

現場から始める「生産管理×AI需要予測」実践ガイド:在庫・生産計画・品質・保全・安全までつなぐロードマップ
はじめに:その“勘とExcel管理”から、一歩先の未来へ
「需要が読めず、欠品が怖いが過剰在庫も避けたい」
「急な受注変更で、苦労して作った生産計画が毎日崩れてしまう」
「品質検査の基準が担当者によってバラバラで、不良品が見逃されることがある」
「設備が突然止まってから慌てて修理に走り、生産ライン全体が停止する」
もし、これらがあなたの現場の日常風景なら、この記事はまさにあなたのために書かれました。多くの製造現場が抱えるこれらの根深い悩みは、もはや根性論や個人の頑張りだけでは解決が困難な時代です。しかし、データを起点にAIを活用することで、これらの課題は段階的かつ劇的に解消できる可能性があります。
本記事は、「生産管理 AI需要予測 実践」というテーマに対し、単なる理論解説に留まりません。需要予測という起点から、生産スケジューリング、品質検査、予知保全、さらには安全監視まで、製造業のバリューチェーンを一気通貫でつなぐための、具体的で実践的なロードマップを提示します。
属人化とExcel管理の限界を超え、投資対効果をしっかりと見極めながら「小さく始めて速く学ぶ」ための、再現性のある手順・KPI・ツール選定基準を網羅的に解説します。この記事を読み終える頃には、明日から着手できる「小さな実証実験(PoC)から全社的な本番展開まで」の鮮明な全体像が、あなたの手の中にあるはずです。
先に結論:本記事の重要ポイント
この記事は長文ですが、時間がない方のために、まず核となるポイントを7つにまとめました。
- 需要予測は全ての起点: 生産管理の成功は、精度の高い需要予測から始まります。過去の販売実績に加え、季節・価格・天候・イベント・Web検索動向といった多様な外部要因を統合したAI予測が、在庫最適化、欠品・過剰在庫の抑制、そして生産平準化の鍵を握ります。
- データ基盤と連携が成否を分ける: AIはデータという“燃料”なしには動きません。販売、在庫、生産、購買、人員、保全といった社内ログに、外部データを統合するデータ基盤の設計が不可欠です。データの欠損、外れ値、粒度の不整合を事前に整える地道な作業が、後の成果を大きく左右します。
- 「小さく始めて速く学ぶ」が鉄則: 全社一斉導入は失敗のもとです。特定の製品群やラインで実証実験(PoC)を行い、効果を測るKPIを明確に設定します。短いサイクルで改善を繰り返し、効果を実感しながら展開することが、現場の納得感を得てプロジェクトを推進する秘訣です。
- 人の判断を尊重する仕組み(HITL): AIは万能ではありません。最終的な意思決定は人間が行う「ヒューマン・イン・ザ・ループ(HITL)」の思想を取り入れ、AIの提案を鵜呑みにせず、現場の知見を反映できる運用フローを構築することがリスク管理の観点から重要です。
- AIで複雑な制約を最適化: 生産スケジューリングAIは、段取り時間、納期、設備能力、人員スキル、コストといった無数の制約条件を同時に考慮し、最適な生産計画を瞬時に立案します。これにより、計画作成時間の大幅な短縮と、急な変更への迅速な対応が可能になります。
- 品質と安定稼働をAIが下支え: 品質管理では画像認識AIが検査を自動化・標準化し、プロセスデータの異常検知AIが不良発生の予兆を捉えます。また、予知保全AIは設備の故障を事前に予測し、計画外のライン停止と保全コストを劇的に削減します。
- ツール選定は多角的な視点で: ツール選びは、自社の生産方式、事業規模、既存システムとの連携性、そしてベンダーが持つ製造業への深い知見(ドメイン知識)を総合的に評価して決定します。近年は専門家でなくても扱えるノーコード/ローコードツールも増えており、小さく始めるハードルは下がっています。
基礎理解:AI需要予測と生産管理の「つながり」を掴む
なぜ今、これほどまでに製造業でAI、特に需要予測が注目されているのでしょうか。その理由と、生産管理全体におけるAIの役割を理解することから始めましょう。
なぜ今、AI需要予測が不可欠なのか?
生産管理の根幹は、一言で言えば「需要に対して、最適なタイミング・量・コストで供給を行うこと」に尽きます。この「需要」の予測が全ての計画の出発点であり、予測が大きく外れれば、下流の在庫、生産、購買、人員配置、物流といった全ての活動が連鎖的に非効率になってしまいます。
従来の「ベテランの勘と経験」やExcelによる予測は、過去のパターンや季節性といった限定的な要因しか考慮できませんでした。しかし、現代の市場は、以下のような複雑な要因に常に晒されています。
- 外部要因の多様化: 天候、競合の価格変動、SNSでの話題化(バズ)、大型連休や地域のイベントなど。
- 製品ライフサイクルの短期化: 新製品の投入サイクルが速まり、過去データが少ないケースが増加。
- サプライチェーンのグローバル化と複雑化: 部品調達のリードタイム変動や地政学リスク。
AI、特に機械学習モデルは、これらの多様で複雑な要因を同時に学習し、人間では捉えきれない相関関係を見つけ出すことができます。さらに、一度モデルを構築すれば、新しいデータを取り込みながら継続的に学習し、予測精度を自己改善していくことが可能です。これは、Society 5.0やConnected Industriesといった大きな潮流の中で、データに基づいた意思決定が企業の競争力を左右する時代における、必須の能力と言えるでしょう。
多くの現場が陥る“ボトルネック”の正体
AI導入を検討する前に、まずは現状の課題を正しく認識することが重要です。多くの製造現場では、以下のような共通のボトルネックが存在します。
- 属人化の壁: 特定のベテラン担当者の頭の中にしかノウハウがなく、その人が不在だと計画が立てられない。異動や退職による技術継承が困難。
- Excelの限界: ファイルが部門ごと・担当者ごとに分散し、最新版がどれか分からない。手作業での更新はミスを誘発し、複数人での同時編集も困難。複雑な計算やデータ連携には限界がある。
- データの分断と品質問題: 販売データ、生産データ、在庫データが別々のシステムに散在し、統合されていない。データの欠損、粒度(日次・週次・月次)の不一致、外れ値などが多く、そのままでは分析に使えない。
- 内示と確定注文のズレ: 顧客からの内示情報に振り回され、どの程度の重みで生産計画に反映すべきか基準が曖昧。
- 部門間の連携不足: 営業、生産、購買、品質保証、保全といった各部門がサイロ化し、情報共有がスムーズに行われていない。営業が見込む需要と、生産現場のキャパシティに乖離が生じやすい。
これらの課題は、AIという「賢いエンジン」を導入する前に解決、あるいは考慮しておくべき「土台」の部分に関わる問題です。
生産管理の全体像とAIが担う役割
AIは魔法の杖ではありません。生産管理の各プロセスにおいて、明確な役割を持って価値を発揮します。まずは全体像を俯瞰してみましょう。
- 需要予測: 全ての起点。販売実績や外部要因から将来の需要を「予測」する。
- S&OP/IBP(需給調整会議): 予測を元に、販売計画と生産能力のバランスを取り、経営計画と整合させる意思決定プロセス。AIは複数シナリオのシミュレーションを支援する。
- 生産計画/スケジューリング: 需要計画と制約条件(設備、人員、納期)を元に、いつ・何を・どれだけ・どの設備で生産するかの詳細計画を「最適化」する。
- 要員計画: 生産計画に基づき、必要な人員数とスキルを割り当てる計画を「最適化」する。
- 購買・在庫最適化: 生産計画と部品リードタイムを元に、最適な発注タイミングと量を計算し、在庫レベルを「最適化」する。
- 製造実行(MES): 計画を実行し、実績データを収集する。
- 品質管理: カメラ画像から不良品を「認識」したり、センサーデータからプロセスの異常を「検知」したりする。
- 予知保全(CBM): 設備センサーデータから故障の予兆を「検知」し、計画的なメンテナンスを促す。
- 安全監視: カメラ映像から危険行動や立入禁止エリアへの侵入を「認識」し、警告を発する。
このように、AIは主に「予測」「最適化」「認識」「異常検知」という4つの能力で、生産管理の各プロセスを高度化し、データでつなぐ役割を担います。
実践ガイド:PoCから本番運用まで、失敗しない6ステップ
理論を理解したところで、いよいよ実践です。ここでは、多くの現場で再現性が高く、着実に成果を出すための進め方を6つのステップに分けて具体的に解説します。
ステップ1:課題定義とKPI設定(目的地の明確化)
最も重要なステップです。ここが曖昧だとプロジェクトは必ず迷走します。
- 目的を具体的にする: 「AIを導入したい」ではなく、「何を解決したいのか」を明確にします。
- 例:「主力製品Aの欠品率を現状の5%から2%未満に低減する」「生産計画の作成にかかる時間を週10時間から2時間以内に短縮する」「設備Bの計画外停止時間を年間50%削減する」
- スコープ(範囲)を限定する: 最初から全製品・全工場を対象にするのは無謀です。
- 例:まずは最重要SKU(製品)20品目に絞る。特定の生産ラインや工場から始める。過去1年分のデータを対象とする。
- 成果指標(KPI)を定義する: 成功・失敗を客観的に判断するための物差しを決めます。
| 領域 | 主要KPI | 定義/計算式 | データソース |
|---|---|---|---|
| 需要予測 | 予測誤差率 (MAPEなど) | |実績 - 予測| / 実績 の平均 | 販売実績データ |
| 欠品率 | 欠品発生日数 / 全営業日数 | 受注・在庫データ | |
| 在庫回転率 | 売上原価 / 平均在庫金額 | 販売・在庫データ | |
| スケジューリング | 納期遵守率 | 納期内に完了したオーダー数 / 全オーダー数 | 生産実績データ |
| 段取り回数/時間 | 一定期間内の段取り総回数/総時間 | 生産実績データ | |
| 設備総合効率 (OEE) | 可動率 × 性能 × 良品率 | 設備稼働データ | |
| 品質管理 | 不良品検出率 | AIが検出した不良品数 / 実際の不良品総数 | 検査ログ |
| 過検出率 | AIが不良と誤判定した良品数 / 良品総数 | 検査ログ | |
| 予知保全 | 計画外停止時間 | 突発的な故障による停止時間の合計 | 設備稼働データ |
| 平均故障間隔 (MTBF) | 総稼働時間 / 故障回数 | 設備稼働・保全ログ |
ポイント: KPIは必ず「現状(As-Is)」の数値を計測し、ベースラインとして記録しておきます。これにより、導入後の効果(To-Be)を定量的に証明できます。
ステップ2:データ棚卸しと品質評価(“燃料”の確認)
AIモデルの性能は、学習させるデータの質と量で9割決まります。社内に眠るデータを洗い出し、使える状態かを確認しましょう。
- 内部データの洗い出し:
- 販売系: 販売・出荷実績、在庫履歴、受注情報(内示/確定)、価格・プロモーション履歴
- 生産系: 生産実績、設備稼働ログ、段取り履歴、人員シフト表、作業者スキルマップ
- 購買系: 発注履歴、サプライヤーからの納期、入荷遅延実績
- 品質系: 品質検査ログ、不良品の画像データ、センサーデータ(温度、圧力など)
- 保全系: 設備保全履歴(故障内容、修理部品、作業時間)、センサーデータ(振動、電流など)
- 外部データの収集:
- カレンダー情報(祝祭日、連休)、天候データ、地域のイベント情報、Web検索トレンド(例: Google Trends)、SNSの投稿量、競合の価格情報など。
- データ品質のチェック:
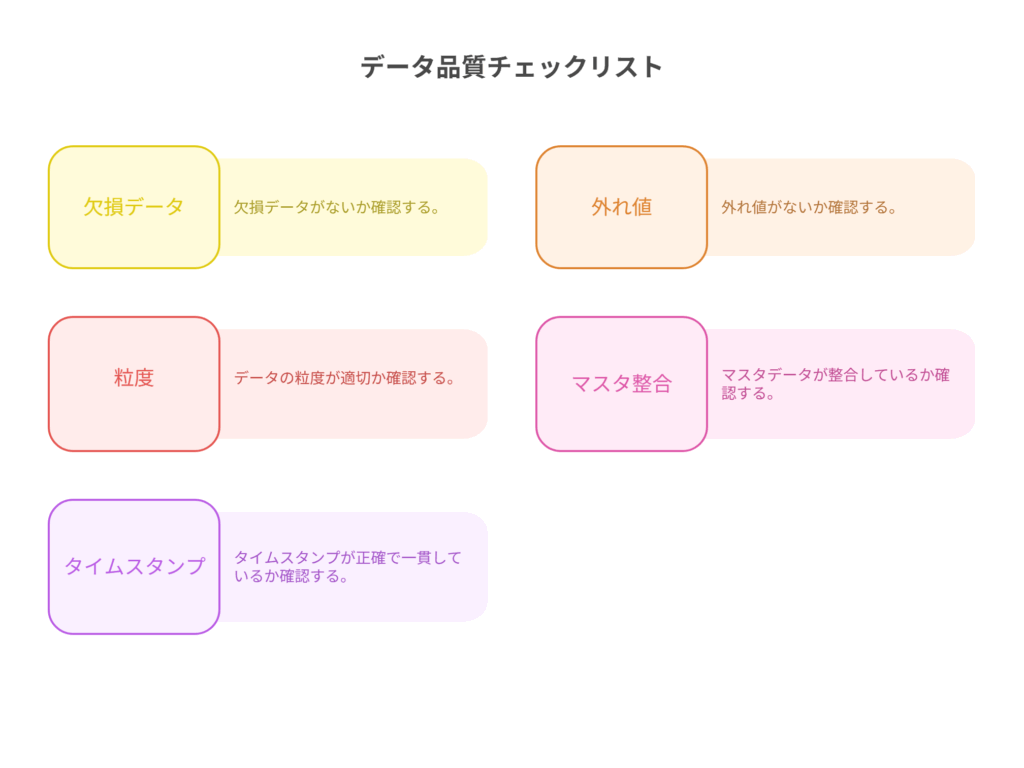
- [ ] 欠損: データに抜け漏れはないか?(例: 特定の期間の販売データがごっそり抜けている)
- [ ] 外れ値: 明らかに異常な値は含まれていないか?(例: 在庫数がマイナスになっている)
- [ ] 粒度: データの時間単位(日次、週次、月次)や集計単位(製品別、店舗別)は分析目的に合っているか?
- [ ] マスタ整合: 製品コードや拠点コードが複数のシステムで統一されているか?(表記ゆれはないか?)
- [ ] タイムスタンプ: 全てのデータに正確な日時情報が付与されているか?
ポイント: 最初から完璧なデータが揃っていることは稀です。「今あるデータで何ができるか」から始め、価値が見えてからデータ整備に投資するという考え方が現実的です。
ステップ3:特徴量設計とモデル方針(AIの“脳”の設計図)
収集した生データを、AIが学習しやすい形(特徴量)に加工する工程です。ここでの工夫が予測精度を大きく左右します。
- 需要予測モデル向けの特徴量:
- 時系列特徴: 過去の売上実績そのもの、移動平均、季節性(昨年同週の実績など)、曜日や月末月初といった周期性。
- カレンダー特徴: 祝日、連休、給料日などをフラグで表現。
- イベント特徴: セールやキャンペーン期間、新製品発売日などをフラグで表現。
- 外部要因: 気温、降水量、Web検索ボリューム、SNS投稿数など。
- スケジューリングモデル向けの設定:
- 制約条件の定義: 納期、段取り時間(製品AからBへの切り替えにかかる時間)、設備ごとの生産能力、休日カレンダー、人員のスキルセット、ロットサイズなどを厳密に定義する。
- 目的関数の設定: 何を最も重視するかを決めます。「納期遅延ペナルティを最小化する」「段取り回数を最小化する」「生産コストを最小化する」などを組み合わせます。
- 品質・保全モデル向けの特徴量:
- 画像検査: 画像データから、傷、汚れ、変形などの特徴をAIが自動で学習する。事前に良品・不良品のラベル付けが必要。
- 異常検知: センサーデータから、通常とは異なるパターン(振動の急増や温度の異常上昇など)を捉えるための統計的特徴量を計算する。
ポイント: 必ずしも最先端の複雑なAIモデルが最良とは限りません。最初はシンプルな統計モデル(ARIMAなど)から始め、機械学習モデル(LightGBM, Prophetなど)と比較検討するなど、課題とデータの特性に合わせて堅実な手法を選ぶことが重要です。
ステップ4:PoC(実証実験)設計と評価計画(小さく試す)
いよいよAIモデルを構築し、その実力を試します。本番導入の前に、限定的な環境で効果とリスクを検証するのがPoCです。
- 期間と範囲の設定: 影響範囲が限定的で、かつ効果が分かりやすい対象を選びます。季節性のある製品なら、最低でもその季節を含む数ヶ月から1年程度の期間で検証することが望ましいです。
- 検証方法の設計:
- バックテスト: 過去のデータを使って、「もしあの時点でこの予測モデルがあったら、どれだけ実績と近かったか」を検証します。
- 並行運用(A/Bテスト): 従来のやり方(A)と、AIを使った新しいやり方(B)を一定期間並行で動かし、KPIを比較します。これが最も説得力のある検証方法です。
- 評価指標の計測: ステップ1で定めたKPIを、PoC期間中の実績値と、AI導入前のベースライン値とで比較評価します。なぜ差が出たのか、変動要因(市場の変化など)も考慮して分析します。
- リスク管理(HITLの導入): PoCの段階から、AIの予測や計画を鵜呑みにしない運用を徹底します。
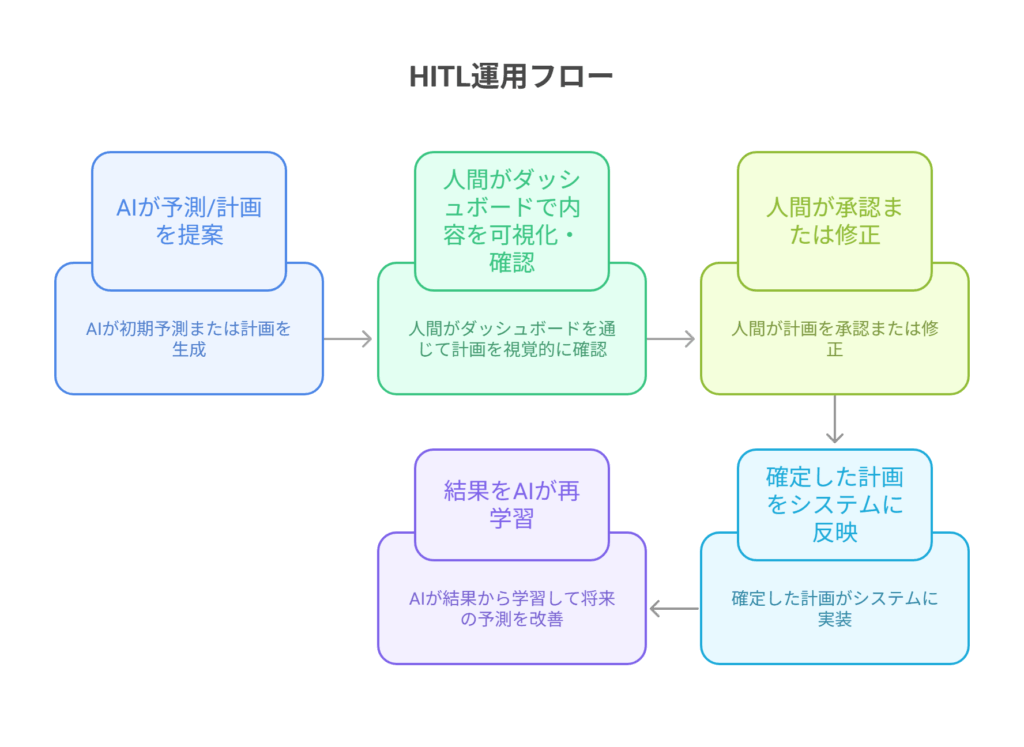
ポイント: PoCの成否は、単なる予測誤差の数値だけで判断してはいけません。「現場担当者がその結果を信頼し、日々の業務で使えるか」「運用に乗せやすいか」といった定性的な評価も非常に重要です。
ステップ5:業務連携とシステム設計(本番への橋渡し)
PoCで良い結果が出たら、いよいよ本番運用に向けた設計に入ります。
- システム連携の設計:
- 既存の基幹システム(ERP)、生産管理システム(MES)、倉庫管理システム(WMS)などと、どうデータを連携させるかを決めます。(API連携、ファイル連携など)
- データの流れを自動化し、手作業でのデータ入力を極力なくす設計を目指します。
- 運用フローの設計:
- 更新頻度: 需要予測は日次で更新、生産計画は週次で見直し、スケジューリングは日次で再計算、といった具体的な運用サイクルを定義します。
- 可視化とアラート: 予測結果や計画、異常検知の結果を誰にでも分かりやすく表示するダッシュボードを設計します。欠品リスクや設備異常の予兆など、対応が必要な項目はアラートで通知する仕組みを作ります。
- モデルのメンテナンス: AIモデルは市場の変化などで性能が劣化(ドリフト)することがあります。定期的に精度を監視し、必要に応じて再学習させる運用を計画に含めます。
ポイント: AIの提案に対し、現場担当者が確認・承認・差し戻しといったアクションを簡単に行えるインターフェースが普及の鍵です。「AIに仕事を奪われる」のではなく「AIを使いこなす」という意識を醸成する仕掛けが重要になります。
ステップ6:教育・展開・継続的改善(育てていく文化)
システムを導入して終わりではありません。組織全体で活用し、さらに良くしていくサイクルを回します。
- ユーザー教育: 現場担当者向けに、AIの基本的な仕組み、限界(何ができて何ができないか)、ダッシュボードの見方、そして最も重要な「正確なデータ入力の重要性」について研修を行います。
- 改善サイクルの確立: 月に一度などの定例会で、KPIの達成状況とAIの予測・計画結果を関係者(営業、生産、購買など)でレビューします。予測が外れた原因を分析し、新しい特徴量の追加や、制約条件の見直しといった改善アクションにつなげます。
- 段階的な横展開: PoCで成功したモデルケースを元に、対象となる製品群、ライン、工場へと段階的に展開していきます。また、需要予測から始め、次にスケジューリング、品質管理へと、ユースケースを拡張していくことも有効です。
ポイント: 「スモールスタート+短サイクルでの改善」の積み重ねこそが、最終的に大きな改革へとつながる最も確実な道筋です。トップダウンの号令だけでなく、現場が主役となって改善を回す文化を育てることが、持続的な成功の鍵となります。
ユースケース別の実装詳細
ここでは、代表的な5つのユースケースについて、実装時のより具体的なポイントを掘り下げます。
1. 需要予測と在庫最適化
- データ統合の要点: 販売実績、在庫履歴はもちろん、価格変更や特売といったプロモーション情報を必ず紐付けます。内示と確定受注は別データとして扱い、それぞれの傾向を学習させます。天候やイベントなどの外部データも統合し、多角的な分析を可能にします。
- 設計のコツ:
- 予測の粒度: 予測の単位(SKU×店舗×日、など)は、在庫補充や生産指示といった「次のアクション」の単位に合わせることが重要です。
- 価格弾力性の考慮: 価格を下げた時にどれだけ需要が伸びるか(価格弾力性)をモデルに組み込むことで、販促施策の効果をシミュレーションできます。
- 動的な安全在庫: 従来は固定値だった安全在庫を、AIが予測する需要の「ばらつき(予測誤差)」と調達リードタイムの変動に応じて動的に計算し、サービスレベル(欠品許容率)を維持しながら在庫量を最適化します。
- 失敗回避のヒント:
- 内示情報を鵜呑みにせず、顧客ごとの「内示から確定への変化率」や「リードタイムの傾向」を学習データに加えることで、より現実的な予測が可能になります。
- SNSでのバズなど突発的な需要急増に備え、Web検索数やSNS投稿数の急増を検知するアラートを設定し、早期に対応できる仕組みを検討します。
2. 生産スケジューリング最適化
- 制約モデリングの重要性: ここがスケジューラ導入の肝です。段取り時間(色替え、型替えなど)、納期、設備ごとの稼働カレンダー、メンテナンス計画、作業員のスキルとシフト、製品ごとのロットサイズやバッチ処理の制約などを、いかに正確にデジタルデータとして表現できるかが精度を決めます。
- 運用イメージ:
- これまで熟練者が丸一日かけて作成していた週間計画を、AIが数分で複数パターン提案します。
- 急な特急オーダーや設備故障が発生した際に、影響を最小限に抑えるリスケジュール案を即座に計算し、関係者に提示します。
- 現場適合のコツ:
- 結果をガントチャートや設備の負荷状況ヒートマップで視覚的に表示し、なぜそのスケジュールになったのか(例: 納期優先のため、段取りが増えている)を人間が直感的に理解できるようにすることが、現場での信頼獲得につながります。
3. 品質管理(画像認識 × プロセス異常検知)
- 画像検査のポイント:
- 学習データの質: AIの性能は学習データの質に大きく依存します。様々なパターンの良品と不良品の画像をバランス良く用意することが重要です。特に、「見逃し」を防ぐために、微妙な欠陥や稀な不良パターンのデータを重点的に集める必要があります。照明やカメラの角度といった撮像条件を標準化することも精度向上に不可欠です。
- 運用: 100%の精度は困難なため、検出率(不良品を見逃さない割合)と過検出率(良品を不良と誤判定する割合)のバランスを、製品の重要度に応じて調整します。AIが判断に迷ったものだけを人間がチェックする、という協調的な運用が現実的です。
- プロセス異常検知:
- 製造工程中の温度、圧力、流量といったセンサーデータをリアルタイムで監視し、過去の正常なデータパターンから逸脱した際にアラートを発します。これにより、製品が不良になる前に、プロセスの異常を捉えて対処することが可能になります。
4. 予知保全(CBM: 状態基準保全)
- 必要なデータ: 設備の正常時と異常時の両方を含む、振動、温度、音響、電流、圧力といったセンサーデータと、過去の保全履歴(いつ、どこが、なぜ故障し、どう修理したか)の組み合わせが基本となります。
- 導入の流れ: センサーデータから「いつもと違う」兆候を捉えるための特徴量を設計し、異常スコアを計算します。スコアが閾値を超えたら保全担当者にアラートを送り、点検や部品交換を促します。
- もたらす効果: 「壊れてから直す(事後保全)」や「定期的に交換する(時間基準保全)」から、「壊れそうになったら直す(予知保全)」への転換を実現します。これにより、計画外のライン停止を抑制し、まだ使える部品を交換する無駄をなくし、保全コストを最適化できます。
5. 安全監視
- 具体的なユースケース: 工場内に設置したカメラ映像をAIが解析し、ヘルメット未着用などの危険行動を検知したり、危険な機械が稼働中に人が立入禁止エリアに侵入した際に警告を発したりします。
- 運用のポイント: 誤検知が頻発すると現場の信頼を失うため、チューニングが重要です。また、従業員のプライバシーへの配慮も不可欠であり、導入目的やデータの扱いについて事前に十分な説明と合意形成が求められます。事故発生時の原因究明や、再発防止策の検討にも映像記録を活用できます。
ツール選定とアーキテクチャ:何をどう組み合わせるか
自社に最適なAIソリューションを導入するためには、どのような基準でツールを選び、システムを組み合わせればよいのでしょうか。
選定の7つの基準
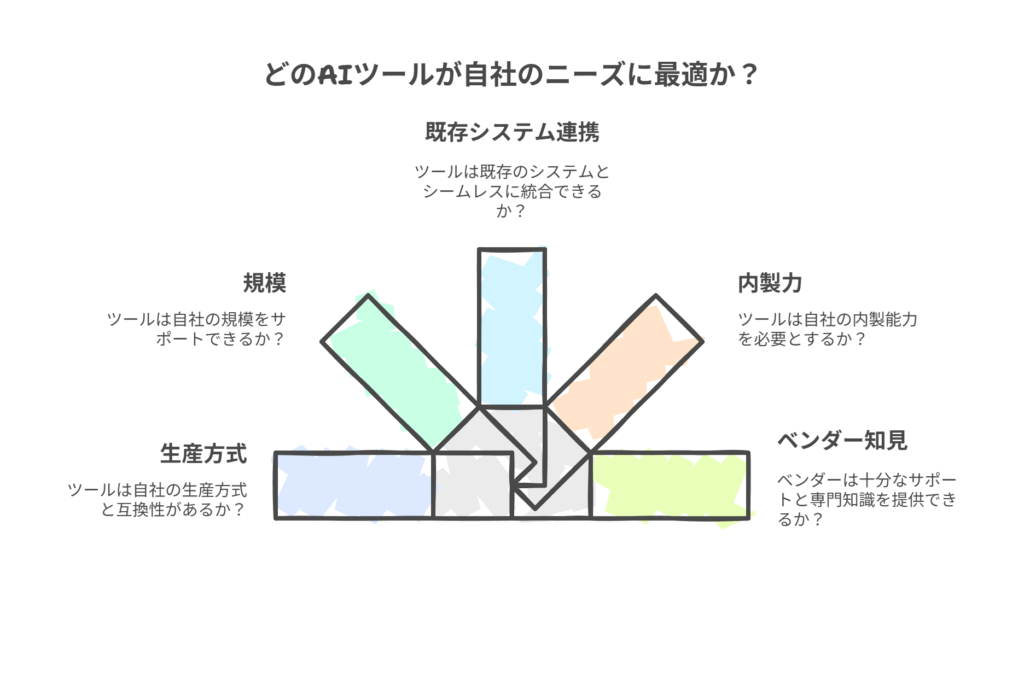
- 生産方式・業態への適合性: ライン生産か、ロット生産か、個別受注生産か。自社の生産方式特有の制約(例: 食品業界の賞味期限管理)に対応できるかが重要です。
- 事業規模との整合性: 対象とするSKU数、拠点数、設備数、利用ユーザー数に応じた拡張性があるか。スモールスタートから全社展開まで柔軟に対応できるライセンス体系か。
- 既存システムとの連携性: 現在使用しているERP、MES、WMSなどとスムーズにデータ連携できるか。標準的なAPIが提供されているか、連携実績は豊富か。
- 運用体制と内製力: 自社にデータサイエンティストなどの専門家がいるか。いない場合は、現場担当者でも直感的に操作できるノーコード/ローコードのツールが適しています。
- ベンダーのドメイン知見: ツールの機能だけでなく、ベンダーが製造業の業務プロセスや現場の課題をどれだけ深く理解しているかが、導入支援の質を大きく左右します。
- 立ち上げの容易性: 無料トライアルや、短期間で効果を検証できるPoC支援プログラムがあるか。業界別のテンプレートが充実しているか。
- セキュリティとガバナンス: クラウドサービスを利用する場合、データ管理ポリシーやアクセス権限設定、監査ログ機能などが自社のセキュリティ基準を満たしているか。
現実的な組み合わせ例(目的別)
- まずは需要予測から始めたい: 既存の販売管理システムや在庫管理システムはそのままに、クラウドベースの「需要予測SaaS」をAPIで連携する。初期投資を抑え、素早く在庫補充精度の改善効果を狙えます。
- 生産計画の作成を効率化したい: 既存のMESと連携可能な「生産スケジューリング最適化ツール」を導入。現場の複雑な制約条件をデジタル化し、計画立案と急な変更対応を自動化・高速化します。
- 品質検査の自動化が急務: 検査装置メーカーが提供する「画像検査特化型AIソフトウェア」を導入。検査の標準化と人手不足解消に直結します。
- 設備の安定稼働が最優先: 設備のセンサーデータを収集・分析する「予知保全プラットフォーム」を導入。クラウド上で高度な分析を行い、故障の予兆を現場に通知します。
シナリオ別ガイダンス:あなたの現場に合わせた考え方
業種や企業の状況によって、AI活用の勘所は異なります。
- 食品業界など、季節変動が大きい場合:
- 気温、湿度、連休、地域のイベントといった外部要因を予測モデルに強く反映させることが重要です。需要のピークを早期に捉え、前倒しでの生産計画や、地域ごとの在庫配分最適化につなげます。
- 化学・素材などのプロセス産業の場合:
- ロットやバッチ単位での生産、製品切り替え時の洗浄時間といった特有の制約を厳密にモデル化する必要があります。また、製造プロセス中のセンサーデータをリアルタイムで監視し、品質の異常を検知するオンライン監視が有効です。
- 組立加工業など、多品種少量生産の場合:
- 膨大な数の部品と工程を管理し、個別の納期を守ることが最優先されます。納期遅延のペナルティと、段取り時間を最小化することのバランスを取る最適化が求められます。作業員のスキルマップを制約条件に加え、急な欠勤者が出た際の最適な人員再配置を自動計算することも可能です。
- Excel管理が中心の中小規模の製造業の場合:
- まずは最も管理が煩雑で効果が出やすい「需要予測と在庫最適化」から始めるのが定石です。クラウドSaaSを利用すれば、初期投資を抑えつつ週次で効果を見える化できます。そこで成功体験とノウハウを蓄積し、次にスケジューラへと拡張していくのが現実的なステップです。
- 設備の老朽化が進み、突発停止に悩んでいる場合:
- 大規模なシステム改修は不要です。後付け可能な振動センサーや電流センサーを主要設備に取り付けることから始められます。まずは停止直前のデータパターンを「見える化」するだけでも、点検タイミングの改善につながります。
よくある落とし穴と回避策
多くの企業がAI導入でつまずくポイントは共通しています。先人の失敗から学び、賢く回避しましょう。
- 【落とし穴1】データが完璧に整うまで待ってしまう。
- 回避策: 「完璧主義」は禁物です。現状あるデータでPoCを開始し、「このデータが足りないから予測精度が上がらない」といった仮説を立てます。価値が見えて初めて、不足データを整備するための投資判断をすればよいのです。
- 【落とし穴2】予測誤差がゼロにならないと現場で使えない、と考えてしまう。
- 回避策: AIの予測は100%当たるものではありません。目標は誤差ゼロではなく、欠品率の低減や在庫の削減といった「ビジネスKPIの改善」です。AIの予測を「参考情報」として人間が最終判断する運用(HITL)を徹底しましょう。
- 【落とし穴3】現場に「AIが勝手に決める」という誤解や抵抗感が生まれる。
- 回避策: 導入の初期段階から現場のキーパーソンを巻き込み、AIはあくまで「優秀なアシスタント」であると説明します。AIが提案した計画の「根拠」を可視化し、現場の知見で修正できる仕組みを用意することで、信頼関係を築きます。
- 【落とし穴4】PoCをやってみたものの、効果測定だけで終わってしまう(PoC死)。
- 回避策: PoCを計画する段階で、本番運用時のシステム連携や業務フローを並行して設計します。「PoCが成功したら、次はこのステップに進む」というロードマップを事前に合意しておくことが重要です。
- 【落とし穴5】システム開発をベンダーに丸投げしてしまう。
- 回避策: AIプロジェクトは、業務知識を持つ現場担当者が主役です。現場、IT部門、品質保証、保全といった関係部署が一体となったチームを組成し、ベンダーと協働で進める体制が不可欠です。自社内にノウハウを蓄積する意識を持ちましょう。
FAQ(よくある質問)
Q1. AIモデルの学習には、どのくらいの期間のデータが必要ですか?
A1. 季節性やトレンドを捉えるためには、少なくとも1〜2年分、理想的には3年分以上のデータがあると安定したモデルを構築しやすくなります。しかし、データが少なくても、シンプルなモデルから始めたり、類似製品のデータを活用したりする方法もあります。まずは今あるデータで試してみることが重要です。
Q2. 顧客からの内示情報はどのように扱えば良いですか?
A2. 内示は重要な先行情報ですが、確度が変動します。顧客ごと、製品ごとに「内示から確定までの変化率」や「変更が入るタイミング」の傾向を過去データから学習させ、予測モデルに重み付けして反映させます。内示の確度をスコアリングするのも有効なアプローチです。
Q3. SNSでのバズや天候異常など、突然の需要急変に対応できますか?
A3. 対応の感度を高めることは可能です。Webの検索トレンド、SNSの投稿量、気象警報といった外部データをリアルタイムに近い頻度でモデルに取り込み、予測の更新頻度を上げる(週次→日次など)ことで、急変の兆候を早期に捉えることができます。ただし、最終的な判断は人の介入(HITL)が不可欠です。
Q4. 中小企業でIT専門家がいなくても導入できますか?
A4. 可能です。近年は、プログラミング不要で直感的に操作できるノーコード/ローコードのAIプラットフォームや、特定の用途に特化した安価なクラウドサービス(SaaS)が増えています。既存システムとの連携を最小限にしてスモールスタートできるため、導入のハードルは格段に下がっています。
Q5. 最初に注目すべきKPIは何ですか?
A5. 目的によりますが、代表的なものとして、需要予測なら「予測誤差率」とビジネスインパクトとしての「欠品率」「在庫回転率」です。生産計画なら「納期遵守率」と「段取り回数」。品質管理なら「不良品検出率」。予知保全なら「計画外停止時間」です。まずは最も改善したい課題に直結するKPIを1〜2個に絞って注視しましょう。
Q6. セキュリティやデータガバナンスはどのように考えれば良いですか?
A6. クラウドサービスを利用する場合は、その事業者がどのようなセキュリティ認証(ISO27001など)を取得しているかを確認します。社内では、誰がどのデータにアクセスできるかの権限管理、AIによる判断の履歴(監査ログ)の保存、個人情報の取り扱いといったルールを明文化し、運用することが重要です。
Q7. 多くの企業は、どこから始めるのが最も成功しやすいですか?
A7. 比較的にデータが整っていることが多い「販売・在庫データ」を活用した「需要予測→在庫最適化」のテーマから始めるのが最も成功しやすく、効果を実感しやすい王道パターンです。ここで得られた予測結果は、次のステップである生産スケジューリングのインプットとして活用できるため、拡張性も高いです。
Q8. 導入の可否を判断するための最終的なポイントは何ですか?
A8. 最終的には「投資対効果(ROI)」で判断します。PoCを通じて、「AI導入によって削減できるコスト(在庫削減額、残業代、機会損失額など)」と「導入・運用にかかるコスト」を定量的に試算します。その上で、データ品質、システム連携の実現性、現場の協力体制といった定性的な要素も加味し、段階的な導入計画を経営層に提案・合意形成することが成功の鍵です。
まとめ:小さく始め、速く学び、全体最適へつなげる
本記事では、AI需要予測を起点として、生産管理のDXを実現するための実践的なロードマップを解説してきました。最後に、成功への道をもう一度確認しましょう。
- 全ての起点は需要予測: 勘とExcelから脱却し、多様な要因を学習するAI予測が、在庫、欠品、生産平準化といった長年の課題を解決する突破口となります。
- 成功の土台はデータ基盤: 分断されたデータを統合し、品質を担保する地道な取り組みが、AIの性能を最大限に引き出します。
- スパイラルアップで進化する: PoCで小さく始め、KPIで効果を測定し、短いサイクルで改善を繰り返す。このアジャイルなアプローチが、現場の納得感を生み、着実な成果につながります。
- 人とAIの協調が鍵: AIは万能の魔法ではありません。AIの提案を人間が最終判断する「ヒューマン・イン・ザ・ループ(HITL)」の思想でリスクを管理し、AIを「賢い道具」として使いこなすことが重要です。
- 全体最適への拡張: 需要予測からスケジューリング、品質、予知保全、安全へとAIの活用範囲を広げることで、部門最適の壁を越え、工場全体の生産性(OEE)と収益性を向上させることができます。
データとAIを味方につけることで、変動の激しい現代市場でもしなやかに対応できる、強く、スマートな生産管理体制を構築することは、もはや夢物語ではありません。
あなたが明日から取るべき、次の一歩
- 現状診断シートの作成: 本記事のKPIリストを参考に、自社の主要製品の「欠品率」「在庫日数」「納期遵守率」などの現状値を洗い出し、関連するデータがどこに、どのような形式で存在するかを1枚のシートにまとめましょう。
- テーマの選定: そのシートを眺め、最も改善インパクトが大きく、かつデータが比較的揃っていそうなテーマを1つに絞り込みます。(例: 「製品Aの在庫最適化」)
- ミニPoC計画の立案: 選んだテーマについて、範囲、期間、評価指標、そして誰と協力するかを定めた簡単なPoC計画書を作成し、上司や関係部署に相談してみましょう。
この小さな一歩が、あなたの会社の生産管理を未来へと進める大きな推進力となるはずです。
