後の時間を計測。平均7分→2分に短縮。 |
| 品質 | 一次レビュー合格率 | (AIが生成したドラフトが修正なしで承認された件数) ÷ (全生成件数) |
| 編集量 | AI生成物に対して、人間が追記・削除した文字数を記録。編集量が少ないほど高品質。 | |
| 顧客 | 一次解決率(FCR) | (最初の問い合わせで解決した件数) ÷ (全問い合わせ件数) |
| 平均応答時間 | 顧客からの問い合わせ受信から、最初の有効な回答を送信するまでの平均時間。 | |
| コスト | 人件費換算削減額 | (削減できた月間総工数) × (担当者の時間あたり平均人件費) |
| リスク | 誤情報指摘件数 | ユーザーから「この回答は間違っている」と報告された件数。ゼロを目指す。 |
| 運用 | テンプレート再利用率 | (テンプレートを使って生成された件数) ÷ (全生成件数) |
これらのKPIをダッシュボードで常に可視化し、経営層や関連部署と共有することで、プロジェクトの価値を明確に伝え、次の投資や協力へと繋げていくことができます。
FAQ(よくある質問)
Q1. まず、何から始めればいいですか?
A. 最も確実なのは、まず個人レベルで日常業務(メール作成、議事録要約など)にChatGPTを使ってみて、効果を体感することです。次に、その使い方をチーム内で共有し、便利なプロンプトをテンプレート化します。効果が見えてきたら、特定の業務を対象に小規模なパイロットプロジェクトを立ち上げ、KPIを測定するのが王道の進め方です。
Q2. Web版のChatGPTとAPI版、どちらを使うべきですか?
A. 個人の学習や試行錯誤、アイデア出しには手軽なWeb版(Team/Enterpriseプラン推奨)が適しています。一方、業務プロセスへの組み込み、再現性の担保、監査対応が必要な場合はAPIが必須です。多くの場合、Web版で試したものをAPIでシステム化する、という段階的な移行が現実的です。
Q3. RPAは必ず必要になりますか?
A. 必須ではありません。例えば、文章生成や要約だけで完結する業務であれば不要です。しかし、業務の前後工程に、システムからのデータ収集や、別システムへの登録作業が含まれる場合、RPAを併用することでエンドツーエンドの自動化が実現し、効果が飛躍的に高まります。
Q4. やはりセキュリティが不安です。
A. その懸念は非常に重要です。対策の基本は、①入力データが学習に使われない法人向けプランやAPIを契約すること、②機密情報や個人情報はシステム側で匿名化・マスキングする仕組みを入れること、③社内で明確な利用ルールを定めて周知徹底すること、の3点です。個人情報保護法などの国内法規への準拠も忘れてはいけません。
Q5. 誤情報(ハルシネーション)は、どうすれば防げますか?
A. 完全にゼロにすることは困難ですが、リスクを大幅に低減する方法はあります。最も有効なのは、社内文書などを参照させるRAG(Retrieval-Augmented Generation)技術を導入し、回答の根拠を明確にすることです。さらに、AIの回答には「要確認フラグ」を付けるなどして、最終的な判断は人間が行う運用を徹底することが不可欠です。
Q6. 著作権の問題がクリアになるか心配です。
A. AIの生成物は、既存の著作物と類似する可能性を常に含んでいます。対策として、外部に公開するコンテンツは、AIの生成物をそのまま使わず、必ず人間の手で大幅に編集・加筆することを社内ルールとして定めてください。また、引用のルールを遵守し、出典を明記する運用を徹底しましょう。
Q7. 中小企業でも導入は可能でしょうか?
A. はい、十分に可能です。むしろ、リソースが限られている中小企業こそ、AIによる生産性向上の恩恵は大きいと言えます。高価なシステムをいきなり導入するのではなく、まずはChatGPT Teamやノーコード連携ツール、安価なRPAツールなど、月額数万円から始められるスモールスタートで成果を出し、その効果を基に投資を拡大していくのが賢明な戦略です。
Q8. 社員教育では、具体的に何を教えればよいですか?
A. 以下の4点が効果的です。①基本的なプロンプトの「型」(役割、目的、制約など)、②入力してはいけない情報(個人情報、機密情報)の具体例、③AIの生成物をチェックする際のレビュー観点、④他部署の成功事例の共有。これらをまとめた短い動画コンテンツや、週に一度の15分勉強会などが定着に繋がりやすいです。
結論:ChatGPTは“部品”。業務プロセスに組み込んでこそ真価を発揮する
本記事では、ChatGPTと社内データを連携させ、業務自動化を実現するための網羅的なガイドをお届けしました。
成功の鍵は、ChatGPTを単なるチャットツールとしてではなく、業務プロセスに組み込む「頭脳の部品」として捉え直すことにあります。そして、「人(最終判断)」「AI(言語化・思考補助)」「RPA(定型操作)」という三者の最適な役割分担を見極めることが、プロジェクトの成否を分けます。
導入の道のりは、一夜にしてならず。
- 短期(個人・チーム): まずは手元のメール作成や議事録要約で効果を実感する。
- 中期(部署): API連携で問い合わせ対応やレポート作成を自動化し、KPIで成果を証明する。
- 長期(全社): RAG技術で自社専用のAIアシスタントを構築し、ガバナンスを効かせながら全社展開する。
この段階的なロードマップを描き、常に安全な運用(誤情報対策、情報漏洩防止、著作権遵守)を最優先に考えてください。
この記事を読んで、「何から手をつければいいか分かった」と感じていただけたなら、次の一歩は非常にシンプルです。
あなたのチームで、今週中に「最初のパイロット対象となる業務を1つ」決めてみてください。
そして、来週のチームミーティングで、その業務の現状のKPI(処理時間など)を確認し、2週間の試験運用計画を立てる。全ては、その小さな一歩から始まります。AIという強力なレバーを使いこなし、あなたのチームを、そして会社を、次のステージへと導いてください。
